


TL;DR
Legacy Rails functions may be unpredictable, so by no means assume something about their conduct. Step one to stability is enhancing observability—perceive how the system behaves earlier than making adjustments. Establish bottlenecks utilizing actual knowledge, optimize important configurations, and guarantee quick deployment rollback in case one thing goes unsuitable. Even small changes, like tuning concurrency settings, can have a major affect on system reliability.
Cry for assist
At some point we obtained a request to assist with an unstable Rails software in our inbox.
They had been experiencing frequent outages or slowdowns, and so they weren’t capable of determine the foundation trigger.
That they had monitoring and alerting applied utilizing a third-party service. It made the issue evident.
The affected person and the signs
The appliance was a B2B e-commerce platform. It was constructed of three major parts:
- Public-facing web site – a Rails software
- A legacy ERP system – a black field
- A middleware liable for communication between the 2 – one other Rails software
There was no observability, nor centralized logging applied.
The appliance was deployed on AWS EC2 cases. The deployment course of was automated utilizing Ansible and a custom-built
Rails software to run the deployment playbooks. Nevertheless, the deployment software had no rollback function.
In case of a failure, they needed to revert the adjustments, anticipate CI exams, after which run the deployment once more.
Each Rails functions had been operating on the identical cases. There was no separation between them.
It was unattainable to find out which software was consuming extra server sources, besides by real-time system monitoring instruments like htop.
There have been two software servers, every operating the identical set of functions. Moreover, there have been two load balancers
(Haproxy)—one going through the general public web site, the opposite going through the middleware.
The scenario was so unhealthy that they needed to restart cases manually to get well from outages.
The preliminary steps
We began by including NewRelic instrumentation to the Rails functions. We additionally needed NewRelic infra brokers
put in on the servers. Because the infrastructure was managed with Ansible, we prolonged present Ansible roles
and playbooks to put in the brokers.
The investigation – first spherical
The primary main discovering was an infinite loop within the public-facing web site.
We recognized it utilizing NewRelic’s profiling function. Throughout one of many outages, we took a profiling session
and analyzed it fastidiously.
The infinite loop was attributable to a change within the ERP system’s API that was not mirrored within the Rails software code.
After we pointed it out, the consumer workforce was capable of repair it rapidly. Sadly, that was not the one situation.
The defective code was in a hardly ever used space of the appliance.
Subsequent, we analyzed APM traces throughout outages, searching for patterns. We discovered that the public-facing software
skilled important will increase in response time resulting from ready for exterior net calls.
Nevertheless, the middleware’s response time improve was a lot smaller.
We requested the consumer workforce in the event that they noticed the identical sample within the ERP system. They didn’t.
One thing was off, however we didn’t know what but. We began specializing in the middleware.
Throughout one of many outages, we observed (utilizing htop on the appliance server) that every one threads within the middleware course of
had been totally utilized. After we in contrast concurrency configurations between the middleware and the public-facing app,
we discovered a major distinction:
- Public app: 4 employees, 5 threads per employee, on every of two cases
- Middleware: 1 employee, 5 threads per employee, on every of two cases
As a fast repair, we elevated the variety of middleware employees to 2.
We additionally added the X-Request-Begin HTTP header to Haproxy configurations to trace request queuing in NewRelic.
The change considerably decreased the frequency of outages, however the issue wasn’t totally solved.
Our speculation was that the middleware couldn’t deal with the load from the general public app. We would have liked to show it.
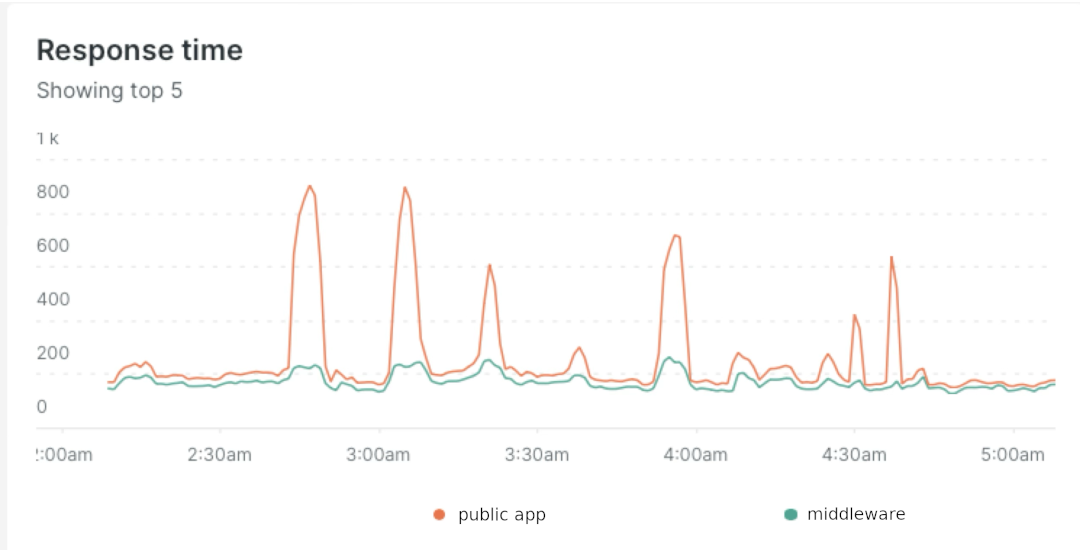
We additionally began monitoring middleware request queuing in NewRelic throughout outages.
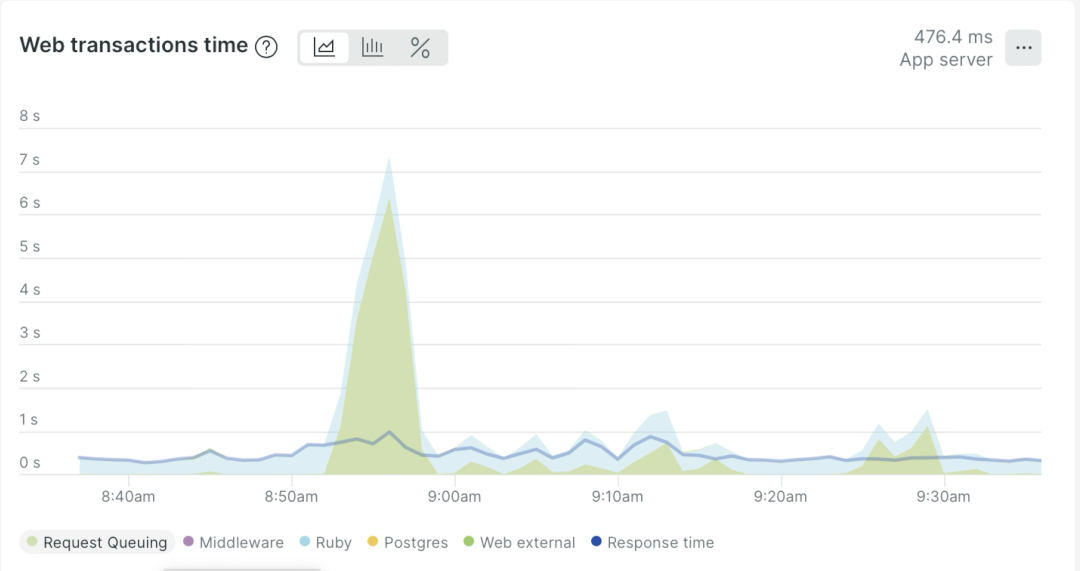
The investigation was paused as a result of the agreed finances had been exhausted.
The investigation – second spherical
After a couple of months, the consumer workforce contacted us once more.
We had already began a Ruby and Rails improve undertaking for the general public app, and so they additionally requested us to analyze
the steadiness points additional.
This time, we had been higher ready.
By way of the improve undertaking, we had gathered extra information in regards to the software and its relationship with
the middleware and ERP system.
From the primary spherical of investigation, we had a powerful speculation that the middleware was the bottleneck.
We added full middleware logging to NewRelic and began analyzing the logs.
We found that the middleware’s throughput was an order of magnitude larger than that of the general public app.
It turned out that the middleware wasn’t solely utilized by the public-facing software—it additionally dealt with site visitors
from inside functions, considerably rising its load.
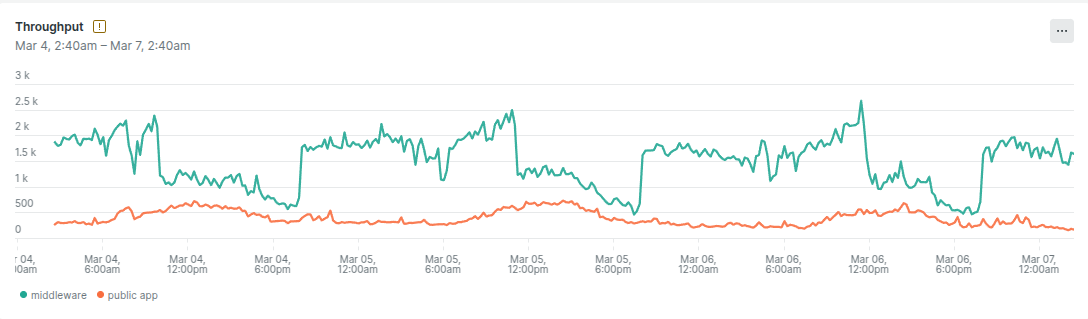
To substantiate our idea, we tried to set off public app outages by artificially rising the load on the middleware.
It labored: larger middleware load resulted in public app outages.
This strengthened our speculation that the middleware’s concurrency configuration was suboptimal.
Finest practices for configuring Puma concurrency
Puma is the default Rails software server. It makes use of a multi-process, multi-threaded mannequin.
For a very long time, the default Puma configuration in Rails set the variety of threads per employee to five. Just lately,
DHH recommended reducing it.
After an attention-grabbing dialogue, the default has been modified to three threads per employee since Rails 7.2.
There may be additionally a rule of thumb from Nate Berkopec,
a Rails efficiency knowledgeable and Puma committer:
The optimum quantity is at all times 1 Puma employee course of per 1 CPU core. Then, tune the thread rely in order that the CPU core
is well-utilized at most load.
Following Nate’s recommendation, we determined to not improve the variety of employees however as an alternative regulate the variety of threads.
We had been hesitant to make use of a excessive thread rely because of the (in)well-known
GVL,
which makes Ruby threads much less environment friendly than native threads.
At this level, we began to suppose exterior the field. Is our middleware Rails software just like the everyday
Rails functions that the default settings had been designed for? How totally different is it?
Let’s examine the net transaction breakdown of our middleware software:

With that of one other Rails software we’ve labored with:
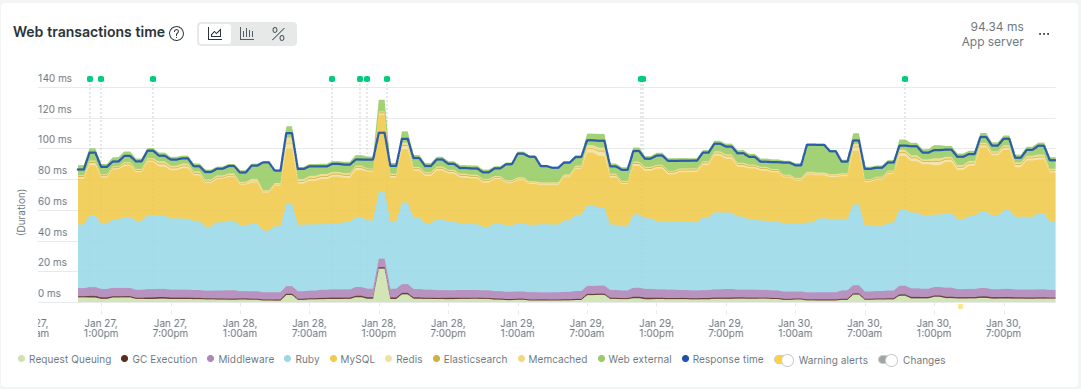
Do you see the distinction? Our middleware app is generally dealing with exterior requests, which suggests it’s I/O-bound.
I/O-bound workloads profit from larger thread counts as a result of threads spend most of their time ready for I/O.
Since Ruby releases the GVL when ready for I/O, threads may be utilized extra effectively on this state of affairs.
The answer – tuning Puma concurrency settings
To make sure a secure, incremental rollout, we adjusted Ansible deployment roles to assist totally different Puma configurations
for every software server. We additionally needed to tune haproxy configuration and introduce weighting based mostly on the entire
threads rely configured on every server. This allowed us to check totally different configurations progressively.
We had been deploying adjustments on one server at a time, monitoring the system intently.
In the meantime, we additionally investigated how you can implement a quick rollback mechanism.
The unique deployment rollback course of took half-hour, requiring a full redeployment.
We discovered a method to carry out an Ansible-based rollback with out utilizing the {custom} deployment software.
This decreased rollback time to only 3 minutes.
We’ve by no means needed to rollback puma configuration adjustments, but it surely was good to have the choice. It was very useful
in course of our upgrades undertaking, however that’s a narrative for an additional time.
By way of testing, we recognized optimum Puma settings:
- Middleware: 3 employees, 20 threads
- Public app: 3 employees, 9 threads
Lastly, we repeated our public app outage check.
With the unique middleware configuration, excessive load induced the general public app to crash.
With the brand new configuration, the system remained steady. We carried out each exams utilizing ab benchmarking device with
the very same parameters. See the outcomes under:

Variety of database connections
Earlier than deploying the adjustments to each software servers, we additionally checked the variety of database connections.
It turned out that, with the brand new settings, we might be very near the database connection restrict.
However wait—doesn’t this software behave uniquely in that regard? Have you ever observed how slender the yellow space is
within the middleware app breakdown chart?
After a fast investigation, we found that the middleware app was utilizing the database just for authentication
and authorization. We verified that it was secure to launch the database connection again to the pool
instantly after authentication and authorization.
authorize! :carry out, @job
ActiveRecord::Base.connection_pool.release_connection
# the next takes quite a lot of time
render json: @job.carry out
This allowed us to considerably scale back the variety of database connections utilized by the middleware app.
Every software course of, configured with 20 threads, now used solely 2 database connections.
Ultimate ideas
The soundness of the system improved considerably after the adjustments. The consumer workforce was proud of the outcomes.
There may be loads of room for additional enhancements. It could be helpful to interrupt the general public app dependency
on the middleware on every request. Caching and eventual consistency patterns could possibly be used to attain this.