

{kind=link}
A few years in the past I’ve re-posted a Stack Overflow reply with Python code for a terse prime sieve
operate that generates a probably infinite sequence of prime
numbers (“probably” as a result of it will run out of reminiscence finally). Since
then, I’ve used this code many occasions – largely as a result of it is quick and clear. In
this put up I’ll clarify how this code works, the place it comes from (I did not come
up with it), and a few potential optimizations. If you’d like a teaser, right here it’s:
def gen_primes():
"""Generate an infinite sequence of prime numbers."""
D = {}
q = 2
whereas True:
if q not in D:
D[q * q] = [q]
yield q
else:
for p in D[q]:
D.setdefault(p + q, []).append(p)
del D[q]
q += 1
The sieve of Eratosthenes
To know what this code does, we should always first begin with the fundamental Sieve
of Eratosthenes; if you happen to’re aware of it, be at liberty to skip this part.
The Sieve of Eratosthenes is a widely known
algorithm from historical Greek occasions for locating all of the primes beneath a sure
quantity fairly effectively utilizing a tabular illustration. This animation
from Wikipedia explains it fairly properly:
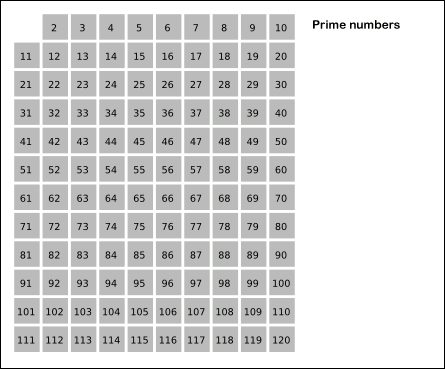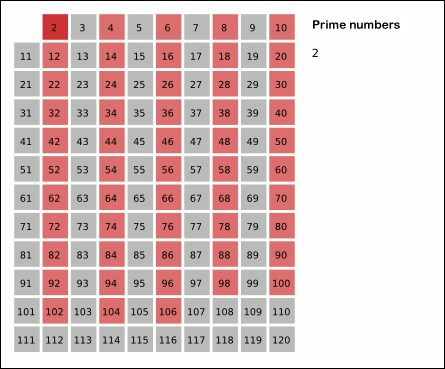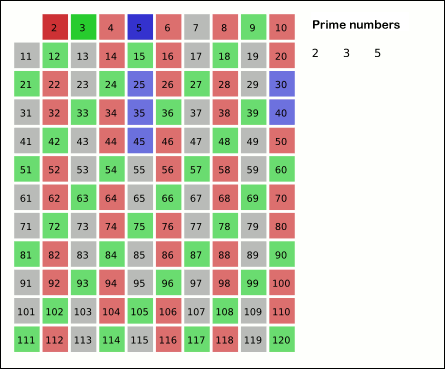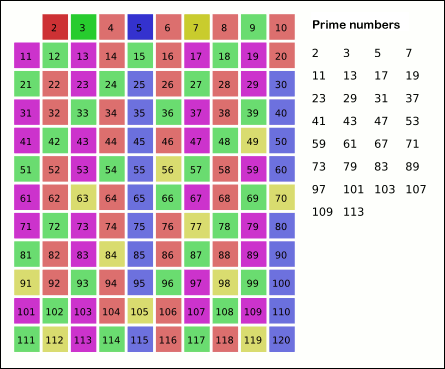
Beginning with the primary prime (2) it marks all its multiples till the requested
restrict. It then takes the following unmarked quantity, assumes it is a prime (as a result of it
isn’t a a number of of a smaller prime), and marks its multiples, and so forth
till all of the multiples beneath the restrict are marked. The remaining
unmarked numbers are primes.
Here is a well-commented, primary Python implementation:
def gen_primes_upto(n):
"""Generates a sequence of primes < n.
Makes use of the complete sieve of Eratosthenes with O(n) reminiscence.
"""
if n == 2:
return
# Initialize desk; True means "prime", initially assuming all numbers
# are prime.
desk = [True] * n
sqrtn = int(math.ceil(math.sqrt(n)))
# Beginning with 2, for every True (prime) quantity I within the desk, mark all
# its multiples as composite (beginning with I*I, since earlier multiples
# ought to have already been marked as multiples of smaller primes).
# On the finish of this course of, the remaining True gadgets within the desk are
# primes, and the False gadgets are composites.
for i in vary(2, sqrtn):
if desk[i]:
for j in vary(i * i, n, i):
desk[j] = False
# Yield all of the primes within the desk.
yield 2
for i in vary(3, n, 2):
if desk[i]:
yield i
After we need a record of all of the primes beneath some identified restrict,
gen_primes_upto is nice, and performs pretty properly. There are two points
with it, although:
- We have now to know what the restrict is forward of time; this is not at all times doable
or handy. - Its reminiscence utilization is excessive – O(n); this may be considerably optimized,
nonetheless; see the bonus part on the finish of the put up for particulars.
The infinite prime generator
Again to the infinite prime generator that is within the focus of this put up. Right here is
its code once more, now with some feedback:
def gen_primes():
"""Generate an infinite sequence of prime numbers."""
# Maps composites to primes witnessing their compositeness.
D = {}
# The working integer that is checked for primeness
q = 2
whereas True:
if q not in D:
# q is a brand new prime.
# Yield it and mark its first a number of that is not
# already marked in earlier iterations
D[q * q] = [q]
yield q
else:
# q is composite. D[q] holds a number of the primes that
# divide it. Since we have reached q, we now not
# want it within the map, however we'll mark the following
# multiples of its witnesses to organize for bigger
# numbers
for p in D[q]:
D.setdefault(p + q, []).append(p)
del D[q]
q += 1
The important thing to the algorithm is the map D. It holds all of the primes encountered
to date, however not as keys! Relatively, they’re saved as values, with the keys being
the following composite quantity they divide. This lets this system keep away from having to
divide every quantity it encounters by all of the primes identified to date – it may well merely
look within the map. A quantity that is not within the map is a brand new prime, and the way in which
the map updates isn’t in contrast to the sieve of Eratosthenes – when a composite is
eliminated, we add the subsequent composite a number of of the identical prime(s). That is
assured to cowl all of the composite numbers, whereas prime numbers ought to by no means
be keys in D.
I extremely advocate instrumenting this operate with some printouts and working
by means of a pattern invocation – it makes it straightforward to grasp how the algorithm
makes progress.
In comparison with the complete sieve gen_primes_upto, this operate does not require
us to know the restrict forward of time – it can hold producing prime numbers advert
infinitum (however will run out of reminiscence finally). As for reminiscence utilization, the
D map has all of the primes in it someplace, however every one seems solely as soon as.
So its measurement is , the place is the
Prime-counting operate,
the variety of primes smaller or equal to n. This may be
approximated by .
I do not bear in mind the place I first noticed this method talked about, however all of the
breadcrumbs result in this ActiveState Recipe by David Eppstein from
means again in 2002.
Optimizing the generator
I actually like gen_primes; it is quick, straightforward to grasp and offers me as
many primes as I want with out forcing me to know what restrict to make use of, and its
reminiscence utilization is far more affordable than the full-blown sieve of Eratosthenes.
It’s, nonetheless, additionally fairly sluggish, over 5x slower than gen_primes_upto.
The aforementioned ActiveState Recipe thread has a number of optimization concepts;
here is a model that comes with concepts from Alex Martelli, Tim Hochberg and
Wolfgang Beneicke:
def gen_primes_opt():
yield 2
D = {}
for q in itertools.depend(3, step=2):
p = D.pop(q, None)
if not p:
D[q * q] = q
yield q
else:
x = q + p + p # get odd multiples
whereas x in D:
x += p + p
D[x] = p
The optimizations are:
- As an alternative of holding an inventory as the worth of D, simply have a single quantity.
In instances the place we’d like a couple of witness to a composite, discover the following
a number of of the witness and assign that as an alternative (that is the whereas x in D
interior loop within the else clause). It is a bit like utilizing linear probing
in a hash desk as an alternative of getting an inventory per bucket. - Skip even numbers by beginning with 2 after which continuing from 3 in steps
of two. - The loop assigning the following a number of of witnesses might land on even numbers
(when p and q are each odd). So as an alternative bounce to q + p + p
straight, which is assured to be odd.
With these in place, the operate is greater than 3x quicker than earlier than, and is
now solely inside 40% or so of gen_primes_upto, whereas remaining quick and
fairly clear.
There are even fancier algorithms that use fascinating mathematical tips to do
much less work. Here is an method by Will Ness and Tim Peters (sure, that Tim Peters) that is
reportedly quicker. It makes use of the wheels concept from this paper by Sorenson. Some extra
particulars on this method can be found right here. This algorithm is each quicker and
consumes much less reminiscence; then again, it is now not quick and easy.
To be trustworthy, it at all times feels a bit odd to me to painfully optimize Python code,
when switching languages supplies vastly larger advantages. For instance, I threw
collectively the identical algorithms utilizing Go
and its experimental iterator help; it is 3x quicker than the
Python model, with little or no effort (although the brand new Go iterators and
yield features are nonetheless within the proposal stage and are not optimized). I
cannot attempt to rewrite it in C++ or Rust for now, as a result of lack of generator
help; the yield assertion is what makes this code so good and stylish,
and different idioms are a lot much less handy.
Bonus: segmented sieve of Eratosthenes
The Wikipedia article on the sieve of Eratosthenes mentions a segmented
method, which
can be described within the Sorenson paper in part 5.
The primary perception is that we solely want the primes as much as to
be capable to sieve a desk all the way in which to N. This leads to a sieve that makes use of
solely reminiscence. Here is a commented Python implementation:
def gen_primes_upto_segmented(n):
"""Generates a sequence of primes < n.
Makes use of the segmented sieve or Eratosthenes algorithm with O(√n) reminiscence.
"""
# Simplify boundary instances by hard-coding some small primes.
if n < 11:
for p in [2, 3, 5, 7]:
if p < n:
yield p
return
# We break the vary [0..n) into segments of size √n
segsize = int(math.ceil(math.sqrt(n)))
# Find the primes in the first segment by calling the basic sieve on that
# segment (its memory usage will be O(√n)). We'll use these primes to
# sieve all subsequent segments.
baseprimes = list(gen_primes_upto(segsize))
for bp in baseprimes:
yield bp
for segstart in range(segsize, n, segsize):
# Create a new table of size √n for each segment; the old table
# is thrown away, so the total memory use here is √n
# seg[i] represents the quantity segstart+i
seg = [True] * segsize
for bp in baseprimes:
# The primary a number of of bp on this section could be calculated utilizing
# modulo.
first_multiple = (
segstart if segstart % bp == 0 else segstart + bp - segstart % bp
)
# Mark all multiples of bp within the section as composite.
for q in vary(first_multiple, segstart + segsize, bp):
seg[q % len(seg)] = False
# Sieving is completed; yield all composites within the section (iterating solely
# over the odd ones).
begin = 1 if segstart % 2 == 0 else 0
for i in vary(begin, len(seg), 2):
if seg[i]:
if segstart + i >= n:
break
yield segstart + i
Code
The total code for this put up – together with checks and benchmarks – is accessible
on GitHub.