

{kind=link}
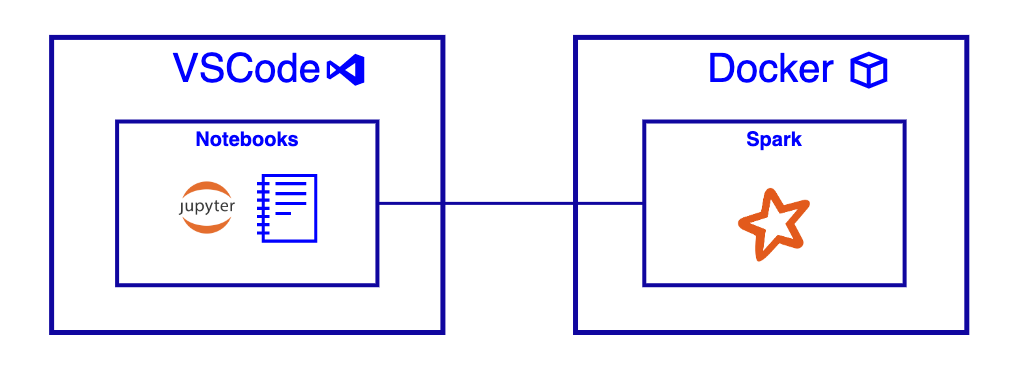
Utilizing VS Code, Jupyter Notebooks, and Docker
A number of weeks again, I used to be looking for that holy grail of a tutorial describing learn how to use VS Code with Jupyter Notebooks and PySpark… on a Mac. And surprisingly, I couldn’t discover any. Effectively, none that handed my “explain-it-like-I’m-five” litmus check.
This text is the results of an agonizing Saturday afternoon.
Nowadays I’ve little or no, if any, free time for enjoying round with new tech. Once I do, I would like it to be as painless as attainable. And most significantly, I would like it to be enjoyable — in any other case, why trouble?
Furthermore, nothing is worse than losing hours of your free time configuring a growth setting. It’s simply painful.
VS Code with Jupyter Notebooks
I’m an enormous fan of REPLs for fast growth — for instance, evaluating a brand new framework, analysing knowledge, knowledge fixes, and many others.
In these conditions, I don’t wish to configure a brand new undertaking and get slowed down with trivial set-up complexities. I merely want a scratchpad to thrash out some code.
Jupyter Notebooks are a REPL-based system designed to analyse, visualise, and collaborate on knowledge. They’re additionally nice as a scratchpad.
What’s a REPL?
A learn–eval–print loop (REPL), additionally termed an interactive prime degree or language shell, is a straightforward interactive pc programming setting that takes single person inputs, executes them, and returns the consequence to the person; a program written in a REPL setting is executed piecewise.
Wikipedia
Visible Studio code has native help for Notebooks, together with Jupyter.
Conditions
- Set up Docker
In the event you’re utilizing a Mac and can’t set up Docker Desktop as a consequence of licensing restrictions, try Colima. - Set up VS Code
VS Code Growth Container
- Create a brand new listing on your undertaking.
- Create a Docker file throughout the root of the undertaking listing utilizing the code under. On the time of scripting this, the present PySpark model is 3.3.0. I might examine right here to make sure you’re utilizing the newest model.
3. Create a listing with the identify .devcontainer.
4. Inside the .devcontainer listing, add the next JSON configuration.
5. On the underside left nook of VS Code, click on the Open Distant Window button → Open In Container.
Click on right here to study extra about distant growth inside VS Code.
VS Code will restart the IDE and connect with the VS Code growth container — instantiated from the Docker picture outlined in step 2.
That’s it for the setup.
Making a pocket book
- Create a brand new file inside your undertaking listing with the extension .ipynb.
- Open the file — you must see the VS Code pocket book expertise.
Check knowledge
- Inside the root listing, add a brand new folder referred to as knowledge.
- Inside the knowledge listing, create a brand new CSV file referred to as
customers.csvand add the information under:
Instance: Spark software
This part assumes you’ve put in Docker, configured a VS Code growth container, and created an empty pocket book.
OK, let’s break this down cell by cell.
- Import Libraries: The primary cell imports the PySpark and Pandas Python libraries.
- Connection to Spark: The second cell is the place we outline the connection to Spark. As we’re operating in native mode, we don’t want to fret a couple of connection string.
- Studying CSV right into a Temp View: Within the third cell, we ingest a CSV file from the native file system into Spark — the CSV comprises check knowledge.
The second step creates a brief view referred to as ‘customers’ — this enables us to question the desk utilizing plain previous SQL. - Question: Within the final cell, we outline a SQL question that may return the common age of all customers by gender. The operate name toPandas(), converts the Spark dataframe to Panda’s dataframe — permitting us to make use of VS Code’s dataframe rendering.

5. Click on Run All on the prime to execute all cells throughout the pocket book. If it really works, you must see a two-row dataframe — as depicted within the picture above.
Utilizing Visible Studio code with Jupyter notebooks and Docker is a straightforward solution to get began with PySpark.
When you’ve got any ideas for bettering the event workflow outlined above, please let me know within the feedback.
I hope you discovered this attention-grabbing.
The Yam Yam Architect.
Please comply with me for extra content material.