


At current, one of many fifth corporations is transferring to Large information analytics. Therefore, demand for giant information analytics is rising like something. Due to this fact, if you wish to enhance your profession, Hadoop and Spark are simply the expertise you want. This might all the time provide you with a very good begin both as a more energizing or skilled.
Previously, I’ve shared many assets to study Large Information like these free Large Information programs as nicely these greatest Large Information programs and on this article, I’m simply specializing in Large Information interview questions. When you’ve got labored in Large Information then you possibly can simply reply these questions however in case you can not then it make sense to study or revise important Large Information ideas by becoming a member of considered one of these programs.
10 Large Information and Hadoop Interview Questions with Solutions
Getting ready for the interview is the most effective factor that you’re going to get from this tutorial. We’ll talk about largely 10 questions which are associated to huge information. If you wish to enhance your profession, Hadoop and Spark are simply the expertise you want. This might all the time provide you with a very good begin both as a more energizing or skilled.
1. What’s the distinction between relational databases and HDFS?
Listed below are the important thing distinction between a Relational Database and HDFS:
1. Relational databases depend on structured information and the schema of the information is all the time identified.
2. RDMS reads are quick as a result of the schema of the information is already identified.
3. RDBMS relies on ‘schema on write’ the place schema validation is completed earlier than loading the information.
4. RDBMS offers restricted or no processing capabilities.
1. Hadoop depends on each structured and unstructured information. (any form of information)
2. No schema validation occurs within the course of, so Hadoop can also be quick.
3. Hadoop follows the schema on studying coverage
4. Hadoop permits us to course of the information which is distributed throughout the cluster in a parallel style.
2. Clarify what’s Large Information and 5 V’s of massive information?
Large information is a set of huge information units, which makes it tough to course of utilizing relationship administration instruments or conventional information processing instruments. It’s tough to seize, switch, analyze and visualize huge information.
So let’s take a look on the 5V’s in such questions.
1. Quantity – The amount displays the quantity of knowledge that’s exponentially growing.
2. Velocity – The speed at which information grows, which is extraordinarily quick, is known as velocity. Information from yesterday is taken into account outdated information right this moment.
3. Selection – The heterogeneity of knowledge sorts is known as selection. In different phrases, the information collected may be in numerous codecs, reminiscent of motion pictures, audios, csv, and so forth.
4. Veracity – As a result of information inconsistency and incompleteness, veracity refers to information that’s in dispute or uncertain.
5. Worth – Want so as to add worth for the information to get advantages to the group. So it will add extra advantages to the group.
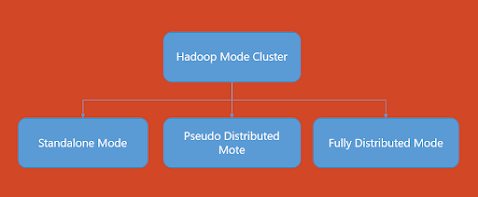
3. In what all modes Hadoop may be run?
Hadoop’s default mode is standalone, which makes use of a neighborhood file system for enter and output operations. This mode is primarily supposed for debugging and doesn’t help using HDFS. As well as, the mapred-site.xml, core-site.xml, and hdfs-site.xml recordsdata don’t require any distinctive setting on this mode. When in comparison with different settings, this one operates a lot quicker.
Pseudo-distributed mode (Single-node Cluster): On this scenario, all three recordsdata indicated above should be configured. All daemons are working on one node on this situation, subsequently each the Grasp and Slave nodes are the identical.
Absolutely distributed mode (Multi-node Cluster): That is the Hadoop manufacturing section, the place information is used and distributed over a number of nodes on a Hadoop cluster. Grasp and Slave nodes are assigned individually.
4. What’s HBase?
Apache HBase is a Java-based distributed, open-source, scalable, and multidimensional NoSQL database. It runs on HDFS and offers Hadoop Google BigTable-like capabilities and performance.
5. Why is it essential to delete or add nodes from a Hadoop cluster frequently?
The Hadoop framework’s use of commodity {hardware} is considered one of its most interesting elements. In a Hadoop cluster, nonetheless, this leads to frequent “DataNode” crashes. One other notable characteristic of the Hadoop Framework is its capability to scale in response to vital will increase in information quantity.
6. What are the variations between Hadoop and Spark?
If you have to discover information shortly, Spark SQL is the best way to go. In case you want complicated processing utilizing numerous instruments that function on datasets in parallel, reminiscent of Hive and Pig, and need to mix them, Hadoop is the best way to go.
Hadoop is a system for processing large quantities of knowledge utilizing fundamental programming ideas throughout clusters of machines. It may be run on normal PC {hardware}. All the things you have to transport and retailer your information is included within the framework, together with machine studying, search indexing, and warehousing providers (storage).
7. What’s a Zookeeper?
It manages and co-ordinate Kafka cluster, preserve data of when a dealer enter or depart cluster or dies.
9. What’s Map Cut back in Hadoop?
10. When to make use of MapReduce with Large Information?
That is all in regards to the frequent Large Information and Hadoop Interview Questions. I do know that I’ve not share many questions however that is only a begin, I’m feeling bit lazy now so I made a decision to publish this text and later replace it in any other case it’s going to stay within the draft state for years. You may also simply discover solutions of final 4 questions on-line however in case you battle, simply ask in feedback and I’ll add it together with extra questions. When you’ve got even have Large information and Hadoop questions which was requested to you throughout interviews be happy to share with us.
All the most effective together with your interview.
Different Java Interview Questions you could like to arrange
Thanks loads for studying this text to date. In case you like these Large Information and Hadoop Questions then please share together with your
buddies and colleagues. When you’ve got any questions which isn’t answered
right here, be happy to ask in feedback, I’ll strive my greatest to reply your
doubts.
P. S. – If you wish to study the Apache Kafka platform and Large Information in depth then it’s also possible to checkout these greatest Large Information Programs for Java builders to start out with. It isn’t free however
fairly inexpensive, and you should purchase it for simply $10 on Udemy
gross sales.