


{kind=link}
To date, now we have returned the total content material of our tables. Nevertheless, as our database grows, this may show to not be the very best strategy when it comes to efficiency. A preferred answer is to serve the information in chunks by presenting a number of pages or implementing infinite scrolling. On this article, we implement its back-end side utilizing NestJS and PostgreSQL. We additionally evaluate numerous approaches to attaining it and level out their benefits and drawbacks.
You will discover the code from this text in this repository.
Offset and restrict
Let’s begin by investigating this straightforward question:
|
SELECT id, title FROM posts |
It returns the entire data from the posts desk.

A big factor to acknowledge is that the order of the above rows shouldn’t be assured. Nevertheless, when implementing pagination, we rely on the order of rows to be predictable. Due to this fact, we should always use the ORDER BY clause.
|
SELECT id, title FROM posts ORDER BY id ASC |

To begin paginating our knowledge, we have to restrict the variety of rows in our question. To try this, we’d like the LIMIT assertion.
|
SELECT id, title FROM posts ORDER BY id ASC LIMIT 10 |
Due to the above, we now get the primary ten objects as an alternative all of them. This permits us to current the consumer with the first web page of outcomes.
To serve the second web page of the information, we have to specify the start line of our question. We are able to use the OFFSET key phrase to specify what number of rows we need to skip.
|
SELECT id, title FROM posts ORDER BY id ASC OFFSET 10 LIMIT 10 |

Above, we omit the primary ten posts and get ten posts within the outcomes. In our case, it provides us entities with ids from 11 to twenty. That is the place the order of our knowledge performs a major function. We are able to simply modify it by altering the ORDER BY clause, however holding some order is necessary.
Counting the variety of rows
It’s a frequent strategy to show the variety of knowledge pages to the consumer. For instance, if now we have fifty rows and show ten per web page, now we have 5 knowledge pages.
To do the above, we have to know the variety of rows of information in our desk. To try this, we are able to use the COUNT key phrase.
|
SELECT COUNT(*) AS all_posts_count FROM posts |

We are able to use the COUNT key phrase whereas choosing knowledge from some columns. When doing that, we have to specify the part of the information we’re counting by partitioning it. For instance, we are able to rely the variety of posts by a sure creator.
|
SELECT author_id, COUNT(*) OVER (PARTITION BY author_id) AS author_posts_count FROM posts |
To current the ends in a readable approach, let’s solely show one row per creator utilizing the DISTINCT key phrase.
|
SELECT DISTINCT author_id, COUNT(*) OVER (PARTITION BY author_id) AS author_posts_count FROM posts |

Above, we are able to see that the creator with id 3 wrote two posts, and the creator with id 2 wrote forty posts.
In our case, we need to rely the entire variety of posts. Nevertheless, though that’s the case, we nonetheless want to make use of the OVER clause.
|
SELECT id, title, COUNT(*) OVER() AS total_posts_count FROM posts ORDER BY id ASC OFFSET 10 LIMIT 10 |

Grouping and partitioning knowledge with the OVER() operate is an effective subject for a separate article.
The entire thought is to rely the variety of rows and fetch their particulars in the identical transaction to maintain the integrity of the information. Once we run a single question, PostgreSQL wraps it in a transaction out of the field.
We are able to outline a transaction individually if we need to rely the posts in a separate SELECT assertion.
|
BEGIN; SELECT id, title FROM posts ORDER BY id ASC OFFSET 10 LIMIT 10;
SELECT COUNT(*) AS total_posts_count FROM posts; COMMIT; |
If you wish to know extra about transactions, take a look at API with NestJS #76. Working with transactions utilizing uncooked SQL queries
It is usually necessary to note that PostgreSQL returns the results of COUNT as large int. The utmost worth of an everyday integer is 2³¹⁻¹ (2,147,483,647), and for an enormous integer, it’s 2⁶³⁻¹ (9,223,372,036,854,775,807).
Sadly, JavaScript doesn’t know methods to parse large integers to JSON out of the field.
|
const knowledge = { worth: BigInt(10) }
JSON.stringify(knowledge); |
Uncaught TypeError: Have no idea methods to serialize a BigInt
If we don’t count on our desk to carry greater than 2,147,483,647 parts, we are able to solid the results of COUNT(*) to an everyday integer.
|
SELECT COUNT(*) OVER()::int AS total_posts_count FROM posts |
Implementing offset pagination with NestJS
When implementing the offset pagination with NestJS, we count on the consumer to supply the offset and restrict as question parameters. To deal with that, we are able to create a delegated class.
paginationParams.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import { IsNumber, Min, IsOptional } from ‘class-validator’; import { Kind } from ‘class-transformer’;
class PaginationParams { @IsOptional() @Kind(() => Quantity) @IsNumber() @Min(0) offset?: quantity;
@IsOptional() @Kind(() => Quantity) @IsNumber() @Min(1) restrict?: quantity; }
export default PaginationParams; |
We then use it in our controller.
posts.controller.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import { ClassSerializerInterceptor, Controller, Get, Question, UseInterceptors, } from ‘@nestjs/frequent’; import { PostsService } from ‘./posts.service’; import GetPostsByAuthorQuery from ‘./getPostsByAuthorQuery’; import PaginationParams from ‘../utils/paginationParams’;
@Controller(‘posts’) @UseInterceptors(ClassSerializerInterceptor) export default class PostsController { constructor(personal readonly postsService: PostsService) {}
@Get() getPosts( @Question() { authorId }: GetPostsByAuthorQuery, @Question() { offset, restrict }: PaginationParams, ) { return this.postsService.getPosts(authorId, offset, restrict); }
// … } |
The final step is to implement the logic in our PostsRepository class.
posts.repository.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import { Injectable, } from ‘@nestjs/frequent’; import DatabaseService from ‘../database/database.service’; import PostModel from ‘./publish.mannequin’;
@Injectable() class PostsRepository { constructor(personal readonly databaseService: DatabaseService) {}
async get(offset = 0, restrict: quantity | null = null) { const databaseResponse = await this.databaseService.runQuery( ` SELECT id, title, COUNT(*) OVER()::int AS total_posts_count FROM posts ORDER BY id ASC OFFSET $1 LIMIT $2 `, [offset, limit], ); const objects = databaseResponse.rows.map( (databaseRow) => new PostModel(databaseRow), ); const rely = databaseResponse.rows[0]?.total_posts_count || 0; return { objects, rely, }; }
// … }
export default PostsRepository; |
A big factor above is that we offer default values for offset and restrict:
- offering for offset implies that we don’t intend to skip any rows,
- by setting the restrict to null, we state that we don’t need to restrict the outcomes.
Doing the entire above, we find yourself with absolutely purposeful offset pagination.

Disadvantages
The offset and restrict strategy to pagination is broadly used. Sadly, it has some important disadvantages.
A very powerful caveat is that the database must compute the entire rows skipped by the OFFSET key phrase. This could take a toll on the efficiency:
- first, the database types the entire rows as specified within the ORDER BY clause,
- then, PostgreSQL drops the variety of rows specified within the OFFSET.
Apart from the above situation, we are able to run into an issue with consistency:
- the primary consumer fetches web page primary with posts,
- the second consumer creates a brand new publish that finally ends up on web page primary,
- the primary consumer fetches the second web page.
Sadly, the above operations trigger the primary consumer to see the final factor of the primary web page once more on the second web page. In addition to that, the consumer missed the factor added to the primary web page.
Benefits
The offset strategy is quite common and easy to implement. It is usually very straightforward to vary the column we use for sorting, together with a number of columns. It makes it an appropriate answer in lots of circumstances, particularly if the offset shouldn’t be anticipated to be large and the information inconsistencies are acceptable.
Keyset pagination
We are able to take one other strategy to pagination by filtering out the information we’ve already seen utilizing the WHERE key phrase as an alternative of OFFSET. First, let’s run the next question:
|
SELECT id, title FROM posts ORDER BY id ASC LIMIT 10 |

Within the outcomes, we are able to see that the final publish has an id of 10. We are able to now use this data to request posts with the id greater than 10.
|
SELECT id, title FROM posts WHERE id > 10 ORDER BY id ASC LIMIT 10 |
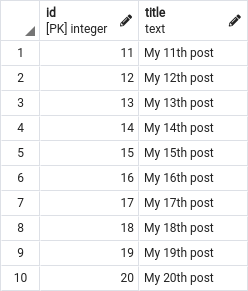
To get the subsequent web page of outcomes, we have to examine the above outcomes and spot that the id of the final row is 20. We are able to use that to switch our WHERE clause.
|
SELECT id, title FROM posts WHERE id > 20 ORDER BY id ASC LIMIT 10 |
Sadly, this exposes essentially the most important disadvantages of the keyset pagination. To get a bit of information, we have to know the id of the final factor of the earlier chunk. This makes traversing multiple web page without delay unattainable.
To vary the column by which we order our parts, we have to modify each ORDER BY and WHERE clauses.
Counting the variety of rows
It’s essential to note that utilizing the WHERE clause impacts the rows counted with COUNT(*). To take care of this situation, we have to rely the rows individually. We are able to create an express transaction or use a Widespread Desk Expression question utilizing the WITH assertion.
|
WITH selected_posts AS ( SELECT id, title FROM posts WHERE id > 10 ORDER BY id ASC LIMIT 10 ), total_posts_count_response AS ( SELECT COUNT(*) AS total_posts_count FROM posts ) SELECT * FROM selected_posts, total_posts_count_response |

Implementing keyset pagination with NestJS
First, let’s modify our PaginationParams class to simply accept a further question parameter.
paginationParams.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import { IsNumber, Min, IsOptional } from ‘class-validator’; import { Kind } from ‘class-transformer’;
class PaginationParams { @IsOptional() @Kind(() => Quantity) @IsNumber() @Min(0) offset?: quantity;
@IsOptional() @Kind(() => Quantity) @IsNumber() @Min(1) restrict?: quantity;
@IsOptional() @Kind(() => Quantity) @IsNumber() @Min(1) idsToSkip?: quantity; }
export default PaginationParams; |
We additionally want to switch our PostsRepository to deal with the extra parameter.
posts.repository.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import { Injectable } from ‘@nestjs/frequent’; import DatabaseService from ‘../database/database.service’; import PostModel from ‘./publish.mannequin’;
@Injectable() class PostsRepository { constructor(personal readonly databaseService: DatabaseService) {}
async get(offset = 0, restrict: quantity | null = null, idsToSkip = 0) { const databaseResponse = await this.databaseService.runQuery( ` WITH selected_posts AS ( SELECT * FROM posts WHERE id > $3 ORDER BY id ASC OFFSET $1 LIMIT $2 ), total_posts_count_response AS ( SELECT COUNT(*)::int AS total_posts_count FROM posts ) SELECT * FROM selected_posts, total_posts_count_response `, [offset, limit, idsToSkip], ); const objects = databaseResponse.rows.map( (databaseRow) => new PostModel(databaseRow), ); const rely = databaseResponse.rows[0]?.total_posts_count || 0; return { objects, rely, }; }
// … }
export default PostsRepository; |
Disadvantages
Essentially the most obvious drawback of the keyset pagination is that the customers have to know the id of the row they need to begin with. Nevertheless, we might overcome that by mixing the offset-based pagination with the keyset pagination.
Moreover, the column used within the WHERE clause ought to have an index for a further efficiency increase. Thankfully, PostgreSQL creates an index for each major key out of the field. Due to this fact, the keyset pagination ought to carry out properly when utilizing ids.
Additionally, ordering the outcomes by textual content fields may not be easy if we need to use pure sorting. If you wish to know extra, take a look at this reply on StackOverflow.
Benefits
The keyset pagination could be a important efficiency enchancment over the offset-based strategy. It additionally solves the information inconsistency situation we are able to expertise with offset pagination. The consumer including or eradicating parts between fetching chunks of information doesn’t trigger parts to be duplicated or skipped.
Abstract
On this article, we’ve gone by means of two totally different approaches to pagination with PostgreSQL. After stating their benefits and drawbacks, we are able to conclude that every could be a cheap answer. The keyset pagination is extra restrictive however can present a efficiency increase. Thankfully, we are able to combine alternative ways of paginating the information, and mixing the offset and keyset pagination can cowl all kinds of circumstances.