


{kind=link}
Probably the most thrilling options in ColdFusion is the flexibility to iterate over collections utilizing parallel threads. When consuming giant quantities of knowledge, parallel threads can have a dramatic influence on efficiency. However, spawning threads is not free—and, in some instances, spawning threads is much more costly than you notice. Due to this price, one factor that I’ve all the time needed to check is the efficiency of straight parallel iteration in contrast chunked parallel iteration in Lucee CFML.
Think about an array that has 100 parts in it. If we use ColdFusion’s parallel iteration to iterate over this array utilizing a most of 10 threads, ColdFUsion will nonetheless spawn 100 threads; however, solely permit 10 of them to exist on the similar time.
Now, take into account taking that very same array and first splitting into 10 chunks of 10 parts. If we use ColdFusion’s parallel iteration to iterate over the chunks utilizing a most of 10 threads, ColdFusion will solely find yourself spawning 10 threads. However, inside every thread, we’ll have to make use of synchronous, blocking iteration to course of every factor.
So the query is, which is quicker: spawning 100 threads and performing all work asynchronously? Or, spawning 10 threads and performing plenty of the work synchronously (in parallel chunks)?
I am certain that this query is definitely fairly a bit extra sophisticated than I notice. And, I am certain that there is plenty of “it relies upon” that one may apply to real-world implications of a check like this. However, I simply wish to get a basic “ball park” sense of how these two approaches examine. Take my outcomes as nothing greater than an anecdote.
To check this, I created a small CFML web page (goal.cfm) that sleeps for 25 milliseconds after which returns a parameterized textual content worth:
<cfscript>
param identify="url.i" sort="numeric";
sleep( 25 );
cfcontent(
sort = "textual content/plain; charset=utf-8",
variable = charsetDecode( "World #i#", "utf-8" )
);
</cfscript>
This web page might be consumed by way of an HTTP request utilizing ColdFusion’s digital file system (VFS) conduct. That’s, I will be utilizing the built-in fileRead() operate to entry this file utilizing a path with an http:// scheme:
http://#cgi.http_host#/parallel-strategy/goal.cfm
In my first check, I’ll make 10,000 requests to this goal.cfm web page utilizing 10 parallel threads:
<cfscript>
embrace "./utilities.cfm";
values = generateValues( "Hey", 10000 );
stopwatch variable = "durationMs" {
// In Take a look at-1, we'll use parallel iteration to loop over your complete values
// assortment. This may trigger Lucee CFML to spawn a thread for every factor in
// the array.
outcomes = values.map(
( worth, i ) => {
return fileRead( "#targetUrl#?i=#i#" ); // HTTP (sleep 25).
},
true, // Parallel iteration.
10 // Max threads.
);
}
echo( "<h1> Parallel Iteration </h1>" );
dump( numberFormat( durationMs ) );
dump( var = outcomes, high = 10 );
</cfscript>
This check usually accomplished in round 80-90 seconds.
In my second check, I am additionally making 10,000 requests to goal.cfm; nonetheless, this time, I will first cut up the array into 10 chunks, every with 1,000 factor. Then, I will use 10 parallel threads—one per chunk—wherein I make 1,000 synchronous HTTP requests inside every thread context:
<cfscript>
embrace "./utilities.cfm";
values = generateValues( "Hey", 10000 );
stopwatch variable = "durationMs" {
// In Take a look at-2, we'll first cut up the values array into chunks. Then, we'll
// use parallel iteration to loop over the chunks; however, we'll use synchronous,
// blocking iteration to loop over the values inside every chunk. This may scale back
// the variety of threads that Lucee CFML has to spawn.
// --
// Notice: I am utilizing a chunk-size that matches the max-thread configuration within the
// parallel iteration.
outcomes = splitIntoChunks( values, 10 ).map(
( chunk, c ) => {
// Synchronous iteration / mapping all throughout the present thread.
return chunk.map(
( worth, i ) => {
return fileRead( "#targetUrl#?i=#c#:#i#" ); // HTTP (sleep 25).
}
);
},
true, // Parallel iteration.
10 // Max threads.
);
}
echo( "<h1> Chunked Parallel Iteration </h1>" );
dump( numberFormat( durationMs ) );
dump( var = outcomes, high = 10 );
</cfscript>
This check usually accomplished in round 9-12 seconds.
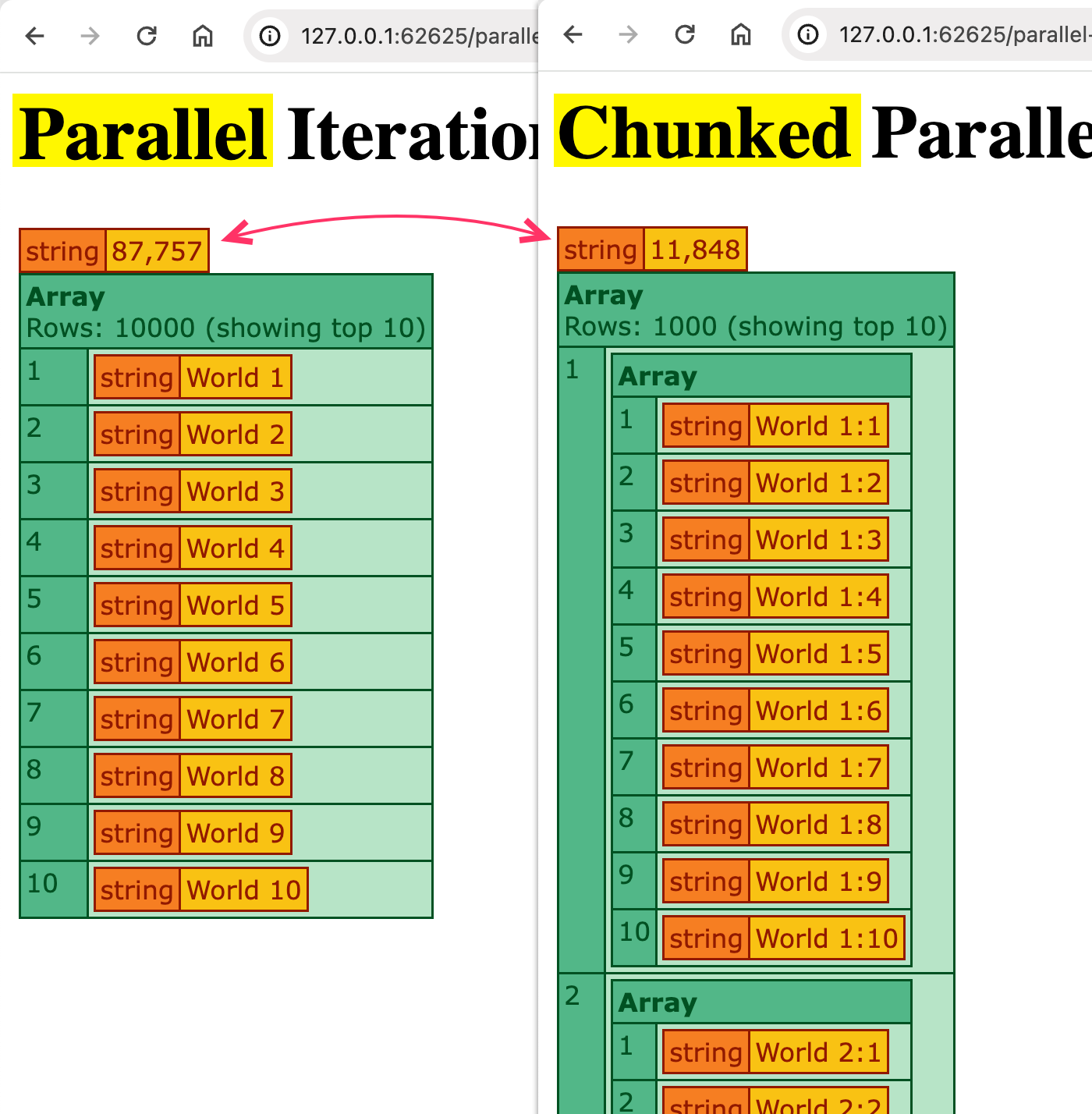
This can be a fairly important distinction. The chunked parallel iteration was about 7 occasions quicker than the plain parallel iteration.
To be clear, I am not saying that chunked parallel iteration is all the time quicker or higher than plain parallel iteration. The outcomes right here will nearly actually range based mostly on what logic you’ve gotten inside every thread; and, what the latency of the blocking operations are; and the way gradual they’re relative to the price of spawning a thread.
The actual take-away right here is that there is is not a one-size-fits-all method to parallel iteration. Generally, plain iteration goes to be the way in which to go; and, generally, chunked iteration goes to be the way in which to go. As all the time, it is essential to think about the context after which measure, check, and iterate (no pun meant)!
For completeness, this is the code for the utilities.cfm CFML template that I used to be together with on the high of every check:
<cfscript>
setting
requestTimeout = ( 5 * 60 )
;
targetUrl = "http://#cgi.http_host#/parallel-strategy/goal.cfm";
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I generate an array of the given dimension.
*/
public array operate generateValues(
required string worth,
required string depend
) {
var values = [].set( 1, depend, worth );
return values;
}
/**
* I cut up the given array into chunks of a most dimension.
*/
public array operate splitIntoChunks(
required array values,
required numeric maxSize
) {
var chunks = [];
var chunk = [];
var chunkSize = 0;
for ( var worth in values ) {
chunk.append( worth );
if ( ++chunkSize >= maxSize ) {
chunks.append( chunk );
chunk = [];
chunkSize = 0;
}
}
if ( chunkSize ) {
chunks.append( chunk );
}
return chunks;
}
</cfscript>
Additionally, why does not CFML have a flatMap() operate?! I would like to see ColdFusion simply bulk-up the variety of strategies out there in the usual library.
Need to use code from this publish?
Try the license.
https://bennadel.com/4661