

{kind=link}
Internet scraping is a mechanism to crawl internet pages utilizing software program instruments or utilities. It reads the content material of the web site pages over a community stream.
This know-how is also called internet crawling or information extraction. In a earlier tutorial, we realized learn how to extract pages by its URL.
There are extra PHP libraries to assist this function. On this tutorial, we are going to see one of many standard web-scrapping elements named DomCrawler.
This part is beneath the PHP Symfony framework. This text has the code for integrating and utilizing this part to crawl internet pages.
We are able to additionally create customized utilities to scrape the content material from the distant pages. PHP permits built-in cURL capabilities to course of the community request-response cycle.
About DomCrawler
The DOMCrawler part of the Symfony library is for parsing the HTML and XML content material.
It constructs the crawl deal with to succeed in any node of an HTML tree construction. It accepts queries to filter particular nodes from the enter HTML or XML.
It supplies many crawling utilities and options.
- Node filtering by XPath queries.
- Node traversing by specifying the HTML selector by its place.
- Node title and worth studying.
- HTML or XML insertion into the required container tag.
Steps to create an internet scraping software in PHP
- Set up and instantiate an HTTP consumer library.
- Set up and instantiate the crawler library to parse the response.
- Put together parameters and bundle them with the request to scrape the distant content material.
- Crawl response information and skim the content material.
On this instance, we used the HTTPClient library for sending the request.
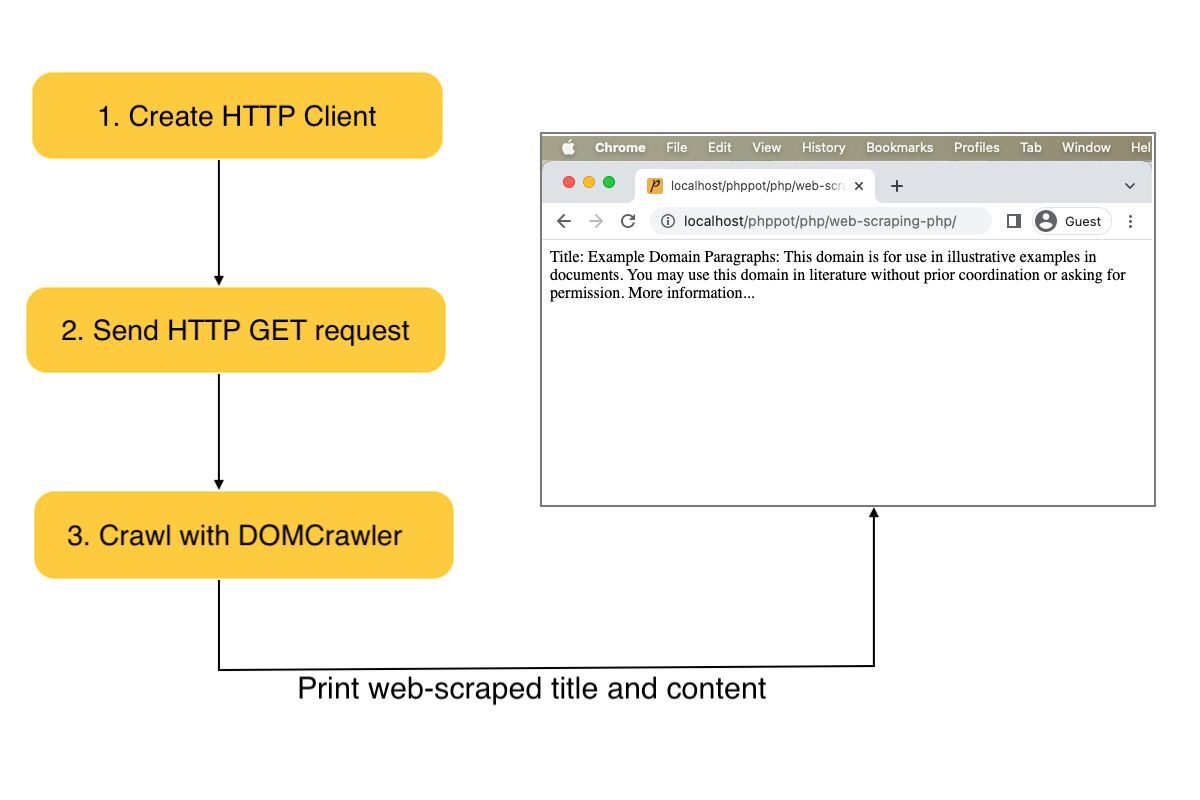
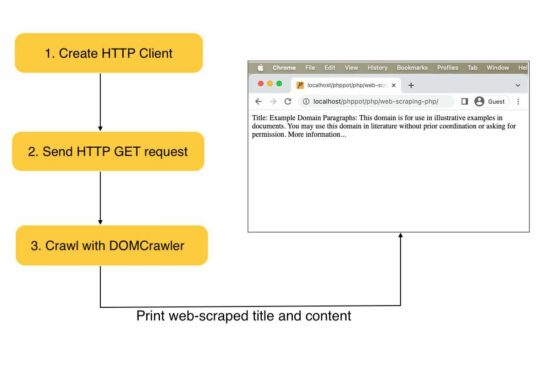
Internet scraping PHP instance
This instance creates a consumer occasion and sends requests to the goal URL. Then, it receives the online content material in a response object.
The PHP DOMCrawler parses the response information to filter out particular internet content material.
On this instance, the crawler reads the location title by parsing the h1 textual content. Additionally, it parses the content material from the location HTML filtered by the paragraph tag.
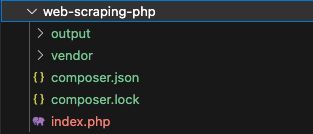
The under picture exhibits the instance venture construction with the PHP script to scrape the online content material.
The best way to set up the Symfony framework library
We’re utilizing the favored Symfony to scrape the online content material. It may be put in through Composer.
Following are the instructions to put in the dependencies.
composer require symfony/http-client symfony/dom-crawler
composer require symfony/css-selector
After operating these composer instructions, a vendor folder can map the required dependencies with an autoload.php file. The under script imports the dependencies by this file.
index.php
<?php
require 'vendor/autoload.php';
use SymfonyComponentHttpClientHttpClient;
use SymfonyComponentDomCrawlerCrawler;
$httpClient = HttpClient::create();
// Web site to be scraped
$web site="https://instance.com";
// HTTP GET request and retailer the response
$httpResponse = $httpClient->request('GET', $web site);
$websiteContent = $httpResponse->getContent();
$domCrawler = new Crawler($websiteContent);
// Filter the H1 tag textual content
$h1Text = $domCrawler->filter('h1')->textual content();
$paragraphText = $domCrawler->filter('p')->every(operate (Crawler $node) {
return $node->textual content();
});
// Scraped consequence
echo "H1: " . $h1Text . "n";
echo "Paragraphs:n";
foreach ($paragraphText as $paragraph) {
echo $paragraph . "n";
}
?>
Methods to course of the online scrapped information
What’s going to folks do with the web-scraped information? The instance code created for this text prints the content material to the browser. In an precise utility, this information can be utilized for a lot of functions.
- It provides information to seek out standard traits with the scraped information website contents.
- It generates leads for displaying charts or statistics.
- It helps to extract photographs and retailer them within the utility’s backend.
If you wish to see learn how to extract photographs from the pages, the linked article has a easy code.
Warning
Internet scrapping is theft should you scrape towards an internet site’s utilization coverage. It’s best to learn an internet site’s coverage earlier than scraping it. If the phrases are unclear, chances are you’ll get specific permission from the web site’s proprietor. Additionally, commercializing web-scraped content material is against the law typically. Get permission earlier than doing any such actions.
Earlier than crawling a website’s content material, it’s important to learn the web site phrases. It’s to make sure that the general public might be topic to scraping.
Individuals present API entry or feed to learn the content material. It’s truthful to do information extraction with correct API entry provision. We’ve got seen learn how to extract the title, description and video thumbnail utilizing YouTube API.
For studying functions, chances are you’ll host a dummy web site with lorem ipsum content material and scrape it.