The hint of an  matrix is the sum of its diagonal components:
matrix is the sum of its diagonal components: 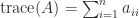 . The hint is linear, that’s,
. The hint is linear, that’s, 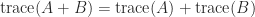 , and
, and 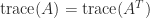 .
.
A key truth is that the hint can be the sum of the eigenvalues. The proof is by contemplating the attribute polynomial 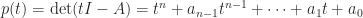 . The roots of
. The roots of  are the eigenvalues
are the eigenvalues 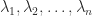 of
of  , so will be factorized
, so will be factorized
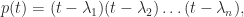
and so 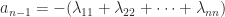 . The Laplace enlargement of
. The Laplace enlargement of 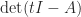 reveals that the coefficient of
reveals that the coefficient of 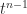 is
is 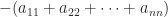 . Equating these two expressions for
. Equating these two expressions for 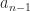 offers
offers
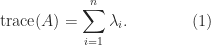
A consequence of (1) is that any transformation that preserves the eigenvalues preserves the hint. Due to this fact the hint is unchanged underneath similarity transformations: 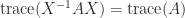 for any nonsingular
for any nonsingular  .
.
An an instance of how the hint will be helpful, suppose is a symmetric and orthogonal matrix, in order that its eigenvalues are 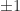 . If there are eigenvalues
. If there are eigenvalues  and
and  eigenvalues
eigenvalues  then
then 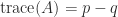 and
and 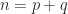 . Due to this fact
. Due to this fact 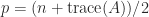 and
and 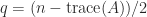 .
.
One other necessary property is that for an 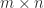 matrix and an
matrix and an 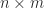 matrix
matrix  ,
,
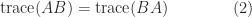
(although  basically). The proof is easy:
basically). The proof is easy:
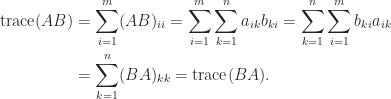
This straightforward truth can have non-obvious penalties. For instance, take into account the equation 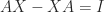 in matrices. Taking the hint offers
in matrices. Taking the hint offers 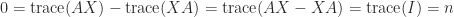 , which is a contradiction. Due to this fact the equation has no resolution.
, which is a contradiction. Due to this fact the equation has no resolution.
The relation (2) offers 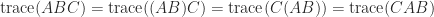 for matrices , , and
for matrices , , and  , that’s,
, that’s,
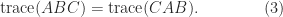
So we will cyclically permute phrases in a matrix product with out altering the hint.
For instance of the usage of (2) and (3), if  and
and  are
are  -vectors then
-vectors then 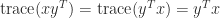 . If is an matrix then
. If is an matrix then 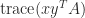 will be evaluated with out forming the matrix
will be evaluated with out forming the matrix 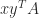 since, by (3),
since, by (3), 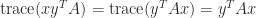 .
.
The hint is helpful in calculations with the Frobenius norm of an matrix:
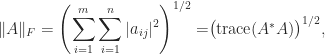
the place  denotes the conjugate transpose. For instance, we will generalize the formulation
denotes the conjugate transpose. For instance, we will generalize the formulation 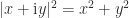 for a fancy quantity to an matrix by splitting into its Hermitian and skew-Hermitian elements:
for a fancy quantity to an matrix by splitting into its Hermitian and skew-Hermitian elements:
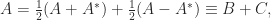
the place 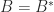 and
and  . Then
. Then
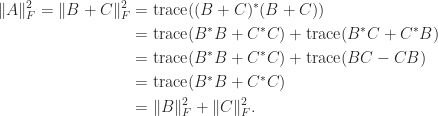
If a matrix is just not explicitly identified however we will compute matrix–vector merchandise with it then the hint will be estimated by
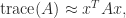
the place the vector has components independently drawn from the usual regular distribution with imply  and variance . The expectation of this estimate is
and variance . The expectation of this estimate is
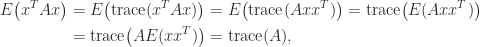
since 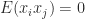 for
for 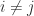 and
and 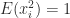 for all
for all  , so
, so 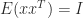 . This stochastic estimate, which is because of Hutchinson, is subsequently unbiased.
. This stochastic estimate, which is because of Hutchinson, is subsequently unbiased.



{kind=link}