


{kind=link}
By Visitor Blogger Liz Fong-Jones, Principal Developer Advocate, Honeycomb.io
Background
Honeycomb is a number one observability platform utilized by high-performance engineering groups to shortly visualize, analyze, and enhance cloud utility high quality and efficiency. We make the most of the OpenTelemetry normal to ingest information from our purchasers, together with these hosted on AWS and utilizing the AWS Distribution of OpenTelemetry. As soon as information is optionally pre-sampled inside consumer Amazon Digital Non-public Clouds (Amazon VPC), it flows to Honeycomb for evaluation, leading to a knowledge quantity of thousands and thousands of hint spans per second passing by means of our methods.
To verify of the sturdiness and reliability of processing throughout software program upgrades, spot occasion retirements, and different steady chaos, we make the most of Software Load Balancers (ALBs) to route site visitors to stateless ingest staff which publish the info right into a pub-sub or message queuing system. Then, we learn from this technique to devour any telemetry added because the final checkpoint, decoupling the ingest course of and permitting for indexing to be paused and restarted. For all the historical past of Honeycomb courting again to 2016, we’ve got used variants of the Apache Kafka software program to carry out this significant pub-sub function.
Elements in Kafka efficiency
After having chosen im4gn.4xlarge cases for our Kafka brokers, we had been curious how a lot additional we may push the already wonderful efficiency that we had been seeing. Though it’s true that Kafka and different JVM workloads “simply work” on ARM with out modification in a majority of instances, somewhat little bit of fine-tuning and polish can actually repay.
To know the important elements underlying the efficiency of our Kafka brokers, let’s recap what Kafka brokers do normally, in addition to what extra options our particular Kafka distribution accommodates.
Apache Kafka is written in a mixture of Scala and Java, with some JNI-wrapped C libraries for performance-sensitive code, comparable to ZSTD compression. A Kafka dealer serializes and batches incoming information coming from producers or replicated from its friends, serves information to its friends to permit for replication, and responds to requests to devour lately produced information. Moreover, it manages the info lifecycle and ages out expired segments, tracks client group offsets, and manages metadata in collaboration with a fleet of Zookeeper nodes.
As defined within the im4gn publish, we use Confluent Enterprise Platform (a distribution of Apache Kafka custom-made by Confluent) to tier older information to Amazon Easy Storage Service (Amazon S3) to unencumber house on the native NVMe SSDs. This extra workload introduces the overhead of high-throughput HTTPS streams, relatively than simply the Kafka inner protocols and disk serialization.
Profiling the Kafka dealer
Instantly after switching to im4gn cases from i3en, we noticed 40% peak CPU utilization, 15% off-peak CPU utilization, and utilized 30% of disk at peak (15% off-peak). We had been hoping to maintain these two utilization numbers roughly in step with one another to maximise the utilization of our cases and maintain value economics below management. By utilizing Async Profiler for brief runs, and later Pyroscope to constantly confirm our outcomes, we may see the place within the dealer’s code CPU time was being spent and determine wasteful utilization.
The very first thing that jumped out at us was the 20% of time being spent doing zstd in JNI.
We hypothesized that we may receive modest enhancements from updating the ZSTD JNI JAR from the 1.5.0-x bundled with Confluent’s distro to a newer 1.5.2-x model.
Nevertheless, our most vital discovering from profiling was the numerous time (12% of consumed CPU) being spent in com/solar/crypto/supplier/GaloisCounterMode.encryptFinal, as a part of the kafka/tier/retailer/S3TierObjectStore.putFile Confluent Tiered Storage course of (28.4% of whole dealer consumed CPU in whole). This was shocking, as we hadn’t seen this excessive of an overhead on the i3en cases, and others who ran vanilla Kafka on ARM had seen comparable CPU profiles to x86.
At this level, we started our collaboration with the Corretto workforce at AWS, which has been working to enhance the efficiency of JVM functions on Graviton. Yishai reached out and requested if we had been keen on making an attempt the Corretto workforce’s department that provides ARM AES CTR intrinsic, as a result of it’s a scorching codepath utilized by TLS.
After upgrading to the department construct of the JDK, and enabling -XX:+UnlockDiagnosticVMOptions -XX:+UseAESCTRIntrinsics in our further JVM flags, we noticed a big efficiency enchancment with profiling exhibiting that com/solar/crypto/supplier/GaloisCounterMode.encryptFinal is simply taking 0.4% of time (with a further 1% every in ghash_processBlocks_wide and counterMode_AESCrypt attributed to unknown_Java). This makes the whole value of the kafka/tier/retailer/S3TierObjectStore.putFile workload now solely 16.4% — a discount of 12% of whole dealer consumed CPU for tiering.
We don’t at present use TLS between Kafka brokers or purchasers, in any other case the financial savings would probably have been even larger. Speculating, this nearly actually lowers to ~1% overhead of the efficiency value of enabling TLS between brokers, which we in any other case might need been hesitant to do because of the massive penalty.
Present me the images and graphs!
Earlier than any experimentation:

After making use of UseAESCTRIntrinsics:

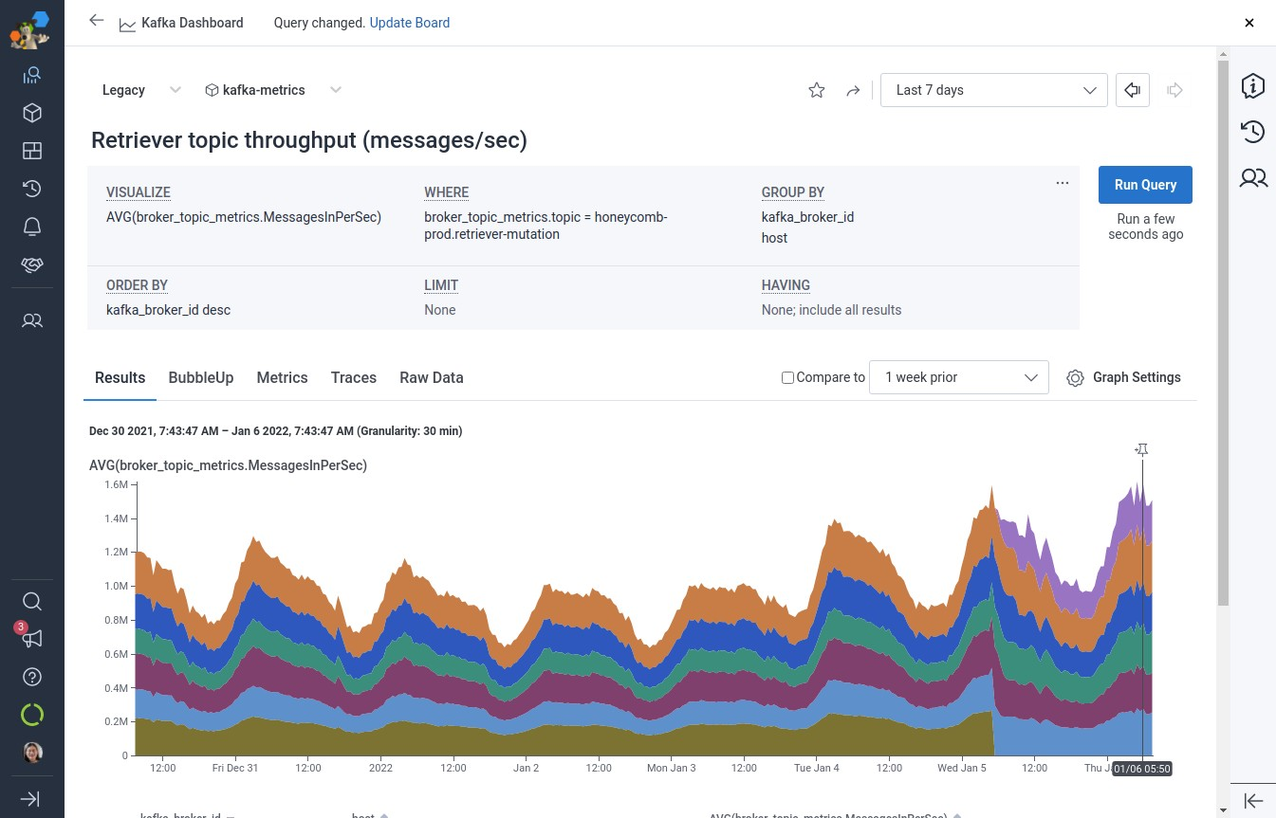
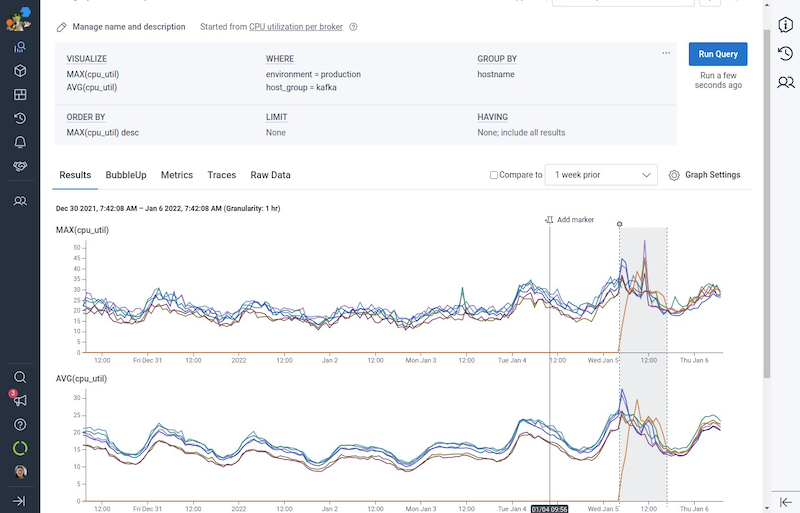
This consequence was clearly higher. Nevertheless, working a bleeding edge JVM construct was not an awesome long-term method for our manufacturing workload, and it wouldn’t essentially make sense to ask the entire Confluent clients or the entire JVM or Kafka workloads to modify to utilizing the most recent Corretto JVM to generalize our outcomes sooner or later. Moreover, there was one other downside not solved by the UseAESCTRIntrinsics patch: MD5 checksum time.
Enter AWS Corretto Crypto Supplier
After addressing TLS/AES overhead, the remaining work left to do was repair the 9.5% of CPU time being spent calculating MD5 (which can also be a part of the method of doing an Amazon S3 add). One of the best resolution right here could be to not carry out the MD5 digest in any respect (since Amazon S3 eliminated the requirement for Content material-MD5 header). In the present day, TLS already contains HMAC stream test summing, and if bits are altering on the disk, then we’ve got greater issues no matter whether or not tiering is going on. The Confluent workforce is engaged on permitting for MD5 opt-out. In the meantime, we wished one thing that might tackle each TLS/AES overhead and MD5 overhead, all with out having to patch the JVM.
The AWS Corretto Crypto Supplier is a Java safety API supplier that implements digest and encryption algorithms with compiled C/JNI wrapped code. Though official binaries aren’t but equipped for ARM, it was straightforward to seize a spare Graviton2 occasion and compile a construct, then set it because the -Djava.safety.properties supplier within the Kafka startup scripts. With ACCP enabled, only one.8% of time is spent in AESGCM (higher than the 0.4%+1%+1% = 2.4% seen with UseAESCTRIntrinsics), and solely 4.7% of time is spent in MD5 (higher than the 9.5% we beforehand noticed).

Because of this the whole overhead of Kafka/tier/retailer/S3TierObjectStore.putFile is now 12-14% relatively than 28% (about half what it was earlier than).
We felt prepared to totally deploy this consequence throughout all of our manufacturing workloads and depart it reside, figuring out that we may nonetheless profit from future rolling Corretto official releases with JVM flags set to manufacturing, non-experimental values.
The way forward for Kafka and ARM at Honeycomb
Though we’re happy after tuning with the conduct of our fleet of six im4gn.2xlarge cases for serving our workload of 2M messages per second, we determined to preemptively scale up our fleet to 9 brokers. The rationale had nothing to do with CPU efficiency. As an alternative, we had been involved after repeated weekly dealer termination chaos engineering experiments concerning the community throughput required throughout peak hours to outlive the lack of a single dealer and re-replicate the entire information in a well timed trend
By spreading the 3x duplicated information throughout 9 brokers, just one third of the entire information, relatively than half of the entire information, would must be re-replicated within the occasion of dealer loss, and the alternative dealer would have eight wholesome friends to learn from, relatively than 5. Rising capability by 50% halved the time required to totally restore in-service reproduction quorum at peak weekday site visitors from north of six hours to lower than three hours.
This modification is only one of a sequence of many small adjustments that we’ve made to optimize and tune our AWS workload at Honeycomb. Within the coming weeks, we hope to share how, with none influence on customer-visible efficiency, we decommissioned 100% of our Intel EC2 cases and 85% of our Intel AWS Lambda capabilities in our fleet for a web value and power financial savings.