

Arrange execution failure notifications utilizing Amazon EventBridge
A well-liked service in Amazon Net Companies (AWS), the Elastic Container Service (ECS) permits us to run containerised purposes within the cloud. At a excessive stage, ECS consists of three major assets:
- job definitions to run a number of containers
- companies that execute a number of situations of job definitions
- clusters which group companies and duties collectively

If we need to host an software inside ECS, we could present a service inside a cluster — particularly if we want excessive availability. This can be a notably widespread sample for ECS. Nevertheless, we will take totally different approaches, particularly after we need to run a job on an rare foundation. In such circumstances, we could think about scheduled ECS duties. Invoked by Amazon EventBridge guidelines, scheduled duties usually are not managed by companies.

Following this scheduled job sample, we lose out on many Amazon CloudWatch metrics obtainable out of the field which can be tailor-made particularly to ECS companies. Moreover, there’s no predefined metric for the depend of job execution failures, so how can we configure alerts for such occasions?
Let’s first clarify how we could configure alerts for duties that fail inside a service. After which, let’s talk about why it’s suboptimal, and why it isn’t relevant to scheduled duties. Let’s suggest a greater resolution with a working instance utilizing the AWS Cloud Improvement Equipment (CDK), which might apply to all duties, no matter whether or not they belong to a service.
When a job runs inside a service, we use all three aforementioned useful resource varieties, since duties and companies should be grouped inside a cluster. Default CloudWatch metrics for ECS rely on two dimensions: ClusterName and ServiceName. Each time we need to configure alerts on a service job, we use these dimensions to verify alerts are tailor-made to the right job situations.
Often, a service will host a number of wholesome duties (though the specified depend will be set to 0). To observe this, we graph the variety of operating duties utilizing pre-existing CPUUtilization and MemoryUtilization metrics. If the variety of operating duties falls wanting expectations, this can be a good indication that one thing is mistaken, and we could set alarms to alert us to such circumstances. Take into account that throughout a deployment replace, new duties are provisioned earlier than outdated ones are torn down, so we wouldn’t anticipate our complete variety of service duties to drop beneath the same old quantity at any stage.
While that is helpful for companies, we can not apply the identical resolution to scheduled duties. It’s because scheduled duties don’t belong to a service, and by definition, they don’t have a secure operating depend — we anticipate this to oscillate over time relying on how typically we invoke these duties and the way lengthy they run.
Moreover, there are delays to this alerting technique, since CloudWatch waits till configured analysis durations have handed earlier than elevating the alarm. What if we need to cut back the time between failure occurrences and throwing alerts?
Turning to Amazon EventBridge, not solely does this service invoke scheduled duties, however it could actually additionally handle job state change occasions as effectively. When a container inside a job terminates, this creates an occasion. We will use EventBridge to detect these occasions and set off downstream actions when an occasion matches a given sample. For instance, we could configure a brand new rule inside EventBridge to detect when a container stops and experiences a widespread failure exit code: 1, 137, 139, or 255.
An occasion sample to filter for this standards requires a number of particulars:
- the ECS cluster Amazon Useful resource Title (ARN)
- the duty definition ARN
- the explanation the duty stopped (
Important container in job exited) - the final job standing matching
STOPPED - a number of of the aforementioned widespread failure exit codes
With these particulars offered, an EventBridge sample seems like the next:
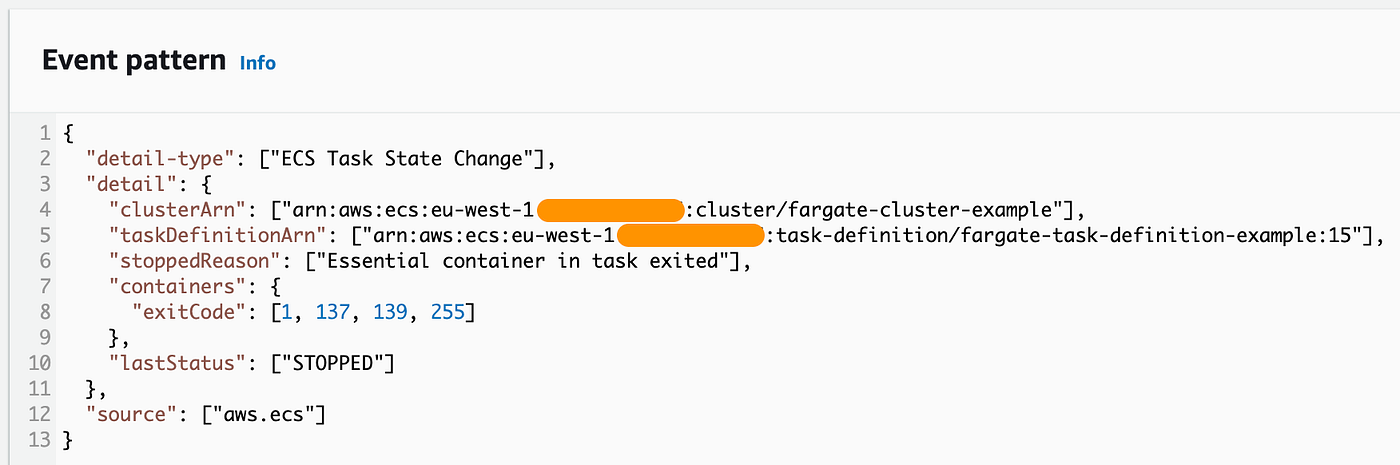
The newly configured rule could then take steps to inform us of job state adjustments utilizing EventBridge targets. This could take many varieties, like electronic mail notifications by way of the Easy Notification Service (SNS), or API locations to ship RESTful API requests.
Be aware that if this rule had been to be utilized to a job inside a service, it could not detect duties terminated throughout a deployment replace. In such circumstances, the stopped cause says “Scaling exercise initiated by deployment,” which doesn’t match our occasion sample. Subsequently, it’s secure to use this with out worry of alerts on each job definition replace.
Given the above suggestion, let’s exhibit a working alert mechanism that we will construct and deploy with CDK. We’ll provision a scheduled ECS job with an EventBridge rule to inform us by electronic mail every time a job execution fails with one of many widespread exit codes. The complete resolution is obtainable on GitHub, however we’ll stroll by way of every part right here and clarify in additional element the way it all hangs collectively.

We begin first with an ECS cluster. That is required for all duties, no matter whether or not they belong to a service. We’ll provision a Fargate job for this instance, which requires us to set enableFargateCapacityProviders.
Subsequent, we outline the job definition. Given we’re utilizing the Fargate launch kind, we require an execution position for this, which is assumed by ECS and grants all required permissions by making use of an AWS-managed service position.
Now we require a container to host our software throughout the job. Assuming we have now a Dockerfile and software code already exists throughout the present listing (see the GitHub repository for an instance), we provision a brand new Docker Picture Asset beneath this listing, and move it to the addContainer methodology. The log driver for AWS CloudWatch is elective right here, however helpful for reviewing any logs produced by the applying.
With all of the ECS infrastructure provisioned, let’s configure an EventBridge rule to invoke the duty. CDK presents this performance out of the field for us (❤ CDK). For the sake of simpler testing, our job is configured to launch each minute utilizing the newest Fargate platform model.
Now we need to replicate the EventBridge job sample shared earlier for the detection of execution failure occasions. This is a bit more cumbersome — a remark is given to justify every of the listed failure exit codes.
This leaves us to determine how finest to be notified of job failures. For this instance, let’s submit matching occasions to an SNS subject and arrange an electronic mail subscription for notifications. The recipient handle could also be set utilizing the ALERT_EMAIL_ADDRESS surroundings variable.
That brings our CDK resolution to a detailed. After we deploy these assets to AWS, our scheduled job ought to invoke each minute with rapid impact. Each time the duty fails throughout execution with an identical exit standing code, the e-mail handle recipient receives a notification of this job failure.
Be aware that this setup shouldn’t be left operating indefinitely — in any other case, a job will spin up each minute and sure spam our electronic mail inboxes with failure notification messages. Bear in mind to tear this down when it’s now not required, or a minimum of disable the EventBridge invocation rule.
Alerts for ECS duties are one thing I’ve thought of a few occasions in the course of the previous few years engaged on AWS. Since I not too long ago revisited this problem, it felt like a worthwhile subject to share with you all. The next served as priceless references for this text:
I hope this serves as a helpful article for anybody working with ECS. Do let me know for those who observe comparable patterns — or take totally different methods altogether! It might be nice to listen to how others configure their job alerts.