


{kind=link}
We might both use “na” or “null” to see the lacking values, however it doesn’t occur instantly. So, including an “any” operate on the finish might help.
Nonetheless, what if we need to know the precise variety of lacking values for a particular column? Effectively, we are able to use “sum” as a substitute of “any,” and we’ll get one thing like this:
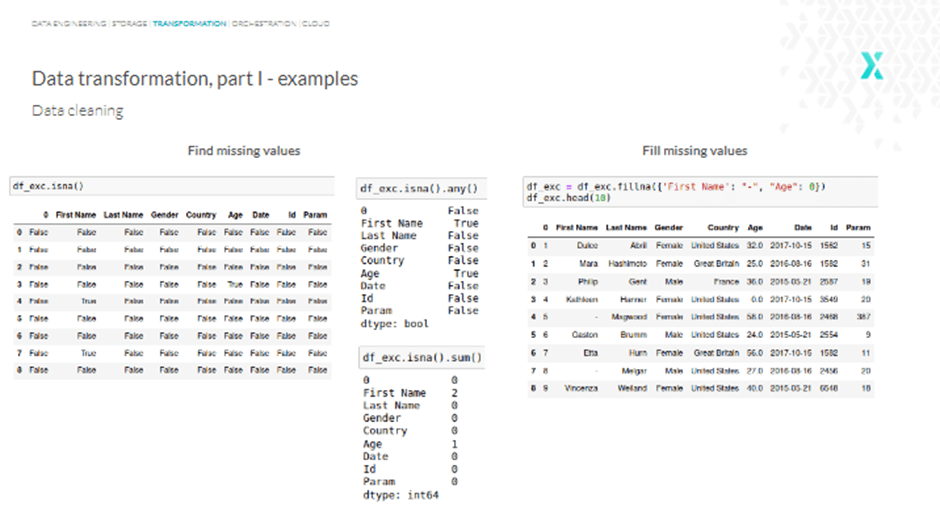
To fill lacking values, use the “fillna” operate, and for all of the lacking names, we get a touch, whereas the lacking age is stuffed with “0.” Alternatively, we are able to additionally use drop rows with at the least one or all NaN (Not a Quantity) values with the operate “dropna,” and so forth.
An excellent higher method to discover and fill lacking values is to make use of Pandas.
In Pandas, lacking information is represented by None and NaN. The assorted features used to detect, take away, and substitute null values in Pandas DataFrame embrace:
Past discovering and filling lacking values, Pandas can carry out features like counting, sums, averages, becoming a member of information, making use of conditioning, and extra. Nonetheless, these are all primary features. So, let’s transfer to one thing greater: Apache Spark.
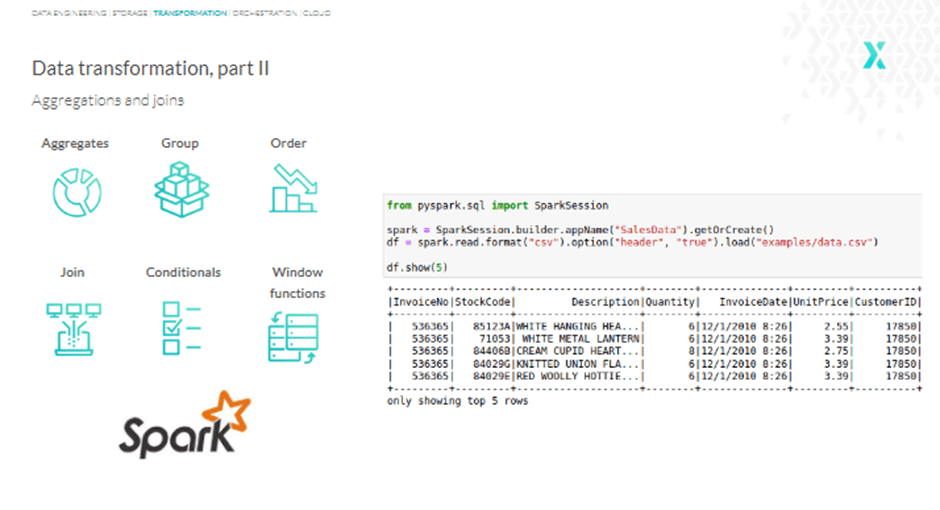
Apache Spark is an especially highly effective and quick analytics engine for giant information and machine studying, notably useful in accessing CSV recordsdata. One other essential use case of Apache Spark is parallel processing; the instrument is designed to course of information in a distributed manner.
Further options embrace lazy analysis and caching intermediate leads to reminiscence. So, if you’re processing or reworking hundreds of thousands or billions of rows directly, Apache Spark with correct infrastructure might be the perfect instrument for the job.

One other instrument we want to deliver to your consideration is Dask, which in distinction to Apache Spark is a pure Python framework and doesn’t intention to be an entire ecosystem.
Dask was constructed as a result of libraries like NumPy or Pandas weren’t initially designed to scale past a single CPU or to work with information that doesn’t match into reminiscence. Dask permits us to effectively run the identical code in parallel, both regionally or on a cluster.
Now, in terms of parallel processing strictly on one machine, Python has a threading and multiprocessing choice.
Threads can’t do issues in parallel, however they’ll do issues concurrently. Meaning they’ll shuttle between issues, and as such are appropriate for IO-bound duties.
However, multiprocessing is designed to do issues in parallel, so it’s handy after we’ve bought CPU-bound duties, like doing aggregations on hundreds of thousands of rows or processing lots of of photographs.