


The definition of matrix multiplication says that for 







In 1969 Volker Strassen confirmed that when 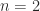

The analysis requires 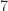
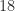


At first sight, Strassen’s formulation might seem merely to be a curiosity. Nevertheless, the formulation don’t depend on commutativity so are legitimate when the 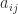

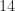


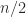
Allow us to look at the variety of multiplications for the recursive Strassen algorithm. Denote by 
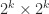
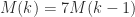

However 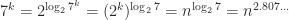
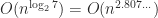
Strassen’s work sparked curiosity to find matrix multiplication algorithms of even decrease complexity. Since there are 
The present document higher certain on the exponent is 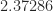
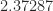

Within the strategies that obtain exponents decrease than 2.775, numerous intricate methods are used, primarily based on representing matrix multiplication by way of bilinear or trilinear varieties and their illustration as tensors having low rank. Laderman, Pan, and Sha (1993) clarify that for these strategies “very giant overhead constants are hidden within the `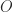
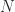
Strassen’s methodology, when rigorously applied, may be sooner than standard matrix multiplication for cheap dimensions. In apply, one doesn’t recur all the way down to 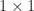

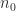
Strassen’s methodology has the downside that it satisfies a weaker type of rounding error certain that standard multiplication. For standard multiplication 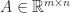


the place 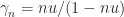

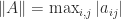
Theorem 1 (Brent). Let
, the place
. Suppose that
is computed by Strassen’s methodology and that
is the brink at which standard multiplication is used. The computed product
satisfies
![notag |C - widehat{C}| le left[ Bigl( displaystylefrac{n}{n_0} Bigr)^{log_2{12}} (n_0^2+5n_0) - 5n right] u |A|, |B| + O(u^2). qquad(2)](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5C%7CC+-+%5Cwidehat%7BC%7D%5C%7C+%5Cle+%5Cleft%5B+%5CBigl%28+%5Cdisplaystyle%5Cfrac%7Bn%7D%7Bn_0%7D+%5CBigr%29%5E%7B%5Clog_2%7B12%7D%7D+++++++++++++++++++++++%28n_0%5E2%2B5n_0%29+-+5n+%5Cright%5D+u+%5C%7CA%5C%7C%5C%2C+%5C%7CB%5C%7C+++++++++++++++++++++++%2B+O%28u%5E2%29.+%5Cqquad%282%29+&bg=ffffff&fg=222222&s=0&c=20201002)
With full recursion (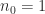
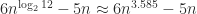
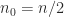

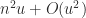
The truth that Strassen’s methodology doesn’t fulfill a componentwise error certain is a big weak point of the strategy. Certainly Strassen’s methodology can not even precisely multiply by the identification matrix. The product
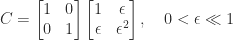
is evaluated precisely in floating-point arithmetic by standard multiplication, however Strassen’s methodology computes

{kind=link}
As a result of 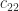
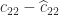

One other weak point of Strassen’s methodology is that whereas the scaling 

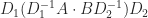
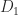


Ought to one use Strassen’s methodology in apply, assuming that an implementation is obtainable that’s sooner than standard multiplication? Not if one wants a componentwise error certain, which ensures correct merchandise of matrices with nonnegative entries and ensures that the column scaling of
Notes
For current work on high-performance implementation of Strassen’s methodology see Huang et al. (2016, 2020).
Theorem 1 is from an unpublished technical report of Brent (1970). A proof may be present in Higham (2002, §23.2.2).
For extra on quick matrix multiplication see Bini (2014) and Higham (2002, Chapter 23).
References
It is a minimal set of references, which comprise additional helpful references inside.
- Josh Alman and Virginia Vassilevska Williams. A refined laser methodology and sooner matrix multiplication. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), Society for Industrial and Utilized Arithmetic, January 2021, pages 522–539.
- Gray Ballard, Austin R. Benson, Alex Druinsky, Benjamin Lipshitz, and Oded Schwartz. Enhancing the numerical stability of quick matrix multiplication. SIAM J. Matrix Anal. Appl, 37(4):1382–1418, 2016.
- Benson, Alex Druinsky, Benjamin Lipshitz, and Oded Schwartz. Enhancing the numerical stability of quick matrix multiplication. SIAM J. Matrix Anal. Appl., 37(4):1382–1418, 2016.
- Dario A. Bini. Quick matrix multiplication. In Handbook of Linear Algebra, Leslie Hogben, editor, second version, Chapman and Corridor/CRC, Boca Raton, FL, USA, 2014, pages 61.1–61.17.
- Bogdan Dumitrescu. Enhancing and estimating the accuracy of Strassen’s algorithm. Numer. Math., 79:485–499, 1998.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second version, Society for Industrial and Utilized Arithmetic, Philadelphia, PA, USA, 2002.
- Jianyu Huang, Tyler M. Smith, Greg M. Henry, and Robert A. van de Geijn. Strassen’s algorithm reloaded. In SC16: Worldwide Convention for Excessive Efficiency Computing, Networking, Storage and Evaluation, IEEE, November 2016.
- Jianyu Huang, Chenhan D. Yu, and Robert A. van de Geijn. Strassen’s algorithm reloaded on GPUs, ACM Trans. Math. Software program, 46(1):1:1–1:22, 2020.
- Julian Laderman, Victor Pan, and Xuan-He Sha. On sensible algorithms for accelerated matrix multiplication. Linear Algebra Appl., 162–164:557–588, 1992.
- François Le Gall. Powers of tensors and quick matrix multiplication. In Proceedings of the thirty ninth Worldwide Symposium on Symbolic and Algebraic Computation, 2014, pages 296–303.
This text is a part of the “What Is” sequence, out there from https://nhigham.com/class/what-is and in PDF kind from the GitHub repository https://github.com/higham/what-is.