

A extra basic subordinate matrix norm might be outlined by taking totally different vector norms within the numerator and denominator:
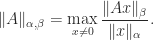
Some authors denote this norm by 
A helpful characterization of 


Theorem 1. For
,
Proof. We’ve
the place the second equality follows from the definition of twin vector norm and the truth that the twin of the twin norm is the unique norm.

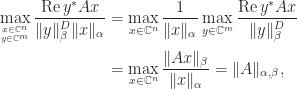
We will now get hold of a connection between the norms of 
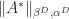
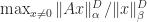
Theorem 2. If
.
Proof. Utilizing Theorem 1, we’ve
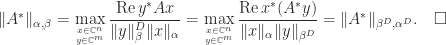
If we take the 
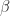


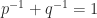
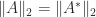

Now we give express formulation for the 


Theorem 3. For
For
,
the place
and if
Proof. For (3),
with equality for
, the place the utmost is attained for
. For (4), utilizing the Hölder inequality,
Equality is attained for an
that offers equality within the Hölder inequality involving the
th row of
.
Turning to (5), we’ve
. The unit dice
, the place
, is a convex polyhedron, so any level inside it’s a convex mixture of the vertices, that are the weather of
. Therefore
implies
after which
Therefore
, however trivially
and (5) follows.
Lastly, if
. Then, utilizing a Cholesky factorization
(which exists even when
Conversely, for
we’ve
so
. Therefore
, utilizing (5).
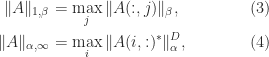

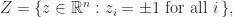




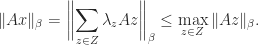

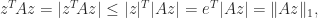

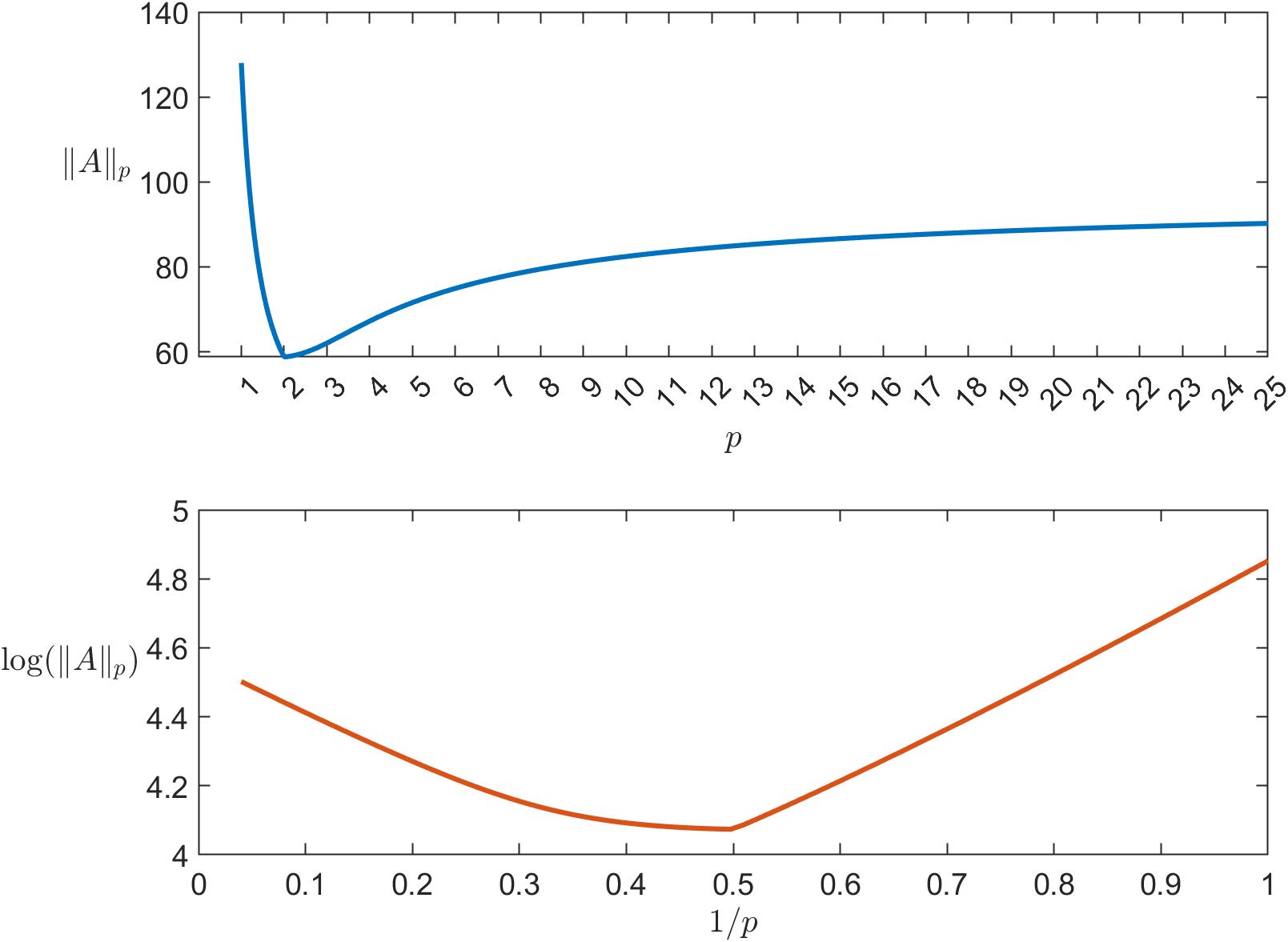
As particular instances of (3) and (4) we’ve
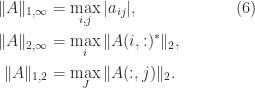
We additionally get hold of by utilizing Theorem 2 and (5), for

The 

the 

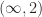

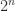

The (
{kind=link}