


{kind=link}

Possibly you’ve heard complicated-sounding phrases similar to ‘“College students t-test”, “regression fashions”, “help vector machines”, and so forth. You may suppose there’s a lot it’s essential be taught earlier than you possibly can discover and perceive your knowledge, however I’m going to point out you two instruments that can assist you go quicker. These are abstract statistics and graphs.
Abstract statistics and graphs/plots are utilized by new and skilled knowledge scientists alike, making them the proper constructing blocks for exploring knowledge.
We will likely be working with this dataset accessible from Kaggle in the event you’d wish to comply with alongside. I selected this dataset as a result of it has a number of fascinating properties, similar to a number of steady and categorical variables, lacking knowledge, and quite a lot of distributions and skews. I’ll clarify every variable I work with and why I selected every one to point out you the instruments you possibly can apply to your chosen knowledge set.
In our earlier weblog posts, we checked out the place to get knowledge from and produce that knowledge into PyCharm. You possibly can take a look at steps 1 and a pair of from our weblog submit entitled 7 methods to make use of Jupyter notebooks in PyCharm to create a brand new Jupyter pocket book and import your knowledge as a CSV file in the event you want a reminder. You should use the dataset I linked above or decide your personal for this walkthrough.
We’re going to be utilizing the pandas library on this weblog submit, so to make sure we’re all on the identical web page, your code ought to look one thing like the next block in a Jupyter pocket book – you’ll want to vary the spreadsheet identify and site to yours, although. Be sure to’ve imported matplotlib, too, as we will likely be utilizing that library to discover our knowledge.
import pandas as pd
import matplotlib as plt
df = pd.read_csv('../knowledge/AmesHousing.csv')
df
While you run that cell, PyCharm will present you your DataFrame, and we will get began.
Attempt PyCharm Skilled without spending a dime
Abstract statistics
After we checked out the place to get knowledge from, we mentioned steady and categorical variables. We will use Jupyter notebooks inside PyCharm to generate totally different abstract statistics for these, and, as you may need already guessed, the abstract statistics differ relying on whether or not the variables are steady or categorical.
Steady variables abstract statistics
First, let’s see how we will view our abstract statistics. Click on on the small bar graph icon on the right-hand facet of your DataFrame and choose Compact:
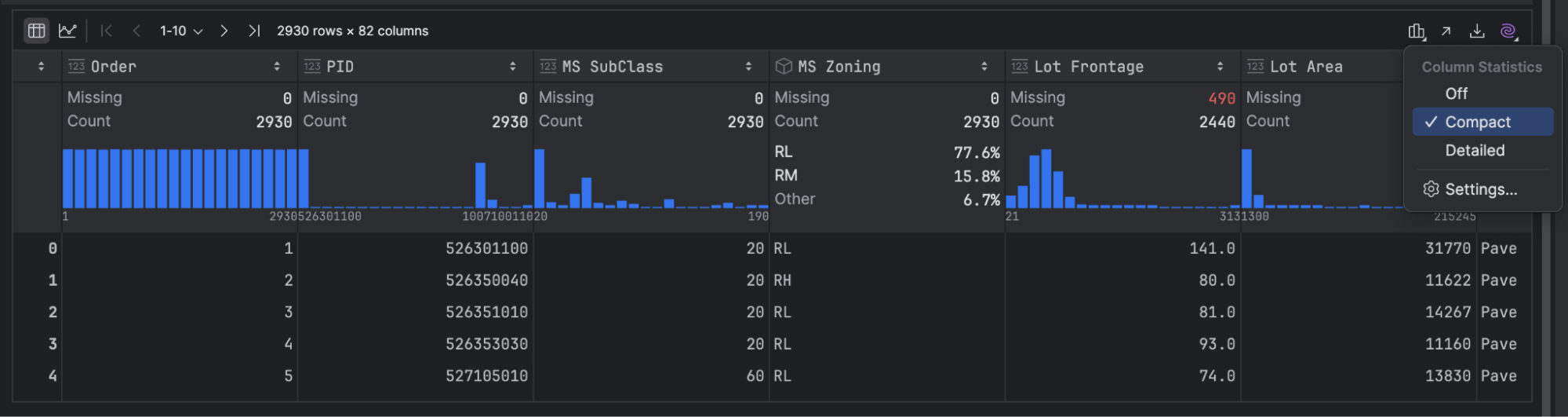
Let me provide you with a bit tip right here in the event you’re uncertain which variables are steady and that are categorical, PyCharm reveals totally different abstract statistics for every one. Those with the mini graphs (blue on this screenshot) are steady, and people with out are categorical.
This knowledge set has a number of steady variables, similar to Order, PID, MS SubClass, and extra, however we are going to give attention to Lot Frontage first. That’s the quantity of house on the entrance of the property.
The abstract statistics already give us some clues:
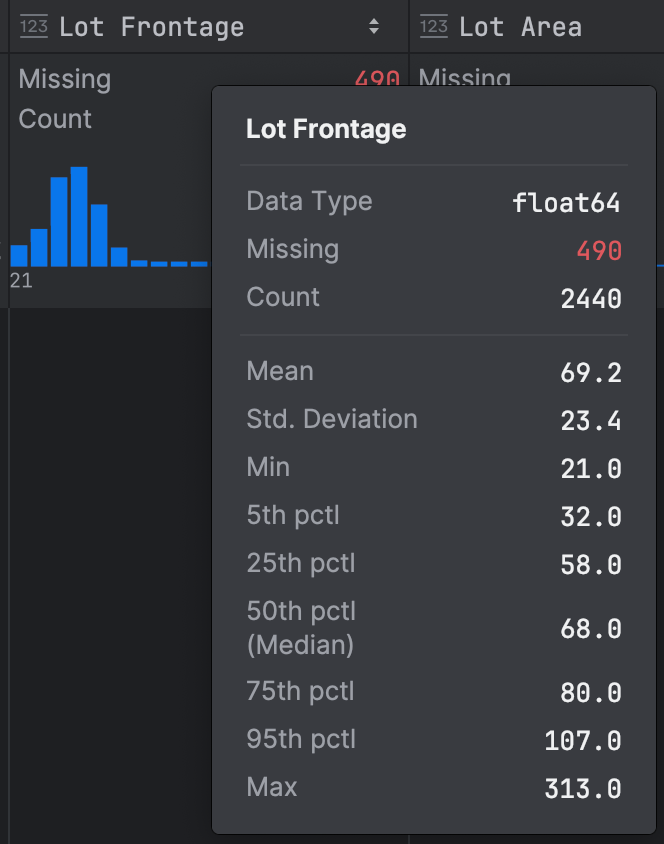
There’s loads of knowledge right here, so let’s break it down and discover it to grasp it higher. Instantly, we will see that we now have lacking knowledge for this variable; that’s one thing we need to notice, as it would imply we now have some points with the dataset, though we gained’t go into that on this weblog submit!
First, you possibly can see the little histogram in blue in my screenshot, which tells us that we now have a optimistic skew in our knowledge as a result of the information tails off to the suitable. We will additional affirm this with the information as a result of the imply is barely bigger than the median. That’s not fully stunning, given we’d count on the vast majority of lot frontages to be of the same dimension, however maybe there are a small variety of luxurious properties with a lot greater lot frontages which are skewing our knowledge. Given this skew, we’d be nicely suggested to not use the usual deviation as a measure of dispersion as a result of that’s calculated by utilizing all knowledge factors, so it’s affected by outliers, which we all know we now have on one facet of our distribution.
Subsequent, we will calculate our interquartile vary because the distinction between our twenty fifth percentile of 58.0 and our seventy fifth percentile of 80.0, giving us an interquartile vary of twenty-two.0. Alongside the interquartile vary, it’s useful to think about the median, the center worth in our knowledge, and in contrast to the imply, it’s not based mostly on each knowledge level. The median is extra acceptable for Lot Frontage than the imply as a result of it’s not affected by the outliers we all know we now have.
Since we’re speaking concerning the median and interquartile vary, it’s value saying that field plots are a good way to characterize these values visually. We will ask JetBrains AI Assistant to create one for us with a immediate similar to this:
Create code utilizing matplotlib for a field plot for ‘Lot Frontage’. Assume we now have all needed imports and the information exists.
Right here’s the code that was generated:
plt.determine(figsize=(10, 6))
plt.boxplot(df['Lot Frontage'].dropna(), vert=False)
plt.title('Field Plot of Lot Frontage')
plt.xlabel('Lot Frontage')
plt.present()
After I click on Settle for and run, we get our field plot:
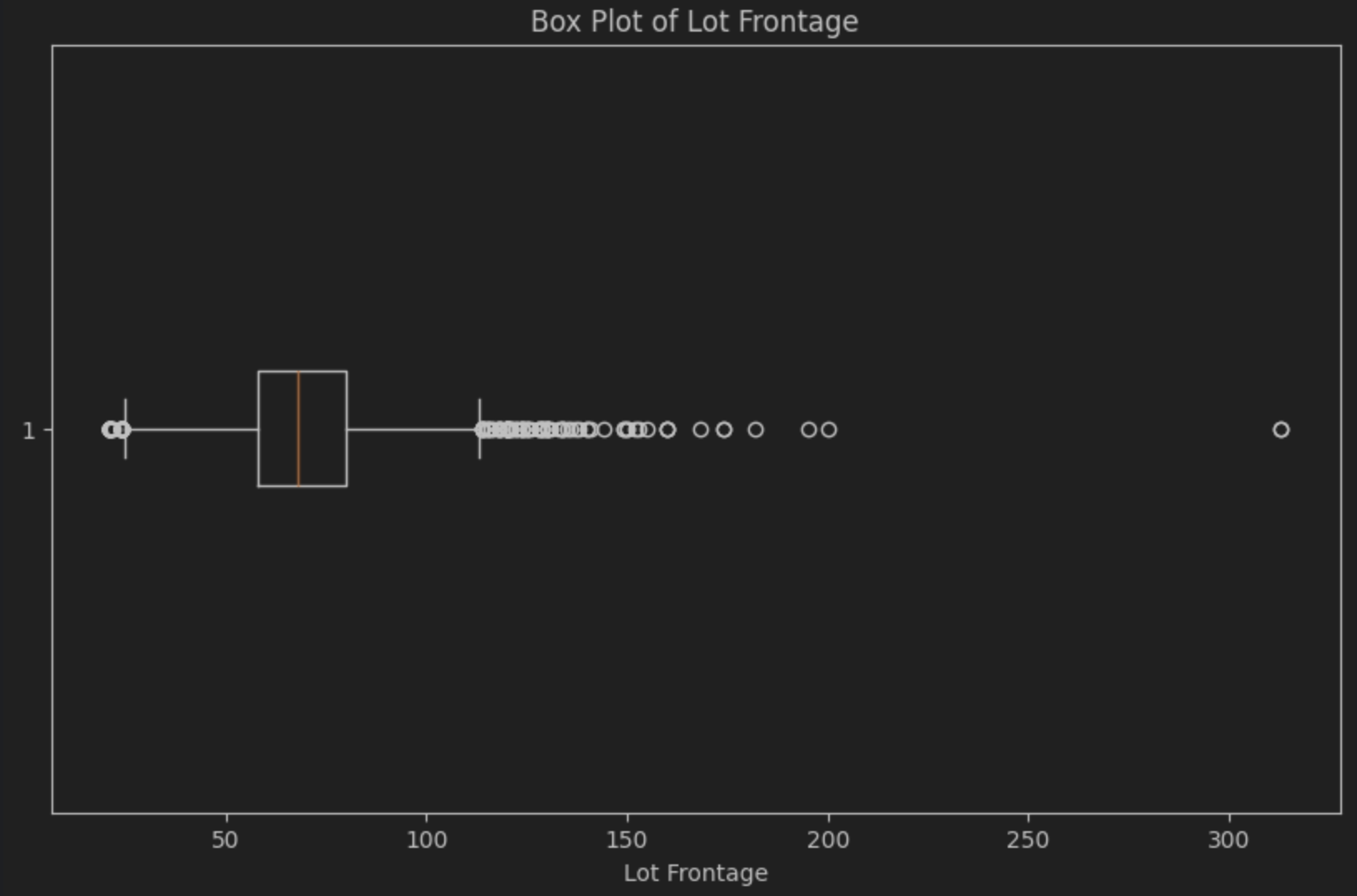
The median is the road contained in the field, which, as you possibly can see, is barely to the left, confirming the presence of the optimistic or right-hand skew. The field plot additionally makes it very straightforward to see a noticeable variety of outliers to the suitable of the field, referred to as “the tail”. That’s the small variety of doubtless luxurious properties that we suspect we now have.
It’s vital to notice that coupling the imply and commonplace deviation or the median and IQR provides you two items of knowledge for that knowledge: a central tendency and the variance. For figuring out the central tendency, the imply is extra liable to being affected by outliers, so it’s best when there isn’t a skew in your knowledge, whereas the median is extra strong in that regard. Likewise, for the variation, the commonplace deviation will be affected by outliers in your knowledge. In distinction, the interquartile vary will all the time inform you the distribution of the center 50% of your knowledge. Your objectives decide which measurements you need to use.
Categorical variables abstract statistics
With regards to categorical variables in your knowledge, you need to use the abstract statistics in PyCharm to seek out patterns. At this level, we have to be clear that we’re speaking about descriptive relatively than inferential statistics. Meaning we will see patterns, however we don’t know if they’re important.
Some examples of categorical knowledge on this knowledge set embrace MS Zoning, Lot Form, and Home Type. You possibly can achieve a lot of insights simply by wanting by your knowledge set. For instance, wanting on the categorical variable Neighborhood, the bulk are acknowledged as Different within the abstract statistics with 75.8%. This tells you that there may nicely be loads of classes in Neighborhood, which is one thing to keep in mind after we transfer on to graphs.
As one other instance, the specific variable Home Type states that about 50% of the homes are one-story, whereas 30% are two-story, leaving 20% that fall into another class that you just may need to discover in additional element. You possibly can ask JetBrains AI for assist right here with a immediate like:
Write pandas code that tells me all of the classes for ‘Home Type’ in my DataFrame ‘df’, which already exists. Assume we now have all the required imports and that the information exists.
Right here’s the ensuing code:
unique_house_styles = df['House Style'].distinctive()
print("Distinctive classes for 'Home Type':")
print(unique_house_styles)
After we run that we will see that the remaining 20% is break up between numerous codes that we’d need to analysis extra to grasp what they imply:
Distinctive classes for ‘Home Type’:
['1Story' '2Story' '1.5Fin' 'SFoyer' 'SLvl' '2.5Unf' '1.5Unf' '2.5Fin']
Take a look by the information set at your categorical variables and see what insights you possibly can achieve!
Earlier than we transfer on to graphs, I need to contact on another piece of performance inside PyCharm that you need to use to entry your abstract statistics referred to as Clarify DataFrame. You possibly can entry it by clicking on the purple AI icon on the top-right of the DataFrame after which selecting AI Actions | Clarify DataFrame.
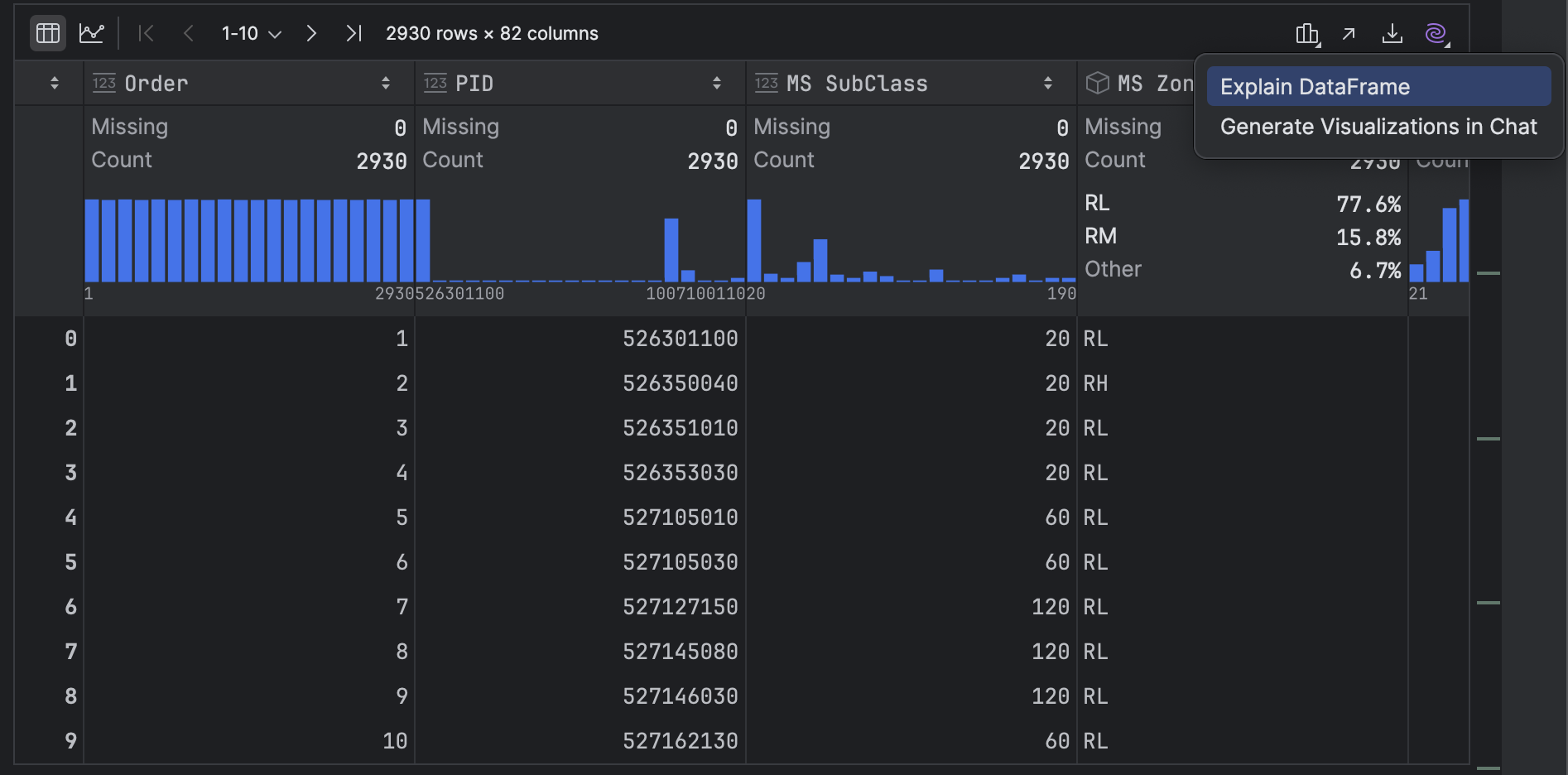
JetBrains AI lists out your abstract statistics however can also add some code snippets which are useful so that you can get your knowledge journey began, similar to how you can drop lacking values, filter rows based mostly on a situation, choose particular columns, in addition to group and combination knowledge.
Graphs
Graphs or plots are a method of rapidly getting patterns to come out at you that may not be apparent once you’re wanting on the numbers within the abstract statistics. We’re going to take a look at a few of the plots you will get PyCharm to generate that can assist you discover your knowledge.
First, let’s revisit our steady variable, Lot Frontage. We already realized that we now have a optimistic or right-hand skew from the mini histogram within the abstract statistics, however we need to know extra!
In your DataFrame in PyCharm, click on the Chart View icon on the left-hand facet:
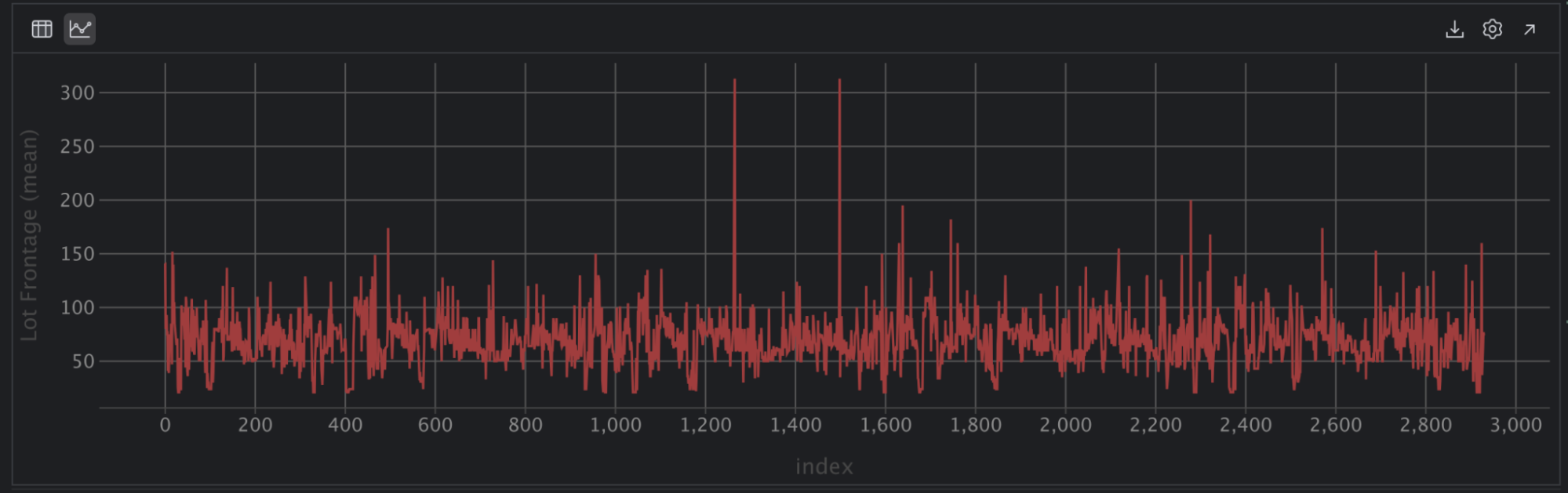
Now click on the cog on the right-hand facet of the chart that claims Present sequence settings and choose the Histogram plot icon on the far right-hand facet. Click on x to clear the values within the X axis and Y axis after which choose Lot Frontage with group and kind for the X axis and Lot Frontage with rely for the Y axis:
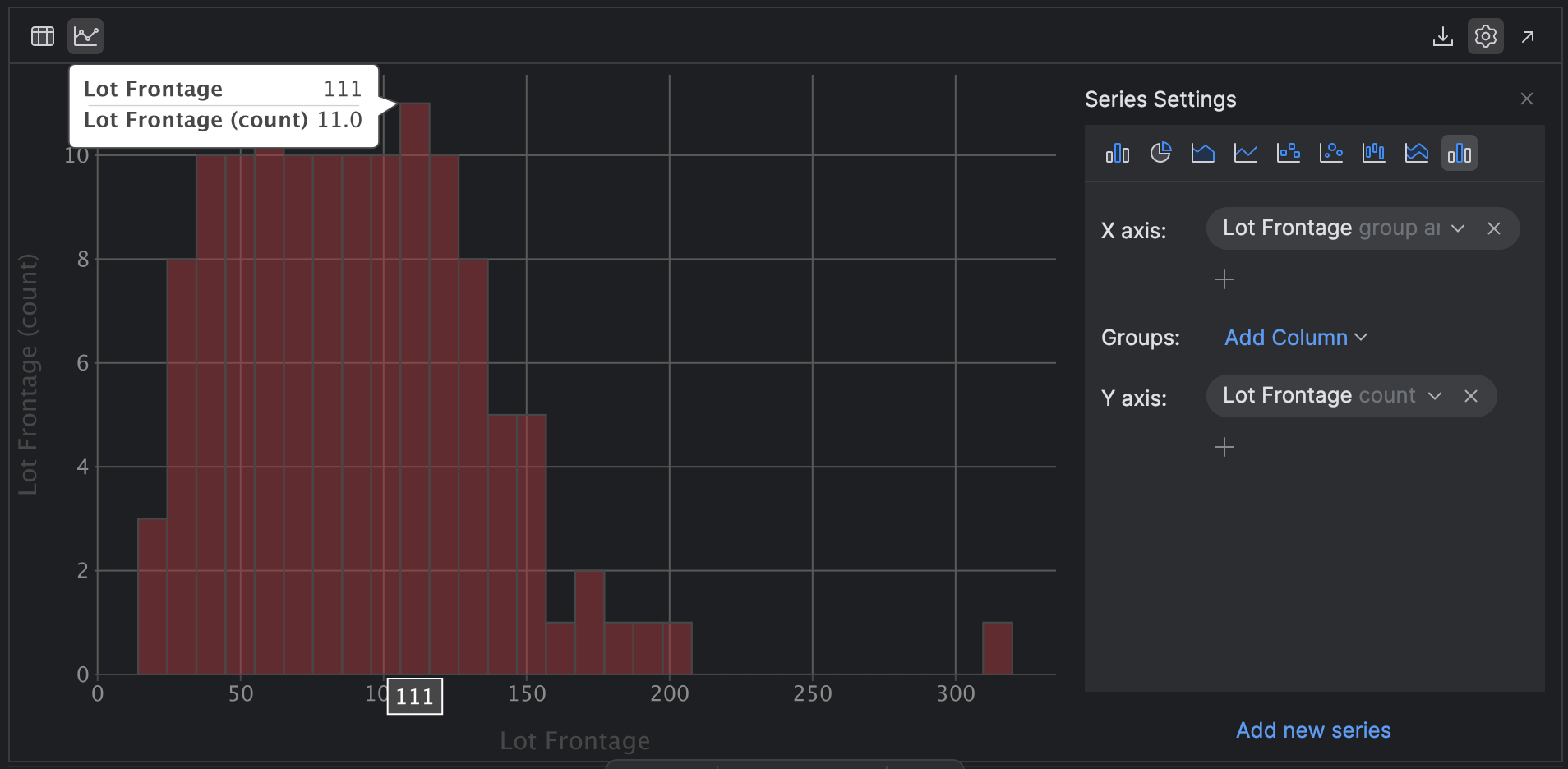
PyCharm generates the identical histogram as you see within the abstract settings, however we didn’t have to put in writing a single line of code. We will additionally discover the histogram and mouse over knowledge factors to be taught extra.
Let’s take it to the following stage whereas we’re right here. Maybe we need to see if the situation of the property, as captured by the Total Cond variable, predicts the sale value.
Change your X axis SalePrice group and kind and your Y axis to SalePrice rely after which add the group Total Cond:
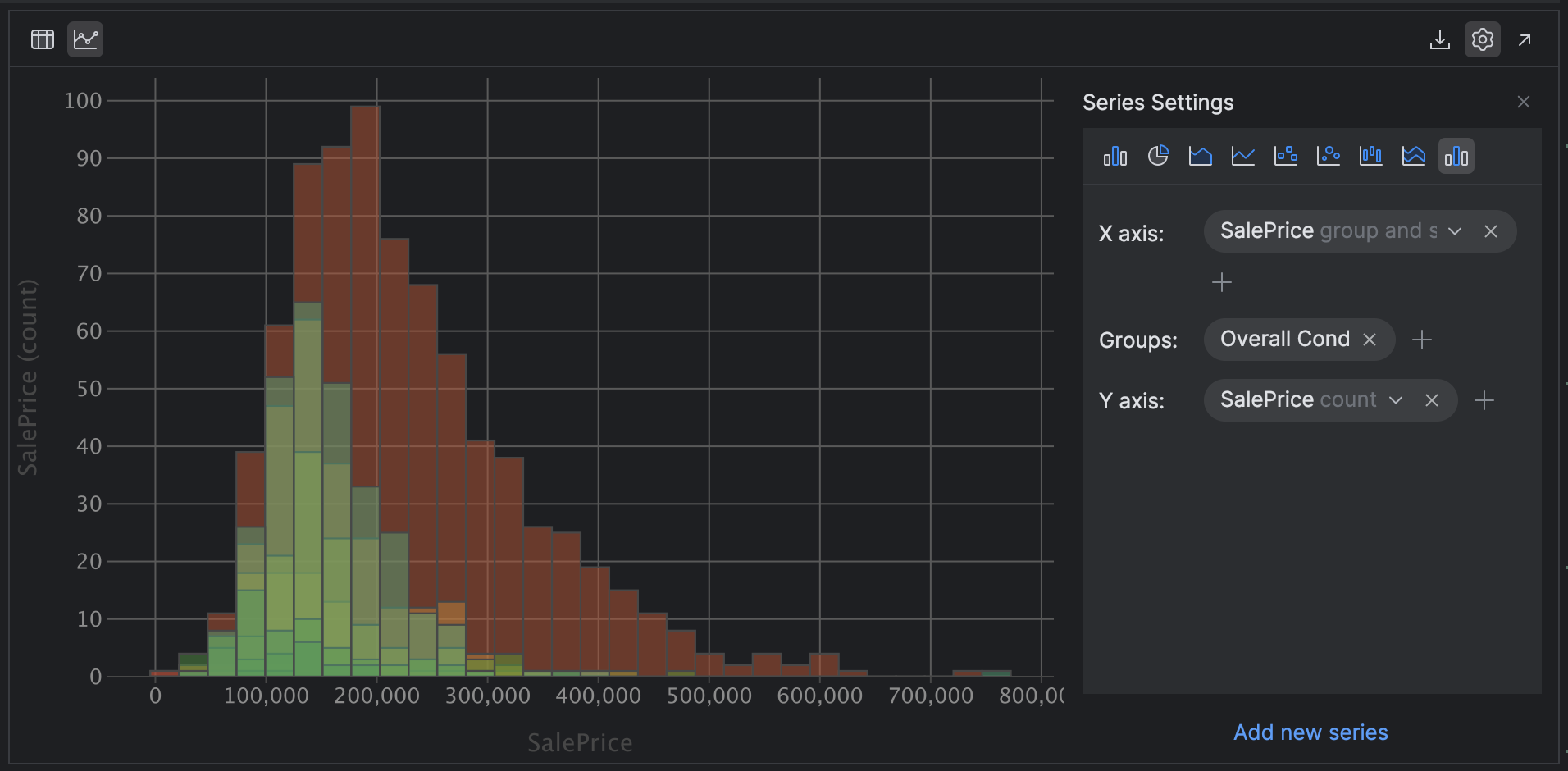
this chart, we will hypothesize that the general situation of the property is certainly a predictor of the sale value, because the distribution and skew are remarkably comparable. One small notice is that grouping histograms like this works finest when you could have a smaller variety of classes. If you happen to change Teams to Neighborhood, which we all know has many extra classes, it turns into a lot tougher to view!
Shifting on, let’s stick to PyCharm’s plotting capabilities and discover bar graphs. These are a companion to frequency charts similar to histograms, however can be used for categorical knowledge. Maybe you have an interest in Neighbourhood (a categorical variable) in relation to SalesPrice.
Click on the Bar [chart] icon on the left-hand facet of your sequence setting, then choose Neighbourhood as Classes and SalesPrice with the median because the Values:
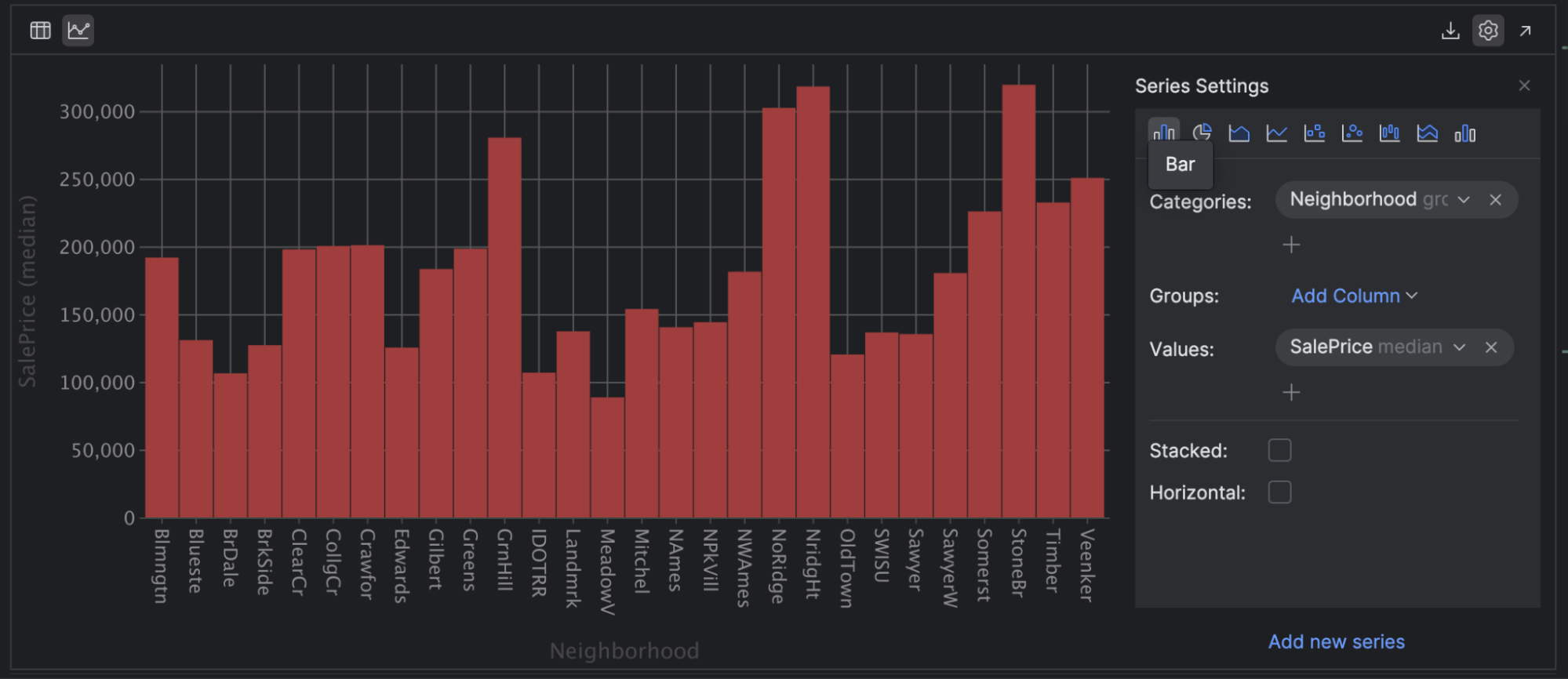
This helps us perceive the neighborhoods with the most costly and least expensive housing. I selected the median for the SalesPrice because it’s much less inclined to outliers within the knowledge. For instance, I can see that housing in Mitchel is prone to be considerably cheaper than in NoRidge.
Line plots are one other helpful plot in your toolkit. You should use these to reveal developments between steady variables over a time period. For instance, choose the Line [graph] icon after which select 12 months Constructed because the X axis and SalePrice with the imply because the Y axis:
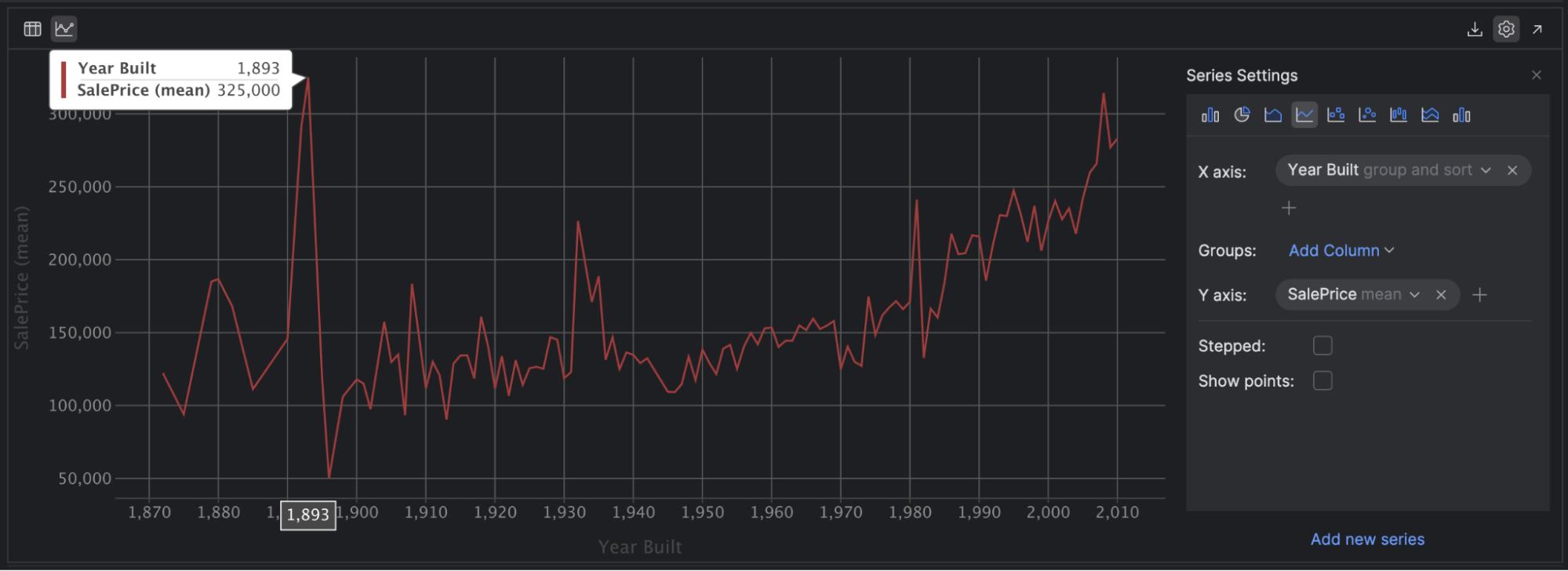
This means a small optimistic correlation between the 12 months the home was constructed and the worth of the home, particularly after 1950. If you happen to’re feeling adventurous, take away the imply from SalePrice and see how your graph adjustments when it has to plot each single value!
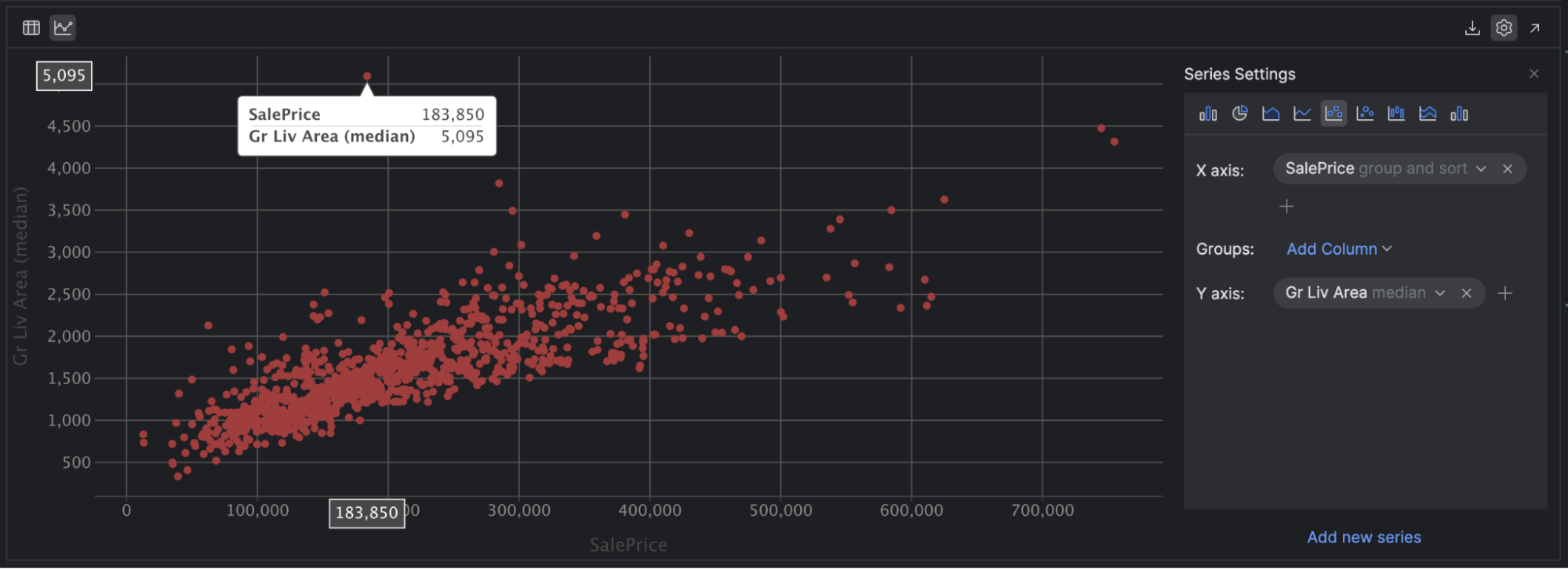
The final plot I’d like to attract your consideration to is scatter plots. These are a good way to see a relationship between two steady variables and any correlation between them. A correlation reveals the power of a relationship between two variables. To dig deeper, try this beginner-friendly overview from Actual Python.
For instance, if we set our X axis to SalePrice and our Y axis to Gr LivArea, we will see that there’s a optimistic correlation between the 2 variables, and we will additionally simply spot some outliers in our knowledge, together with a few homes with a decrease sale value however an enormous dwelling space!
Abstract
Right here’s a reminder of what we’ve lined immediately. You possibly can entry your abstract statistics in PyCharm both by Clarify DataFrame with JetBrains AI or by clicking on the small graph icon on the right-hand facet of a DataFrame referred to as Column statistics after which deciding on Compact. You too can use Detailed to get much more info than we’ve lined on this weblog submit.
You may get PyCharm to create graphs to discover your knowledge and create hypotheses for additional investigation. Some extra generally used ones are histograms, bar charts, line graphs, and scatter plots.
Lastly, you need to use JetBrains AI Assistant to generate code with pure language prompts within the AI software window. It is a fast strategy to be taught extra about your knowledge and begin fascinated with the insights on supply.
Obtain PyCharm Skilled to strive it out for your self! Get an prolonged trial immediately and expertise the distinction PyCharm Skilled could make in your knowledge science endeavors. Use the promotion code “PyCharmNotebooks” at checkout to activate your free 60-day subscription to PyCharm Skilled. The free subscription is on the market for particular person customers solely.
Attempt PyCharm Skilled without spending a dime
Utilizing each abstract statistics and graphs in PyCharm, we will be taught lots about our knowledge, giving us a stable basis for our subsequent step – cleansing our knowledge, which we are going to discuss within the subsequent weblog submit on this sequence.

Subscribe to PyCharm Weblog updates
