


{kind=link}
Many internet and cellular functions could make use of AWS companies and infrastructure to log or ingest knowledge from buyer actions and behaviors on the web sites or cellular apps, to offer suggestions for higher person expertise. There are a number of ‘infrastructure as code’ frameworks obtainable in the present day, to assist clients outline their infrastructure, such because the AWS CDK or Terraform by HashiCorp. On this weblog, we’ll stroll you thru a use case of logging buyer habits knowledge on web-application and can use Terraform to mannequin the AWS infrastructure.
Terraform by HashiCorp, an AWS Associate Community (APN) Superior Expertise Associate and member of the AWS DevOps Competency, is an infrastructure as code instrument much like AWS CloudFormation that permits you to create, replace, and model your Amazon Internet Companies (AWS) infrastructure. Terraform present pleasant syntax (much like AWS CloudFormation) together with different options like planning (visibility to see the adjustments earlier than they really occur), graphing, create templates to interrupt configurations into smaller chunks to prepare, keep and reusability. We are going to leverage the capabilities and options of Terraform to construct an API primarily based ingestion course of into AWS. Let’s get began!
We are going to present the Terraform infrastructure definition and the supply code for an API primarily based ingestion software system for web sites and functions to push person interactions, reminiscent of person clicks on their web site into database hosted on AWS. The info ingestion course of is uncovered with an API Gateway endpoint. The Amazon API Gateway processes the incoming knowledge into an AWS Lambda throughout which the system validates the request utilizing a Lambda Authorizer and pushes the information to a Amazon Kinesis Information Firehose. The answer leverages Firehose’s functionality to transform the incoming knowledge right into a Parquet file (an open supply file format for Hadoop) earlier than pushing it to Amazon S3 utilizing AWS Glue catalog. Moreover, a transformational/shopper lambda does extra processing by pushing it to Amazon DynamoDB.
The info hosted in Amazon S3 (Parquet file) and DynamoDB will be finally used for producing studies and metrics relying on buyer wants, reminiscent of monitor person expertise, habits and supply higher suggestions on their web site. Per the wants for scale of the appliance you need to use Amazon Kinesis and Amazon Kinesis Firehose Streams individually or together to scale, ingest and course of your incoming knowledge quicker and value effectively. For instance, AWS Lambda now helps the Kinesis Information Streams (KDS) enhanced fan-out and HTTP/2 knowledge retrieval options for Kinesis occasion sources. The HTTP/2 knowledge retrieval API improves the information supply pace between knowledge producers and Lambda capabilities by greater than 65%. This characteristic is obtainable wherever AWS Lambda is obtainable. Seek advice from greatest practices on find out how to scale functions that ingest knowledge through Kinesis Streams and different use instances for utilizing AWS API Gateway with Lambda Authorizers.
The next steps present an summary of this implementation:
- Java supply construct – Offered code is packaged & construct utilizing Apache Maven
- Terraform instructions are initiated (supplied beneath) to deploy the infrastructure in AWS.
- An API Gateway, S3 bucket, Dynamo desk, following Lambdas are constructed and deployed in AWS —
- Lambda Authorizer – This lambda validates the incoming request for header authorization from API gateway to processing lambda.
- ClickLogger Lamba – This lambda processes the incoming request and pushes the information into Firehose stream
- Transformational Lambda – This lambda listens to the Firehose stream knowledge and processes this to DynamoDB. In actual world these lambda can extra extra filtering, processing and so on.,
- As soon as the information “POST” is carried out to the API Gateway uncovered endpoint, the information traverses by the lambda and Firehose stream converts the incoming stream right into a Parquet file. We use AWS Glue to carry out this operation.
- The incoming click on logs are finally saved as Parquet information in S3 bucket and moreover within the DynamoDB
- Ensure to have Java put in and working in your machine. For directions, see Java Growth Package
- Apache Maven – Java Lambdas are constructed utilizing mvn packages and are deployed utilizing Terraform into AWS
- Arrange Terraform. For steps, see Terraform downloads
- An AWS Account
At a high-level, listed here are the steps you’ll comply with to get this resolution up and working.
- Obtain the code and carry out maven package deal for the Java lambda code.
- Run Terraform command to spin up the infrastructure.
- Use a instrument like Postman or browser primarily based extension plugin like “RestMan” to publish a pattern request to the uncovered API Gateway endpoint
- In AWS Console, verify that course of runs after the API Gateway is triggered. Discover the parquet file is created in S3 bucket and corresponding row is triggered within the DynamoDB Desk.
- As soon as the code is downloaded, please take a second to see how Terraform offers the same implementation for spinning up the infrastructure like that of AWS CloudFormation. It’s possible you’ll use Visible Studio Code or your favourite selection of IDE to open the folder (aws-ingesting-click-logs-using-terraform).
Downloading the Supply Code
The supplied supply code consists of the next main parts —(Seek advice from corresponding downloaded path on the supplied beneath)
- Terraform templates to construct the infrastructure – aws-ingesting-click-logs-using-terraform/terraform/templates/
- Java Lambda code as a part of assets for Terraform to construct – aws-ingesting-click-logs-using-terraform/supply/clicklogger
Deploying the Terraform template to spin up the infrastructure
When deployed, Terraform creates the next infrastructure.

Provision AWS infrastructure utilizing Terraform (By HashiCorp): an instance of internet software logging buyer knowledge
You may obtain the supply from the GitHub location. Under steps will element utilizing the downloaded code. This has the supply code for Terraform templates that spins up the infrastructure. Moreover, Java code is supplied that creates Lambda. You may optionally use the beneath git command to clone the repository as beneath$ git clone https://github.com/aws-samples/aws-ingesting-click-logs-using-terraform/
$ cd aws-ingesting-click-logs-using-terraform
$ cd sourceclicklogger
$ mvn clear package deal
$ cd ..
$ cd ..
$ cd terraformtemplates
$ terraform init
$ terraform plan
$ terraform apply --auto-approve
As soon as the previous Terraform instructions full efficiently, take a second to establish the most important parts which are deployed in AWS.
- API Gateway
- Click on-logger-api
- Technique – POST
- Technique Request – clicklogger-authorizer
- Integration Request – Lambda
- Authorizer – clicklogger -authorizer
- Stage – dev
- Click on-logger-api
- AWS Lambda
- Clickloggerlambda
- Clickloggerlambda-authorizer
- Clicklogger-lambda-stream-consumer
- Amazon Kinesis Information Firehose
- Supply stream – click-logger-firehose-delivery-stream
- S3
- Click on-logger-firehose-delivery-bucket-<your_account_number>
- Dynamo Desk
- CloudWatch – Log Teams
- /aws/kinesis_firehose_delivery_stream
- /aws/lambda/clickloggerlambda
- /aws/lambda/clickloggerlambda-stream-consumer
- /aws/lambda/clickloggerlambda-authorizer
- API-Gateway-Execution-Logs_<guid>
Testing: publish a pattern request to the uncovered API Gateway endpoint
- In AWS Console, choose API Gateway. Choose click-logger-api
- Choose Phases on the left pane
- Click on dev > POST (throughout the /clicklogger route)
- Copy the invoke Url. A pattern url shall be like this – https://z5xchkfea7.execute-api.us-east-1.amazonaws.com/dev/clicklogger
- Use REST API instrument like Postman or Chrome primarily based internet extension like RestMan to publish knowledge to your endpoint
Add Header: Key Authorization with worth ALLOW=ORDERAPP. That is the authorization key token utilized by the lambda. This may be modified within the lambda.tf. In exterior going through internet functions, be certain that so as to add extra authentication mechanism to limit the API Gateway entry
Pattern Json Request:
{
"requestid":"OAP-guid-12345-678910",
"contextid": "OAP-guid-1234-5678",
"callerid": "OrderingApplication",
"element": "login",
"motion": "click on",
"sort": "webpage"
}{
“requestid”:”OAP-guid-12345-678910″,
“contextid”: “OAP-guid-1234-5678”,
“callerid”: “OrderingApplication”,
“element”: “login”,
“motion”: “click on”,
“sort”: “webpage”
}
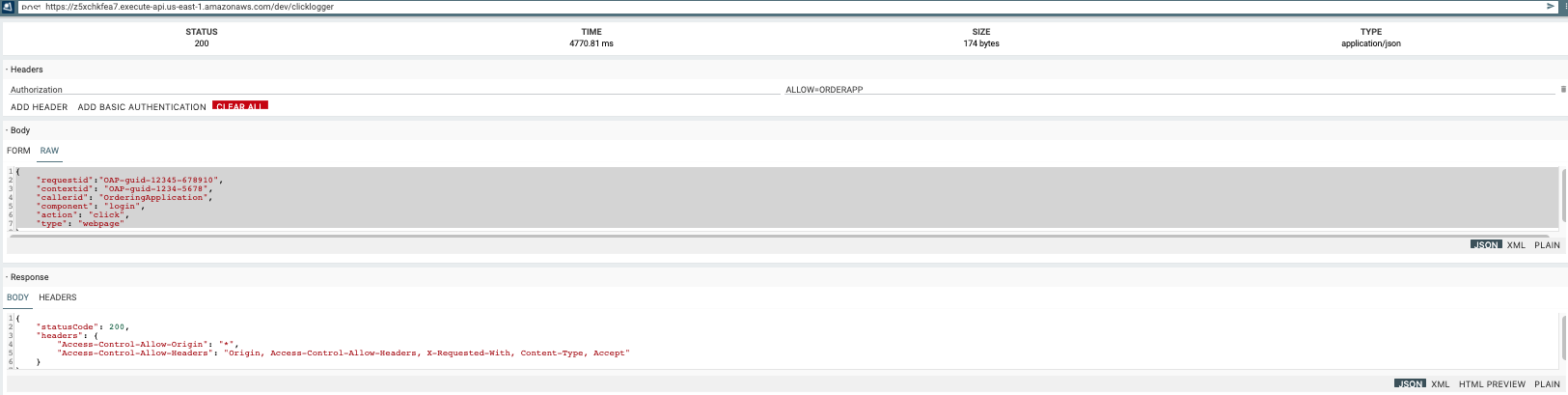
- It’s best to see the output in each S3 bucket and DynamoDB
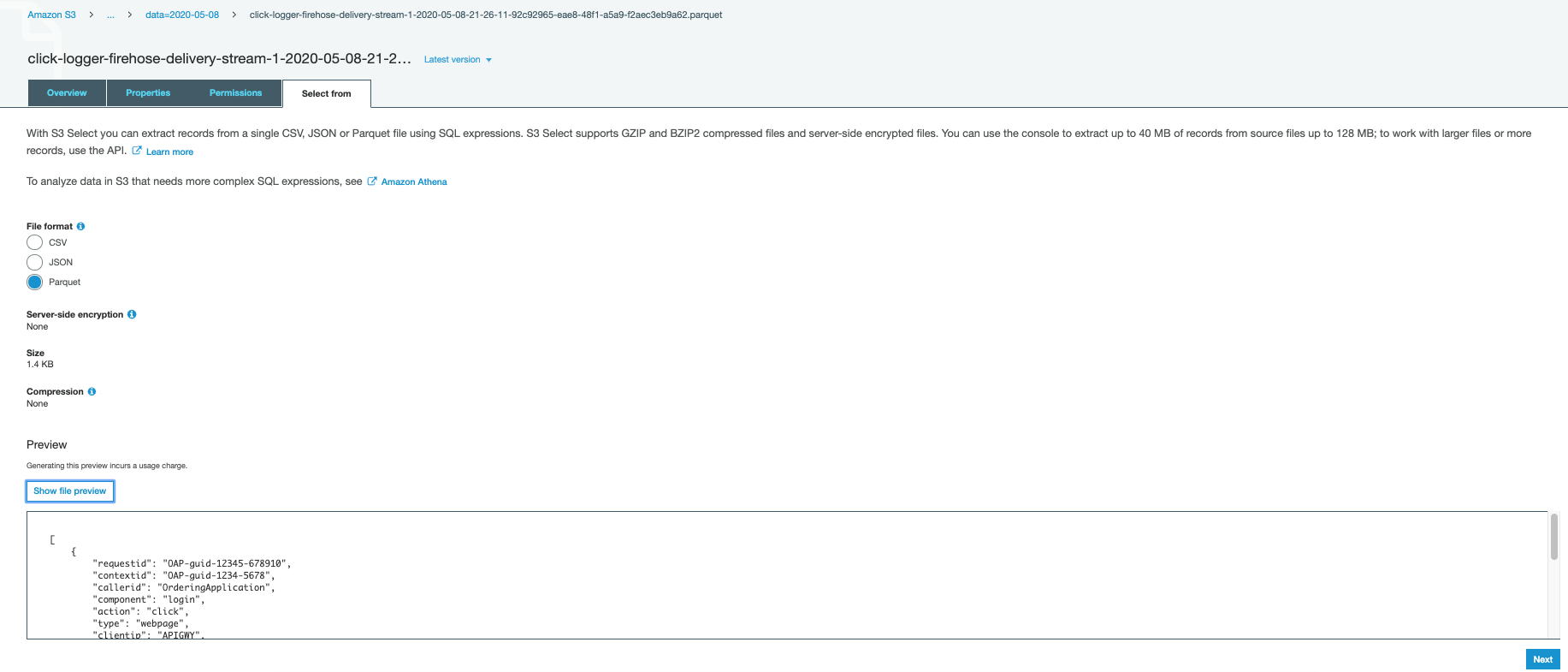
- S3 – Navigate to the bucket created as a part of the stack
- Choose the file and examine the file from Choose From sub tab . It’s best to see one thing ingested stream received transformed into parquet file.
- Choose the file. An instance shall be like beneath
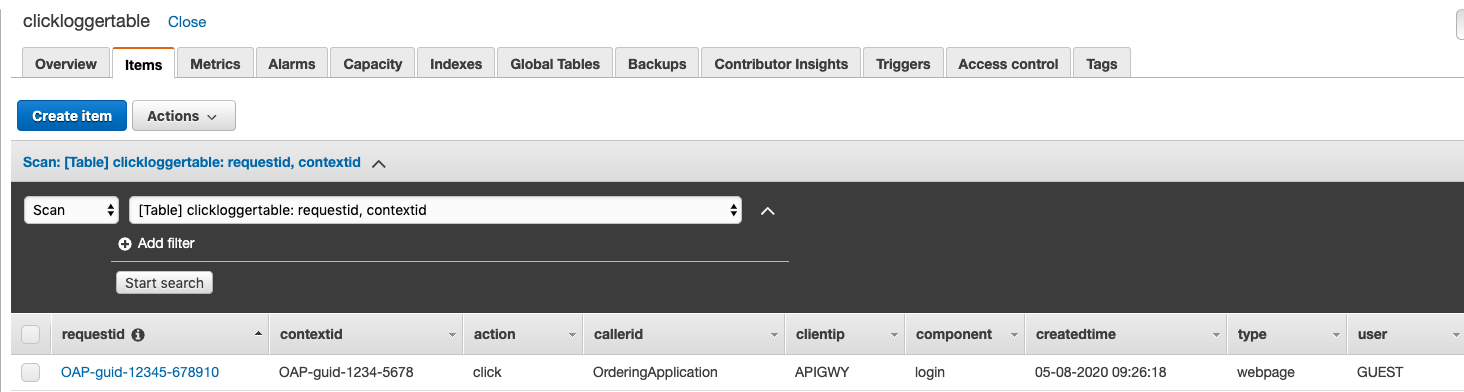
- DynamoDB desk —Choose clickloggertable and examine the objects to see knowledge.
Pattern screenshot
Clear up directions
Terraform destroy command will delete all of the infrastructure that had been deliberate and utilized. For the reason that S3 may have parquet file generated, be certain that to delete the file earlier than initiating the destroy command. This may be executed both in AWS Console or utilizing AWS CLI (instructions supplied). See each choices beneath
- Clear up assets from the AWS Console
- Open AWS Console, choose S3
- Navigate to the bucket created as a part of the stack
- Delete the S3 bucket manually
- Clear up assets utilizing AWS CLI
# CLI Instructions to delete the S3
$ aws s3 rb s3://click-logger-firehose-delivery-bucket-<your-account-number> --force
$ terraform destroy –-auto-approveYou had been in a position to launch an software course of involving Amazon API Gateway which built-in with numerous AWS companies. The publish walked by deploying a lambda packaged with Java utilizing maven. It’s possible you’ll use any mixture of relevant programming languages to construct your lambda capabilities. The pattern supplied has a Java code that’s packaged for Lambda Perform.
For the authorization of the move, we used Lambda Authorizer with header primarily based token mechanism. Ensure to make use of extra authentication mechanisms additionally limit the API Gateway to particular shoppers/software. AWS Glue catalog is used to deal with the incoming knowledge and is transformed into parquet information. This may be carried out with CSV/Json and/or in different codecs additionally. The weblog offers an structure to stream the information into AWS infrastructure. The info will be even sourced to Amazon Elastic Search Service, Amazon Redshift or Splunk primarily based on particular wants. This may be finally used for reporting or visualization
In case you resolve to provide it a attempt, have any doubt, or need to let me know what you consider the publish, please go away a remark!
 Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Utility Architect at AWS. His experience is in software optimization, serverless options and utilizing Microsoft software workloads with AWS.
Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Utility Architect at AWS. His experience is in software optimization, serverless options and utilizing Microsoft software workloads with AWS.