

{kind=link}
I wrote this text which is what helped me progress ahead with this.
Exterior Apache Hive metastore, Azure Databricks, Azure SQL
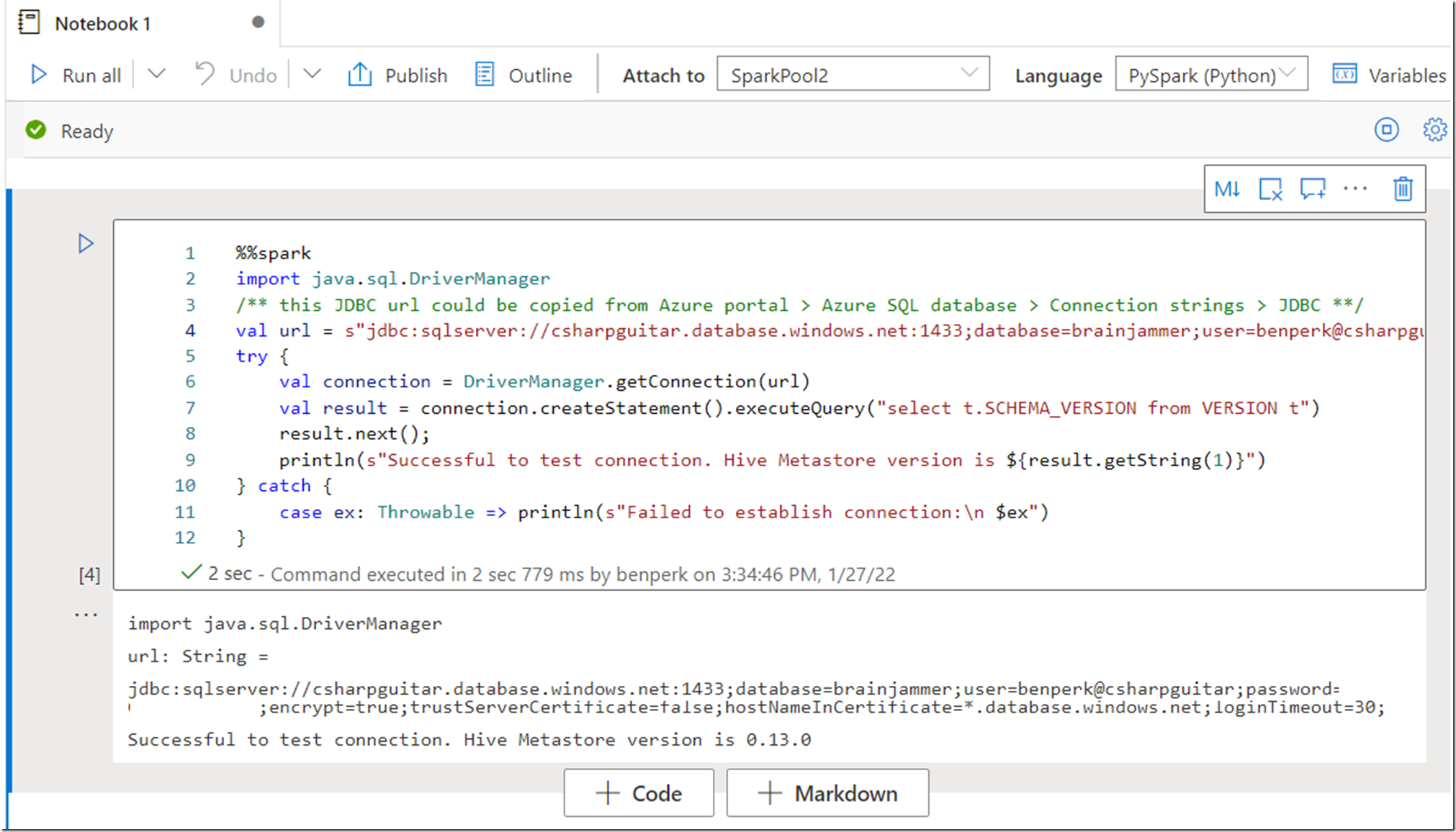
I’m following these directions. Right here is the kicker, which is probably going one thing most individuals could already know, however with the intention to make this configuration the Hive Metastore should exist already on the Azure SQL knowledge you configured as a Linked service. If not, you’re going to get this exception.
import java.sql.DriverManager
Failed to ascertain connection: com.microsoft.sqlserver.jdbc.SQLServerException: Invalid object identify ‘VERSION’.
Whenever you execute the check connection code offered right here.
After I labored the directions for this situation I made a decision to create a brand new Azure SQL database which was empty to make use of as my metastore. That’s after I skilled the difficulty talked about above. Since I created a Hive Metastore in Azure Databricks which I documented right here, after I modified the connection string within the check code to that database, it labored.

Determine 1, testing Azure SQL Hive Metastore from an Azure Synapse Analytics Spark Pool
However after I tried to run spark.sql(“present databases”).present() I acquired this exception.
AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
The explanation was I configured my Linked service to the database which didn’t have the prevailing Hive Metastore. As soon as I fastened that one, it was all good.
