


{kind=link}
Suppose 
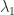
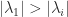
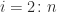
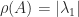
On this pseudocode, norm(x) denotes the 
x.
Select n-vector q_0 such that norm(q_0) = 1.
for okay=1,2,...
z_k = A q_{k-1} % Apply A.
q_k = z_k / norm(z_k) % Normalize.
mu_k = q_k^*Aq_k % Rayleigh quotient.
finish
The normalization is to keep away from overflow and underflow and the 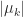
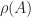
If 
Right here is an instance the place the ability methodology converges rapidly, because of the substantial ratio of 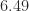
>> rng(1); A = rand(4); eig_abs = abs(eig(A)), q = rand(4,1);
>> for okay = 1:5, q = A*q; q = q/norm(q); mu = q'*A*q;
>> fprintf('%1.0f %7.4en',okay,mu)
>> finish
eig_abs =
1.3567e+00
2.0898e-01
2.5642e-01
1.9492e-01
1 1.4068e+00
2 1.3559e+00
3 1.3580e+00
4 1.3567e+00
5 1.3567e+00