

{kind=link}
In at this time’s data-driven world, the flexibility to entry and analyze giant quantities of information can provide researchers, companies & organizations a aggressive edge. One of the vital necessary & free sources of this knowledge is the Web, which could be accessed and mined by way of net scraping.
Net scraping, also referred to as net knowledge extraction or net harvesting, entails utilizing code to make HTTP requests to an internet site’s server, obtain the Content material of a webpage, and parse that Content material to extract the specified knowledge from web sites and retailer it in a structured format for additional evaluation.
Relating to knowledge extraction & processing, Python has grow to be the de-facto language in at this time’s world. On this Playwright Python tutorial on utilizing Playwright for net scraping, we are going to mix Playwright, one of many latest entrants into the world of net testing & browser automation with Python to study methods for Playwright Python scraping.
The explanations for selecting Playwright over some in style alternate options are its developer-friendly APIs, automated ready function, which avoids timeouts in case of slow-loading web sites, very good documentation with examples protecting varied use instances, and a really energetic neighborhood.
So, let’s get began.
Key Use Circumstances of Net Scraping
Now, let’s discover a number of the hottest net scraping use instances.
- Worth & Product Comparability for E-Commerce
Extracting costs, merchandise, and pictures from e-commerce web sites to achieve insights about pricing & comparability with opponents.
- Information for Machine Studying Fashions
Information scientists can use net scraping to get entry to or create knowledge units for varied use instances, corresponding to feeding it to machine studying fashions.
Net scraping can also be helpful for downloading job listings from varied web sites and making them obtainable over a single channel.
- Combination Reductions From Journey Web sites
Aggregator web sites that show the most effective lodge or flight ticket costs additionally use net scraping to get pricing knowledge from varied web sites.
A Phrase of Warning: Accountable Net Scraping
While net scraping is a robust software, there are just a few moral & doubtlessly authorized concerns to think about when doing net scraping.
Many web sites have phrases of use that prohibit or restrict net scraping. It is very important learn and perceive these phrases earlier than starting any net scraping tasks and to acquire permission if needed.
- Delicate or protected knowledge
Net scraping shouldn’t be used to extract delicate or protected knowledge, corresponding to private info or monetary knowledge. This is usually a violation of privateness and may additionally be unlawful.
Net scraping sometimes entails sending a lot of automated requests to an internet site, which may put a pressure on the web site’s servers and sources. It is very important be aware of this and to restrict the variety of requests made to keep away from inflicting hurt to the web site.
By following these tips and utilizing net scraping responsibly, you’ll be able to make sure that your net scraping tasks are authorized and moral and that you’re not inflicting hurt to the web sites you’re scraping.
Having seen so many use instances, it’s evident that the marketplace for net scraping is large. And because the market grows for something, so do the obtainable instruments. On this Playwright for net scraping tutorial, we are going to discover in-depth net scraping with Playwright in Python and the way it can extract knowledge from the net.

What’s Playwright?
Playwright is the newest entrant into the array of frameworks (e.g., Selenium, Cypress, and many others.) obtainable for net automation testing. It allows quick and dependable end-to-end testing for contemporary net apps.
On the time of scripting this Playwright for net scraping tutorial, the newest secure model of Playwright is 1.28.0, and Playwright is now persistently hitting the >20K obtain per day mark, as seen from PyPi Stats.
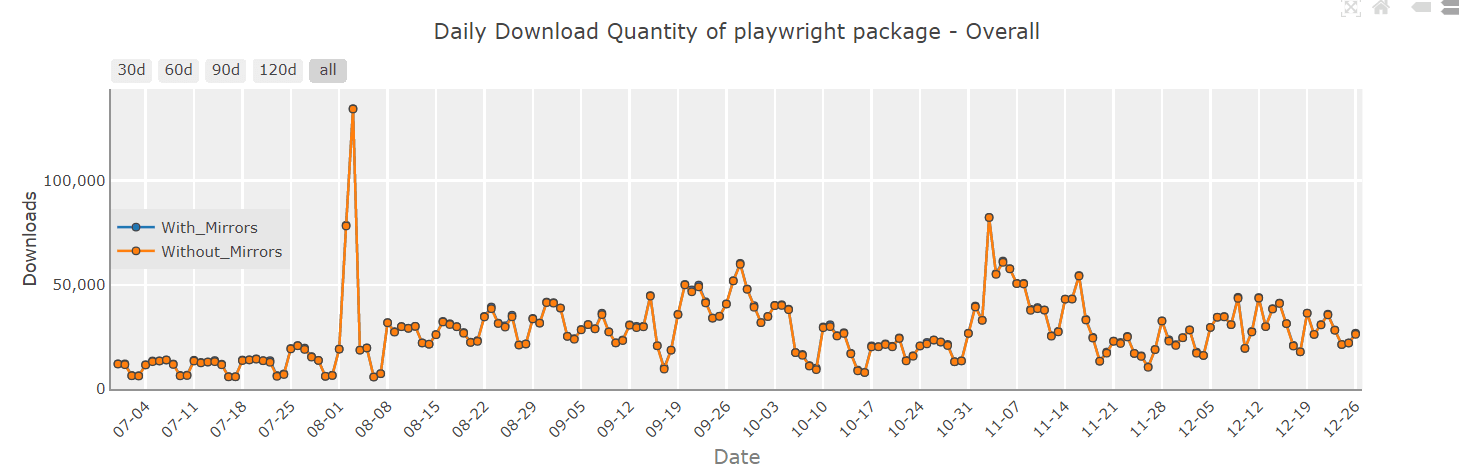
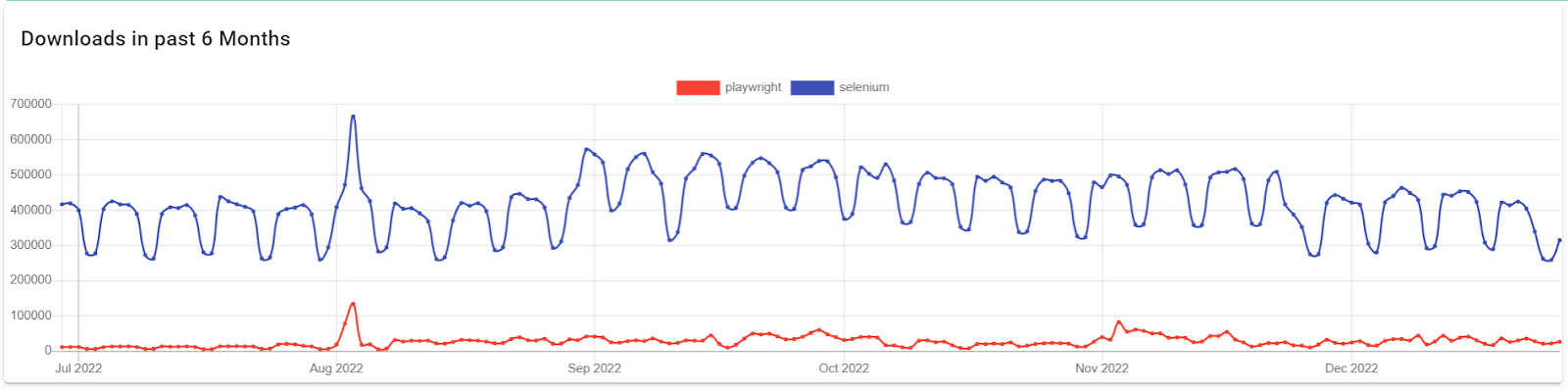
Under are the obtain traits of Playwright compared to a preferred various, Selenium, taken from Pip Tendencies.
A key consideration to make when utilizing any language, software or framework is the convenience of its use. Playwright is an ideal selection for net scraping due to its wealthy & easy-to-use APIs, which permit simpler-than-ever entry to parts on web sites constructed utilizing fashionable net frameworks. You’ll be able to study extra about it by way of this weblog on testing fashionable net functions with Playwright.
Options of Playwright
Some distinctive and key options of Playwright are
Playwright helps all fashionable rendering engines corresponding to Chromium, Firefox, and WebKit, which makes it a sensible choice with regards to working & testing throughout a number of completely different browsers.
Playwright APIs can be found in numerous languages corresponding to Python, Java, JavaScript, TypeScript & .NET, making it simpler for builders from varied language backgrounds to implement net scraping & browser-related duties.
Web sites constructed utilizing fashionable net frameworks have to be examined throughout all working programs to make sure they render accurately on every of them. Playwright works seamlessly on Home windows, macOS, and Linux in each headless & headed modes.
Playwright helps auto-wait, eliminating the necessity for synthetic timeout, making the assessments extra resilient & much less flaky
Playwright assertions are explicitly created for the dynamic net. Checks are routinely retried till the mandatory circumstances are met, making it a super candidate for testing web sites constructed utilizing fashionable net frameworks.
Playwright’s locators present distinctive & easy methods to search out parts on web sites constructed utilizing fashionable net frameworks. Later on this Playwright for net scraping tutorial, we are going to deep dive into Playwright’s locators and why they make life a lot simpler.
Playwright gives a singular codegen software that may primarily write the code for you. You can begin the codegen utilizing the playwright codegen websitename and carry out the browser actions. The codegen will document and supply boilerplate code that can be utilized or adjusted per our necessities.
Now that we all know what Playwright is, let’s go forward and discover how we are able to leverage its Python API for net scraping, beginning firstly with set up & setup.
Why Playwright for Net Scraping with Python?
As talked about above, it’s attainable to make use of Playwright for net scraping with completely different languages corresponding to JavaScript, TypeScript, Java, .Web, and Python. So, it’s needed to know why Python.
I’ve been programming for ten years utilizing languages corresponding to C++, Java, JavaScript & Python, however in my expertise, Python is probably the most developer-friendly and productivity-oriented language.
It abstracts pointless problems of sure different programming languages and lets builders deal with writing high quality code and shorten the supply time while additionally having fun with writing the code.
A fast case for why I like Python automation testing & why we select Playwright for net scraping, particularly utilizing its Python API.
The Zen Of Python, which defines the tenet of Python’s design, mentions ‘Easy Is Higher Than Advanced’. So, Python is a language developed explicitly with productiveness, ease of use, and quicker supply in thoughts. It’s one of many best, most enjoyable, and quickest programming languages to study and use.
- De-facto selection for processing knowledge
Python has grow to be the de-facto language for working with knowledge within the fashionable world. Numerous packages corresponding to Pandas, Numpy, and PySpark can be found and have in depth documentation and an ideal neighborhood to assist write code for varied use instances round knowledge processing. Since net scraping ends in a variety of knowledge being downloaded & processed, Python is an excellent selection. You’ll be able to study extra about it by way of this weblog on net scraping with Python.
Python is now broadly utilized in nearly all areas of the software program growth lifecycle, together with growth, testing, DevOps, and help. Its adoption, particularly because the launch of the three.X variations, has been phenomenal.
- Nice neighborhood & ecosystem
The Python ecosystem is mature and has an unlimited neighborhood and a variety of packages obtainable within the Python ecosystem for processing knowledge.
With an understanding of why we selected to work with Playwright for net scraping in Python, let’s now have a look at Playwright’s Locators. Playwright helps a wide range of locator methods, together with CSS Selectors, XPath expressions, and textual content Content material matching.
Locators are a crucial part of Playwright, making net browser-related duties attainable, straightforward, dependable, and enjoyable.
Understanding Playwright Locators
Locators are the centerpiece of the Playwright’s capacity to automate actions & find parts on the browser.
Merely put, locators are a manner of figuring out a selected component on a webpage in order that we are able to work together with it in our scripts.
Key Options of Playwright Locators
Locators can help you specify precisely which component you need to work together with on an internet web page. This may be helpful when there are a number of parts on the web page with related attributes or traits. You should use a locator to pick a selected component relatively than simply the primary one which matches the factors.
Playwright gives a number of various kinds of locators, together with CSS Selectors, XPath, and textual content Content material, so you’ll be able to select the one which most closely fits your wants. This lets you tailor your locators to the particular construction and Content material of the net web page you’re working with.
Each time a locator is used for an motion, an up-to-date DOM component is positioned on the web page. If the DOM modifications between the calls attributable to re-render, the brand new component similar to the locator can be used.
Within the beneath instance snippet, the button component can be positioned twice: as soon as for the hover() motion and as soon as for the clicking() motion to make sure we at all times have the newest knowledge. This function is offered out of the field while not having further code.

Observe: In Playwright, waits are pointless as a result of it routinely waits for parts to be obtainable earlier than interacting with them. This implies you wouldn’t have to manually add delays or sleep in your check code to attend for parts to load.
Moreover, Playwright consists of many built-in retry mechanisms that make it extra resilient to flaky assessments. For instance, if a component shouldn’t be discovered on the web page, Playwright will routinely retry for a specific amount earlier than giving up and throwing an error. This might help to cut back the necessity for express waits in your assessments.
You’ll be able to study extra about it by way of this weblog on sorts of waits.
- Help for a number of browsers
Playwright helps all fashionable rendering engines, together with WebKit, Chromium, and Firefox, so you should utilize the identical locators and code throughout completely different browsers. - Check Cell Net
Native cellular emulation of Google Chrome for Android and Cell Safari. The identical rendering engine works domestically or in the event you want to select so, within the Cloud.
The beneath desk summarizes some built-in locators obtainable as a part of the Playwright
| Locator Identify | Use Case |
|---|---|
| web page.get_by_role() | find by express and implicit accessibility attributes |
| web page.get_by_text() | find by textual content Content material |
| web page.get_by_label() | find a type management by related label’s textual content |
| web page.get_by_placeholder() | find an enter by placeholder |
| web page.get_by_alt_text() | find a component, often picture, by its textual content various |
| web page.get_by_title() | find a component by its title attribute |
| web page.get_by_test_id() | to find a component primarily based on its data-testid attribute (different attributes could be configured) |
Playwright Setup & Set up
When programming in Python it’s a de-facto strategy to have a separate digital setting for every mission. This helps us handle dependencies higher with out disturbing our base Python set up.
Digital Atmosphere & Playwright Set up
- Create a devoted folder for the mission known as playwrightwebscraping. (This step shouldn’t be necessary however is nice apply).
- Subsequent, utilizing Python’s built-in venv module, let’s create a digital setting named playwrightplayground and activate it by calling the activate script.
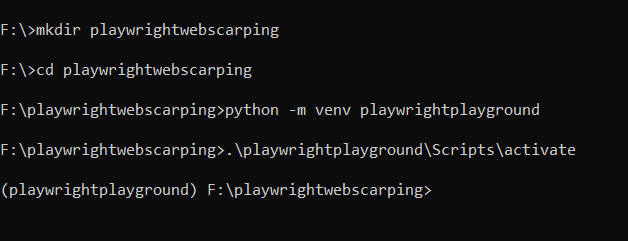
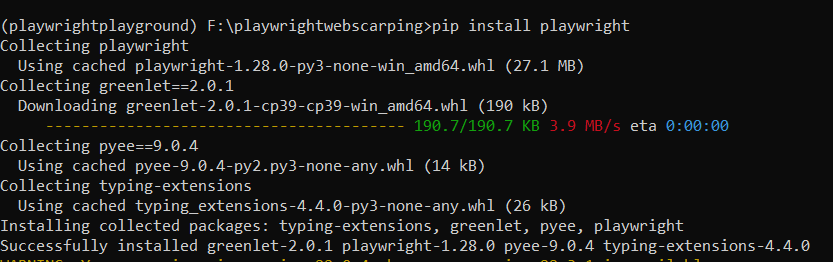
- Lastly, set up the Playwright module from the Python bundle index PyPi utilizing the command pip set up playwright.
Downloading Browsers for Playwright
After finishing the set up of the Playwright Python bundle, we have to obtain & set up browser binaries for Playwright to work with.
By default, Playwright will obtain binaries for Chromium, WebKit & Firefox from Microsoft CDN, however this conduct is configurable. The obtainable configurations are as beneath.
- Skip Downloads of Browser Binaries
Skip the obtain of binaries altogether in case testing must be carried out on a cloud-based grid relatively than domestically. In such instances, we might not want the browsers downloaded on native programs. This may be carried out by setting the setting variable PLAYWRIGHT_SKIP_BROWSER_DOWNLOAD.
PLAYWRIGHT_SKIP_BROWSER_DOWNLOAD=1 python -m playwright set up
- Downloads of Browser Binaries from Totally different Repositories
As a great apply and for safety causes, organizations might not permit connections to Microsoft CDN repositories, which Playwright downloads the browsers from. In such instances, the setting variable PLAYWRIGHT_DOWNLOAD_HOST could be set to provide a hyperlink to a distinct repository.
PLAYWRIGHT_DOWNLOAD_HOST=
playwright set up
- Downloads of Browser Binaries Through Proxy
Most organizations route requests to the web through a Proxy for higher safety. In such instances, Playwright browser obtain could be carried out by setting the HTTPS_PROXY setting variable earlier than set up.
HTTPS_PROXY=
playwright set up
- Downloads of Single Browser Binary
Obtain solely a single browser binary relying in your wants can also be attainable, during which case the set up instructions wanted must be provided with the browser identify, for instance, playwright set up firefox
To maintain issues easy we set up all browsers by utilizing the command playwright set up. This step could be skipped solely in the event you run your code on cloud Playwright Grid, however we are going to have a look at each eventualities, i.e., utilizing Playwright for net scraping domestically and on a cloud Playwright Grid offered by LambdaTest.
Setup Playwright Mission in Visible Studio Code
You probably have Visible Studio Code(VS Code) already put in the simplest option to begin it up is to navigate to the newly created mission folder and sort code.

That is how the VS Code will look when it opens. We now want to pick the interpreter, i.e., the Python set up, from our newly created digital setting.
Press Ctrl + Shift + P to open up the command palette in VS Code and sort Python: Choose Interpreter and click on it.
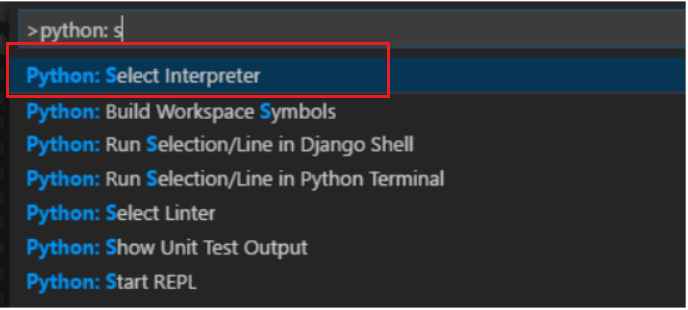
VS Code will routinely detect the digital setting we created earlier and advocate it on the high, choose it. If VS Code doesn’t auto-detect, click on on the ‘Enter interpreter path..’ and navigate to playwrightplayground > Scripts > Python and choose it.

You’ll be able to confirm the digital setting by urgent the ctrl + (tilt), which is able to open up the VS Code terminal & activate the digital setting. An energetic setting is indicated by its identify earlier than the trail inside spherical brackets.
With the setup and set up out of the best way, we are actually prepared to make use of Playwright for net scraping with Python.
Demonstration: Utilizing Playwright for Net Scraping with Python
For demonstration, I can be scraping info from two completely different web sites. I can be utilizing the XPath locator within the second state of affairs. This can assist you in selecting the best-suited locator for automating the assessments.
So, let’s get began…
Check State of affairs 1: Net Scraping E-Commerce Web site
Within the first demo, we’re going to scrape a demo E-Commerce web site offered by LambdaTest for the next knowledge;
- Product Identify
- Product Worth
- Product Picture URL
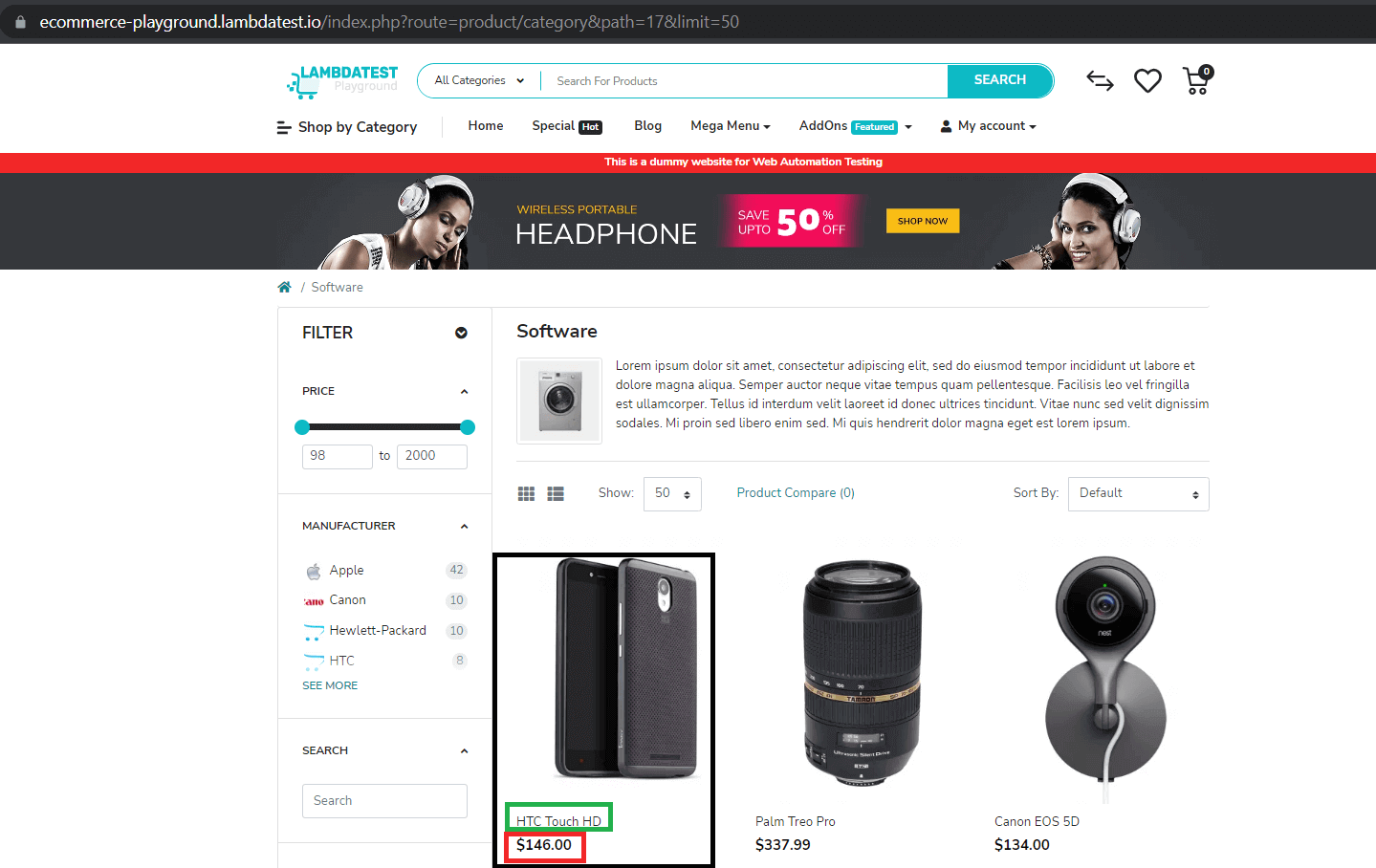
Right here is the Playwright for net scraping state of affairs that can be executed on Chrome on Home windows 10 utilizing Playwright Model 1.28.0. We’ll run the Playwright check on cloud testing platforms like LambdaTest.
By using LambdaTest, you’ll be able to considerably cut back the time required to run your Playwright Python assessments by leveraging an on-line browser farm that features greater than 50 completely different browser variations, together with Chrome, Chromium, Microsoft Edge, Mozilla Firefox, and Webkit.
You can even subscribe to the LambdaTest YouTube Channel and keep up to date with the newest tutorial round Playwright browser testing, Cypress E2E testing, Cell App Testing, and extra.
Nevertheless, the core logic stays unchanged even when the net scraping needs to be carried out utilizing an area machine/grid.
Check State of affairs:
- Go to https://ecommerce-playground.lambdatest.io/.
- Click on on ‘Store by Class’ & choose ‘Software program’.
- Modify the ‘Present’ filter to show 75 outcomes.
- Scrape the product identify, value & picture URL.
Model Verify:
When scripting this weblog on utilizing Playwright for net scraping, the model of Playwright is 1.28.0, and the model of Python is 3.9.12. The code is absolutely examined and dealing on these variations.
Implementation:
You’ll be able to clone the repo by clicking on the button beneath.

import json
import logging
import os
import subprocess
import sys
import time
import urllib
from logging import getLogger
from dotenv import load_dotenv
from playwright.sync_api import sync_playwright
# setup fundamental logging for our mission which is able to show the time, log stage & log message
logger = getLogger("webscapper.py")
logging.basicConfig(
stream=sys.stdout, # uncomment this line to redirect output to console
format="%(message)s",
stage=logging.DEBUG,
)
# LambdaTest username & entry key are saved in an env file & we fetch it from there utilizing python dotenv module
load_dotenv("pattern.env")
capabilities = {
"browserName": "Chrome", # Browsers allowed: `Chrome`, `MicrosoftEdge`, `pw-chromium`, `pw-firefox` and `pw-webkit`
"browserVersion": "newest",
"LT:Choices": {
"platform": "Home windows 10",
"construct": "E Commerce Scrape Construct",
"identify": "Scrape Lambda Software program Product",
"person": os.getenv("LT_USERNAME"),
"accessKey": os.getenv("LT_ACCESS_KEY"),
"community": False,
"video": True,
"console": True,
"tunnel": False, # Add tunnel configuration if testing domestically hosted webpage
"tunnelName": "", # Non-obligatory
"geoLocation": "", # nation code could be fetched from https://www.lambdatest.com/capabilities-generator/
},
}
def major():
with sync_playwright() as playwright:
playwright_version = (
str(subprocess.getoutput("playwright --version")).strip().break up(" ")[1]
)
capabilities["LT:Options"]["playwrightClientVersion"] = playwright_version
lt_cdp_url = (
"wss://cdp.lambdatest.com/playwright?capabilities="
+ urllib.parse.quote(json.dumps(capabilities))
)
logger.information(f"Initiating connection to cloud playwright grid")
browser = playwright.chromium.join(lt_cdp_url)
# remark above line & uncomment beneath line to check on native grid
# browser = playwright.chromium.launch(headless=False)
web page = browser.new_page()
attempt:
# part to navigate to software program class
web page.goto("https://ecommerce-playground.lambdatest.io/")
web page.get_by_role("button", identify="Store by Class").click on()
web page.get_by_role("hyperlink", identify="Software program").click on()
page_to_be_scrapped = web page.get_by_role(
"combobox", identify="Present:"
).select_option(
"https://ecommerce-playground.lambdatest.io/index.php?route=product/class&path=17&restrict=75"
)
web page.goto(page_to_be_scrapped[0])
# Since picture are lazy-loaded scroll to backside of web page
# the vary is dynamically determined primarily based on the variety of gadgets i.e. we take the vary from restrict
# https://ecommerce-playground.lambdatest.io/index.php?route=product/class&path=17&restrict=75
for i in vary(int(page_to_be_scrapped[0].break up("=")[-1])):
web page.mouse.wheel(0, 300)
i += 1
time.sleep(0.1)
# Assemble locators to establish identify, value & picture
base_product_row_locator = web page.locator("#entry_212408").locator(".row").locator(".product-grid")
product_name = base_product_row_locator.get_by_role("heading")
product_price = base_product_row_locator.locator(".price-new")
product_image = (
base_product_row_locator.locator(".carousel-inner")
.locator(".energetic")
.get_by_role("img")
)
total_products = base_product_row_locator.depend()
for product in vary(total_products):
logger.information(
f"n**** PRODUCT {product+1} ****n"
f"Product Identify = {product_name.nth(product).all_inner_texts()[0]}n"
f"Worth = {product_price.nth(product).all_inner_texts()[0]}n"
f"Picture = {product_image.nth(product).get_attribute('src')}n"
)
standing="standing"
comment = 'Scraping Accomplished'
web page.consider("_ => {}","lambdatest_action: {"motion": "setTestStatus", "arguments": {"standing":"" + standing + "", "comment": "" + comment + ""}}")
besides Exception as ex:
logger.error(str(ex))
if __name__ == "__main__":
major()
Code Walkthrough:
Let’s now do a step-by-step walkthrough to know the code.
Step 1 – Organising imports
Probably the most noteworthy imports are
from dotenv import load_dotenv
The explanation for utilizing the load_dotenv library is that it reads key-value pairs from a .env file(in our case pattern.env) and might set them as setting variables routinely. In our case, we use it to learn the entry key & username from a pattern.env required to entry the cloud-based Playwright Grid.
It saves the difficulty of setting setting variables manually & therefore the identical code can seamlessly be examined on completely different environments with none guide intervention.
from playwright.sync_api import sync_playwright
Playwright gives each sync & async API to work together with net apps, however for this weblog on utilizing Playwright for net scraping, we’re going to use the sync_api, which is just a wrapper across the asyncio_api that abstracts away the necessity to implement async performance.
For extra difficult eventualities the place there’s a want for fine-grained management when coping with particular eventualities on web sites constructed utilizing fashionable net frameworks, we are able to select to make use of the async_api.
For many use instances, the sync_api ought to suffice, but it surely’s a bonus that the async_api does exist and could be leveraged when wanted.

Step 2 – Organising logging & studying username & entry key
Within the subsequent step, we arrange logging to see the execution of our code & additionally print out the product identify, value & hyperlink to picture. Logging is the really helpful apply and must be most well-liked to print() statements nearly at all times.
The load_dotenv(“pattern.env”) reads the username & entry key required to entry our cloud-based Playwright grid. The username and entry key can be found on the LambdaTest Profile Web page.


Step 3 – Organising desired browser capabilities
We arrange the browser capabilities required by the cloud-based Playwright automated testing grid in a Python dictionary. Allow us to perceive what every line of this configuration means.
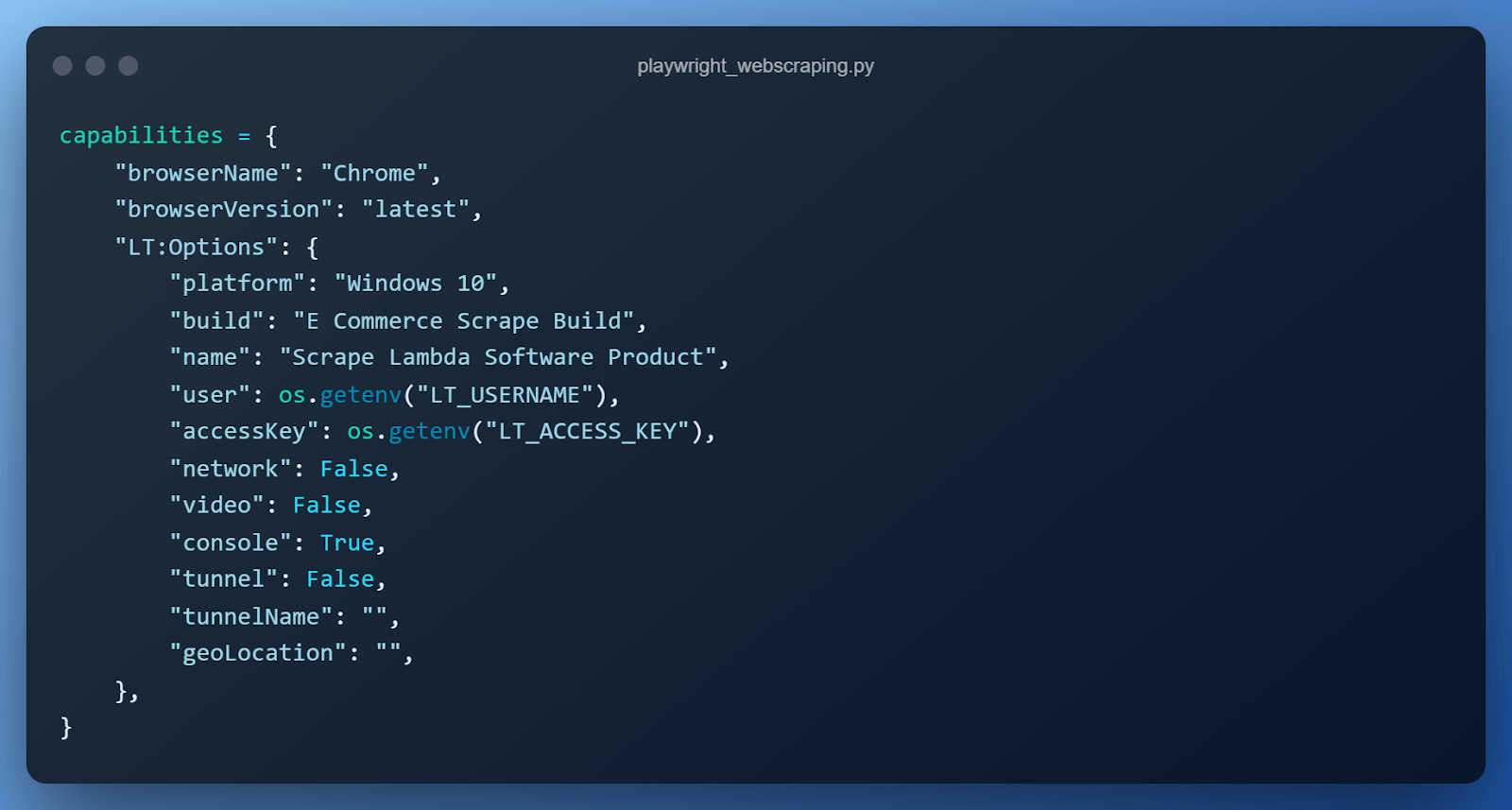
- browserName is used to specify the browser the check/code ought to run on. All fashionable browsers, corresponding to Chrome, Firefox, Microsoft Edge & WebKit.
- browserVersion is used to specify the model of the browser.
- platform is used to specify the working system the check ought to run on corresponding to Home windows, macOS, or Linux.
- construct is used to specify the identify underneath which the assessments can be grouped.
- identify is used to specify the identify of the check.
- person & entry key are our credentials to hook up with the cloud Playwright grid.
- community is used to specify whether or not the cloud Playwright grid ought to seize community logs.
- video is used to specify if the cloud Playwright grid ought to seize video of all the check execution.
- tunnel & tunnelName are used to specify tunnel particulars in case the web site we use isn’t publicly hosted over the web.
Step 4 – Initializing browser context & connecting to cloud Playwright Grid

- Create a ContextManager for the sync_playwright() operate offered by Playwright.
- Use Python’s built-in subprocess module to run the playwright –model command to extract the Playwright model.
- Add playwright_version to the config dictionary of our cloud Playwright grid.
- Put together the WebSocket URL for our cloud Playwright grid in order that we are able to leverage their infrastructure to run the script.
- Use the usual join methodology, which makes use of the Playwright’s built-in browser server to deal with the connection. It is a quicker and extra fully-featured methodology because it helps most Playwright parameters (corresponding to utilizing a proxy if working behind a firewall).
- Create a web page within the browser context.
Step 5 – Open the web site to scrape.
Open the web site to scrape utilizing the web page context.

Step 6 – Click on on ‘Store by Class’.
‘Store By Class’ is a hyperlink with the ‘button’ position assigned to it. Therefore, we use Playwright‘s get_by_role() locator to navigate to it & carry out the click on() motion.

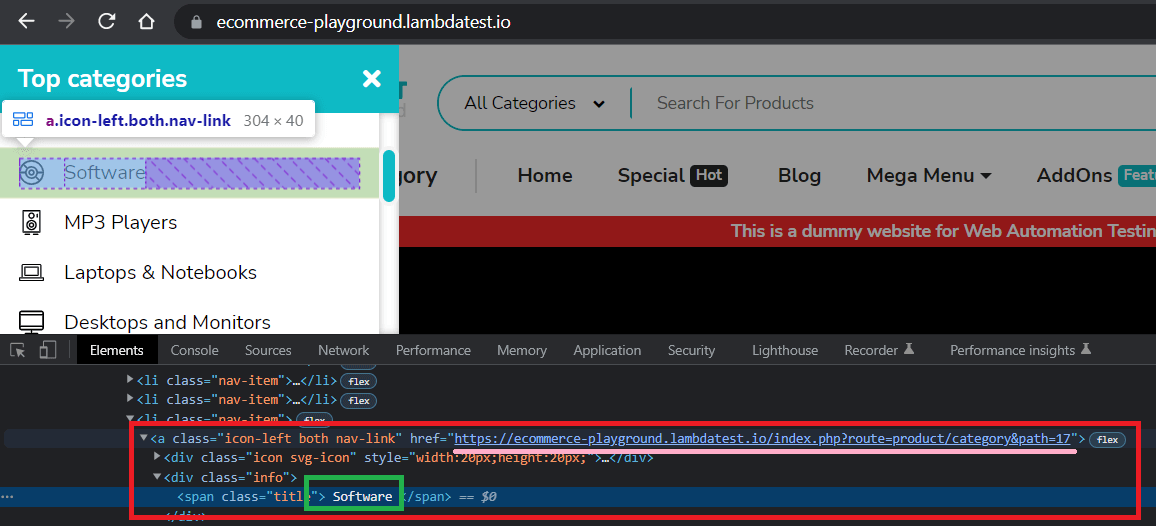
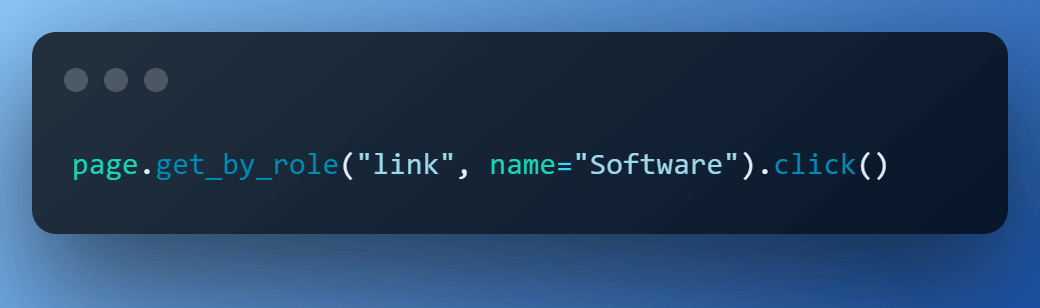
Step 7 – Click on on the ‘Software program’.
Inspection of the ‘Software program’ component exhibits that it’s a ‘hyperlink’ with identify in a span. So, we use the built-in locator get_by_role() once more and carry out click on() motion.
Step 8 – Modify the product drop all the way down to get extra merchandise.
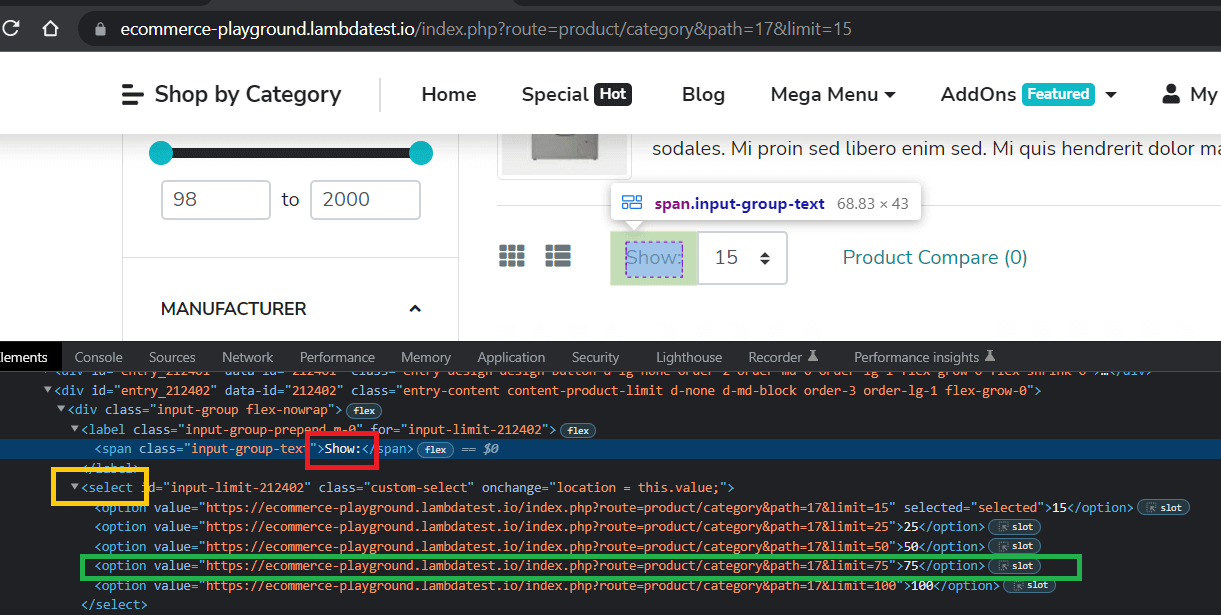
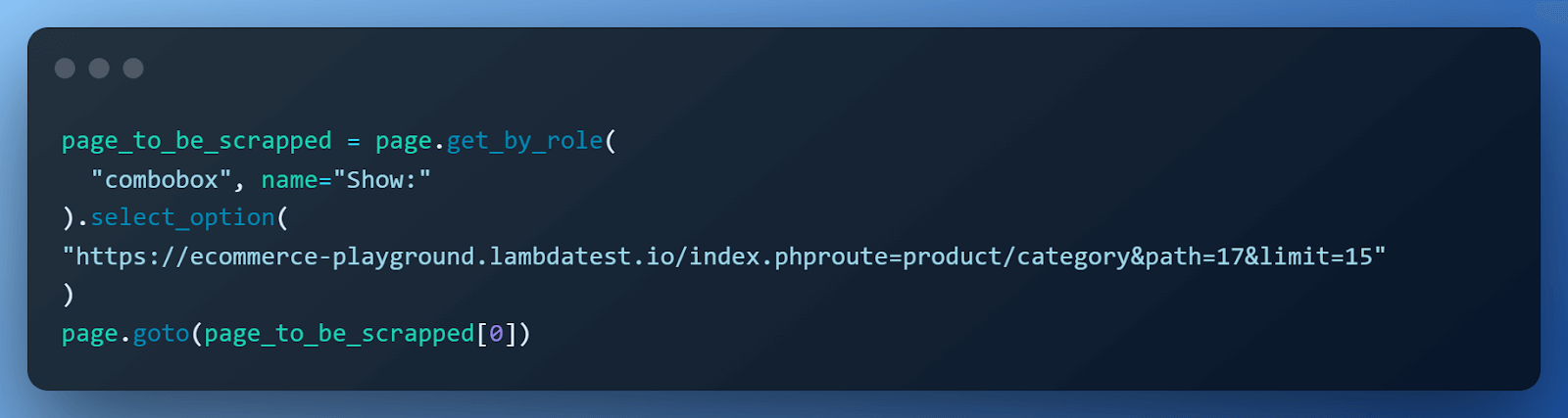
By default, the ‘Software program’ web page shows 15 gadgets, we are able to simply change it to 75, which is nothing however a hyperlink to the identical web page with a distinct restrict. Get that hyperlink and name the web page.goto() methodology.
Step 9 – Loading Photographs.
The photographs on the web site are lazy-loaded, i.e., solely loaded as we convey them into focus or just scroll all the way down to them. To study extra about it, you’ll be able to undergo this weblog on a full information to lazy load photographs.
We use Playwright’s mouse wheel operate to simulate a mouse scroll.
Step 10 – Making ready base locator.
Discover that every one the merchandise are contained inside two divs with id=entry_212408 and class=row. Every product then has a class=product-grid. We use this information to type our base locator.
The bottom locator will then be used to search out parts, corresponding to identify, value & picture.
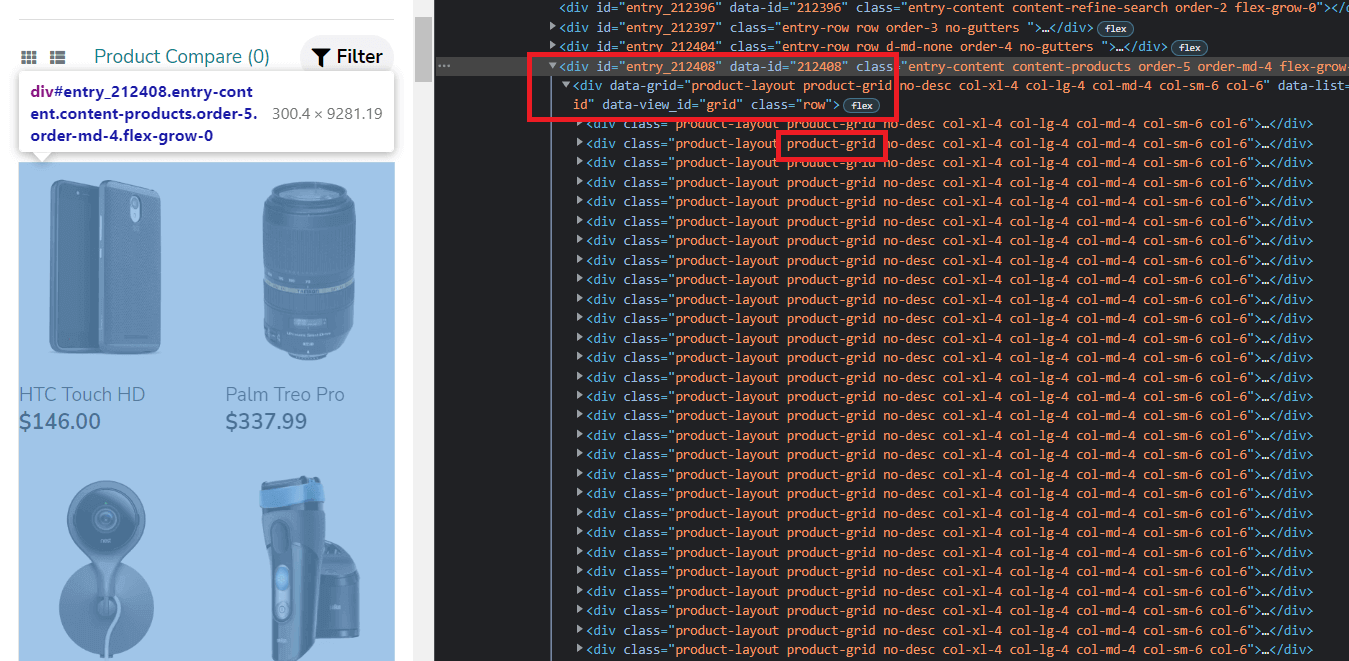

Step 11 – Finding product identify, value & picture.
With respect to the bottom locator, the placement of different parts turns into straightforward to seize.
- Product Identify is contained inside an h4 tag.
- Product Worth is contained in a div with class=price-new.
- Picture is current in class=carousel-inner energetic.


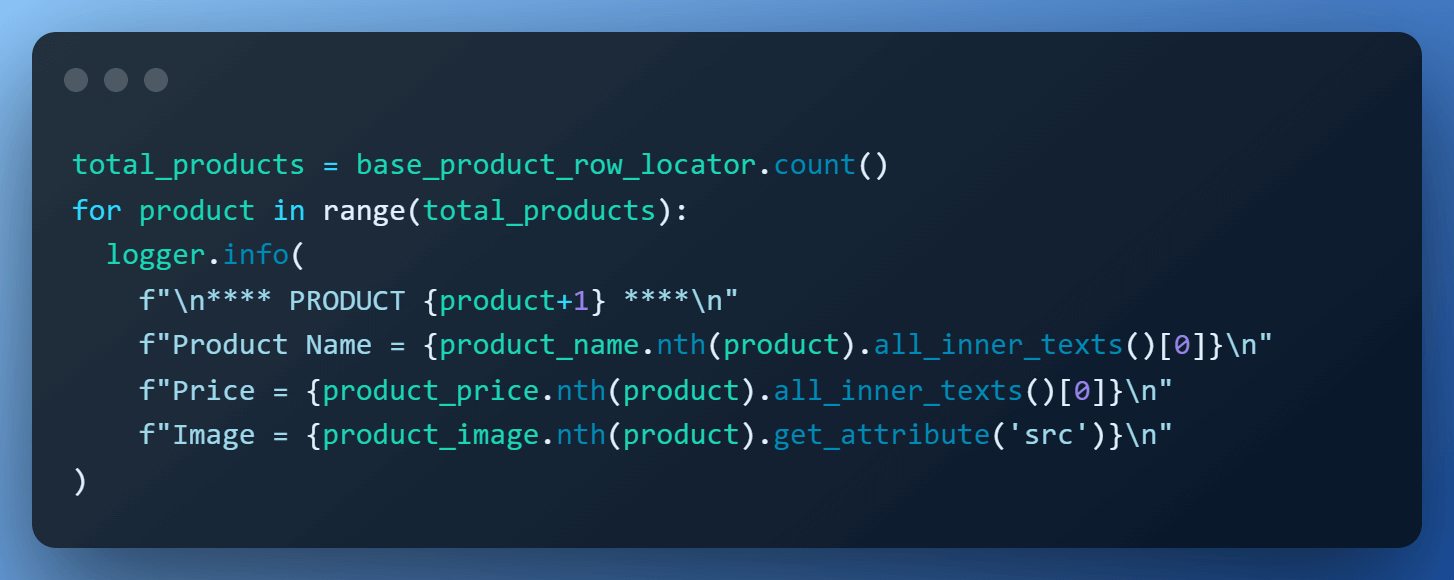
Step 12 – Scraping the info.
Now that we’ve all the weather positioned, we merely iterate over the whole merchandise & scrape them one after the other utilizing the nth() methodology.
The overall variety of merchandise is obtained by calling the depend() methodology on base_product_row_locator. For product identify & value, we fetch textual content utilizing the all_inner_texts(), and picture URL is retrieved utilizing the get_attribute(‘src’) component deal with.
Execution:
Et voilà! Right here is the truncated execution snapshot from the VS Code, which exhibits knowledge of the primary 5 merchandise.

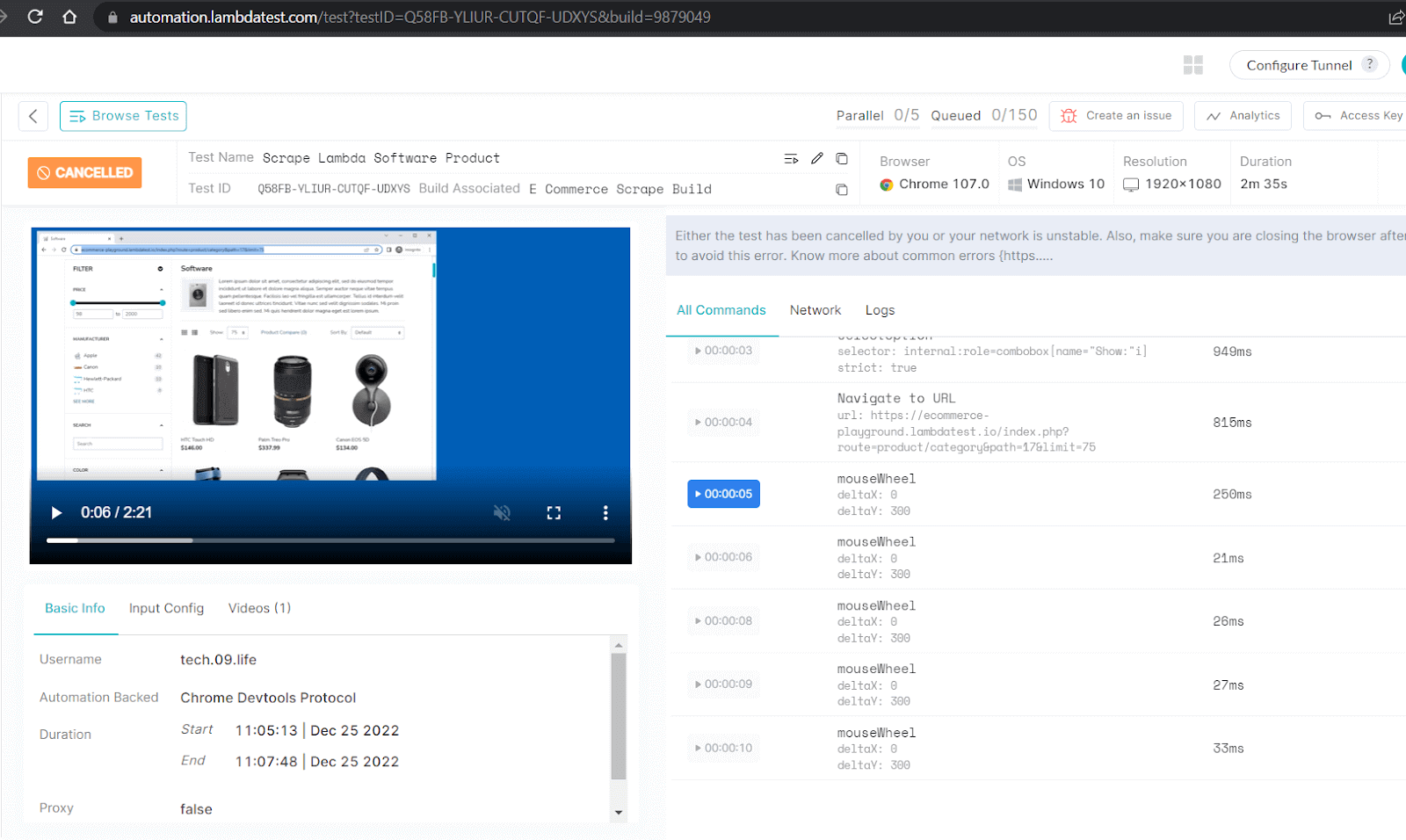
Here’s a snapshot from the LambdaTest dashboard, which exhibits all of the detailed execution, video seize & logs of all the course of.
Check State of affairs 2: Net Scraping Selenium Playground
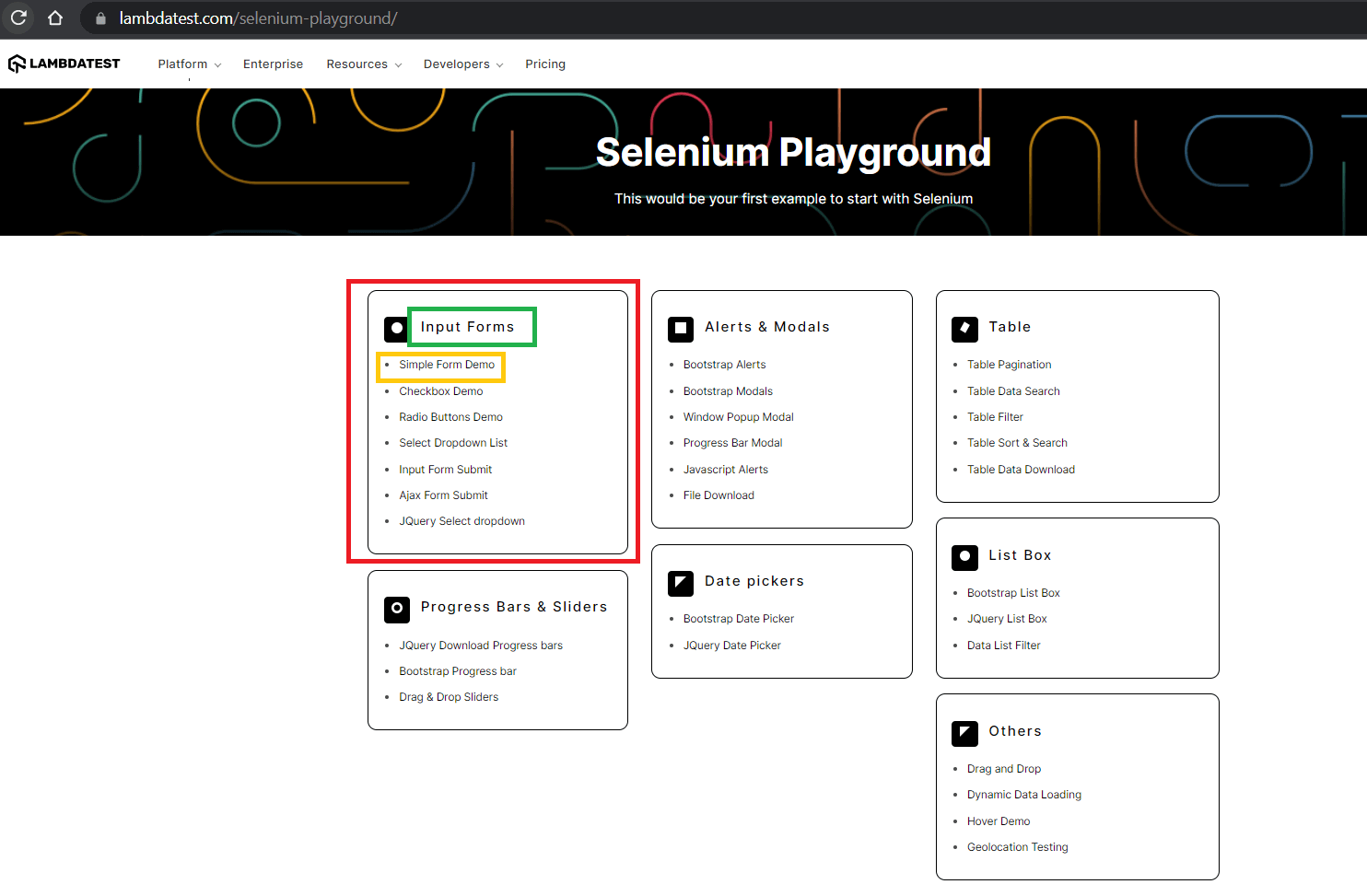
Let’s take one other instance the place I can be scraping info from the LambdaTest Selenium Playground.
On this demonstration, we scrape the next knowledge from the LambdaTest Selenium Playground:
- Heading of part
- Identify of particular person demo
- Hyperlink to particular person demo
One necessary change we’re going to make on this demo to point out the flexibility of Playwright for net scraping utilizing Python is
- Use of ‘XPath’ together with locators to search out parts.
Right here is the state of affairs for utilizing Playwright for net scraping, which can be executed on Chrome on Home windows 10 utilizing Playwright Model 1.28.0.
Check State of affairs:
- Go to ‘https://www.lambdatest.com/selenium-playground/’
- Scrape the product heading, demo identify & hyperlink of demo.
- Print the scraped knowledge.
Model Verify:
On the time of scripting this weblog on utilizing Playwright for net scraping, the model of Playwright is 1.28.0, and the model of Python is 3.9.12.
The code is absolutely examined and dealing on these variations.
Implementation:
Clone the Playwright Python WebScraping Demo GitHub repository to observe the steps talked about additional within the weblog on utilizing Playwright for net scraping.

import json
import logging
import os
import subprocess
import sys
import time
import urllib
from logging import getLogger
from dotenv import load_dotenv
from playwright.sync_api import sync_playwright
logger = getLogger("seleniumplaygroundscrapper.py")
logging.basicConfig(
stream=sys.stdout,
format="%(message)s",
stage=logging.DEBUG,
)
# Learn LambdaTest username & entry key from env file
load_dotenv("pattern.env")
capabilities = {
"browserName": "Chrome",
"browserVersion": "newest",
"LT:Choices": {
"platform": "Home windows 10",
"construct": "Selenium Playground Scraping",
"identify": "Scrape LambdaTest Selenium Playground",
"person": os.getenv("LT_USERNAME"),
"accessKey": os.getenv("LT_ACCESS_KEY"),
"community": False,
"video": True,
"console": True,
"tunnel": False,
"tunnelName": "",
"geoLocation": "",
},
}
def major():
with sync_playwright() as playwright:
playwright_version = (
str(subprocess.getoutput("playwright --version")).strip().break up(" ")[1]
)
capabilities["LT:Options"]["playwrightClientVersion"] = playwright_version
lt_cdp_url = (
"wss://cdp.lambdatest.com/playwright?capabilities="
+ urllib.parse.quote(json.dumps(capabilities))
)
logger.information(f"Initiating connection to cloud playwright grid")
browser = playwright.chromium.join(lt_cdp_url)
# remark above line & uncomment beneath line to check on native grid
# browser = playwright.chromium.launch()
web page = browser.new_page()
attempt:
web page.goto("https://www.lambdatest.com/selenium-playground/")
# Assemble base locator part
base_container_locator = web page.locator("//*[@id='__next']/div/part[2]/div/div/div")
for merchandise in vary(1, base_container_locator.depend()+1):
# Discover part, demo identify & demo hyperlink with respect to base locator & print them
locator_row = base_container_locator.locator(f"//div[{item}]")
for inner_item in vary(0, locator_row.depend()):
logger.information(f"*-*-"*28)
logger.information(f'Part: {locator_row.nth(inner_item).locator("//h2").all_inner_texts()[0]}n')
for list_item in vary(0,locator_row.nth(inner_item).locator("//ul/li").depend()):
logger.information(f'Demo Identify: {locator_row.nth(inner_item).locator("//ul/li").nth(list_item).all_inner_texts()[0]}')
logger.information(f'Demo Hyperlink: {locator_row.nth(inner_item).locator("//ul/li/a").nth(list_item).get_attribute("href")}n')
standing="standing"
comment = 'Scraping Accomplished'
web page.consider("_ => {}","lambdatest_action: {"motion": "setTestStatus", "arguments": {"standing":"" + standing + "", "comment": "" + comment + ""}}")
besides Exception as ex:
logger.error(str(ex))
if __name__ == "__main__":
major()
Scrape Selenium Playground Gist
Code Walkthrough:
Let’s now do a step-by-step walkthrough to know the code.
Step 1 – Step 4
Embody the imports, logging, cloud Playwright testing grid & browser context setup that stay the identical because the earlier demonstration; therefore, confer with them above.
Step 5 – Open the LambdaTest Selenium Playground Web site
Use the web page created within the browser context to open the LambdaTest Selenium Playground web site, which we are going to scrape.

Step 6 – Assemble the bottom locator
Inspecting the web site in Chrome Developer Instruments, we see that there’s a grasp container that holds all of the sub-blocks. We’ll use this to assemble our base locator by copying the XPath.
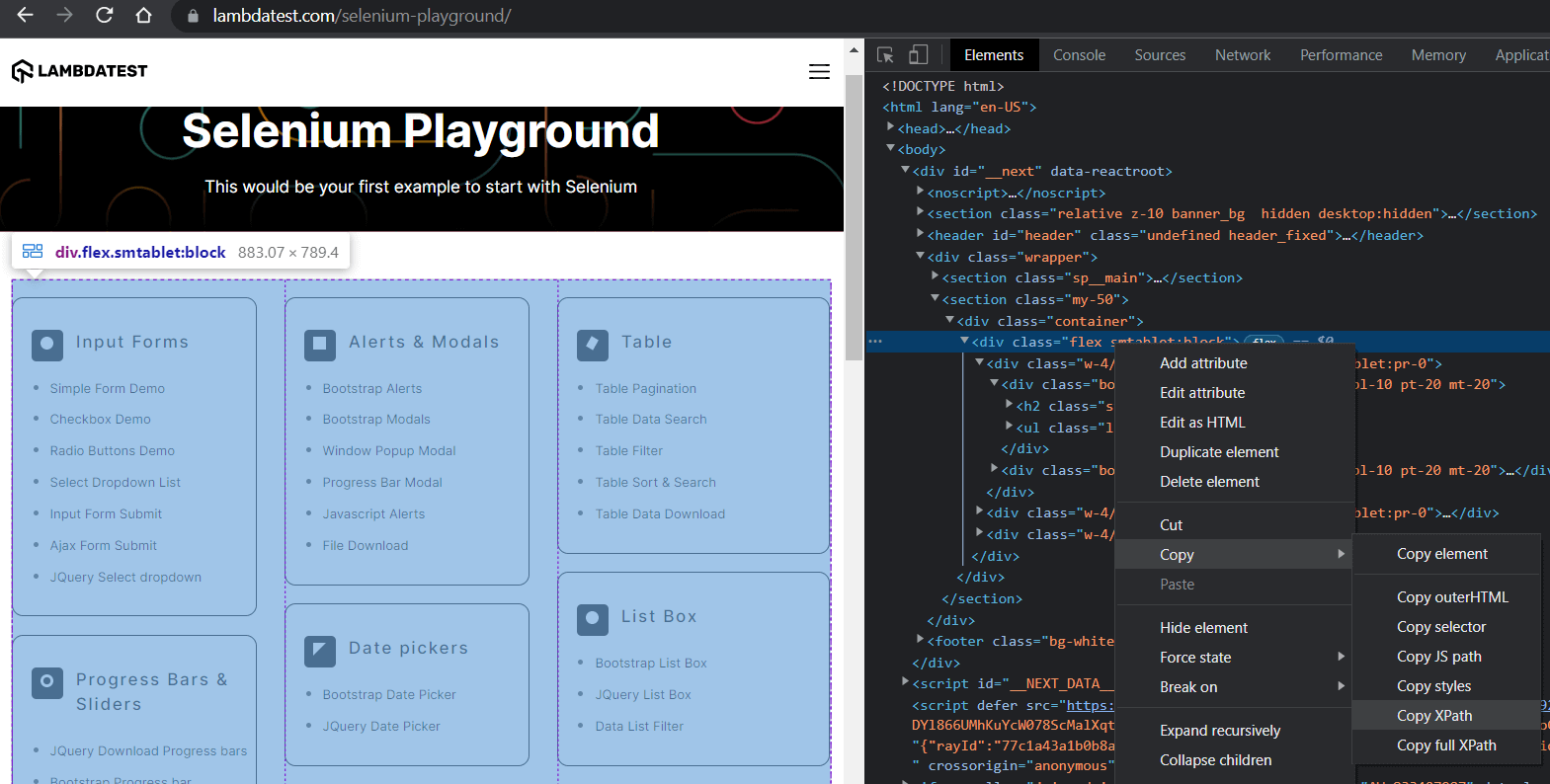

Step 7 – Find the part, demo identify, and demo hyperlink
We repeat the inspection utilizing Chrome Developer Instruments, and it’s straightforward to identify that knowledge is offered in 3 divs. Inside every div, there are then separate sections for every merchandise.
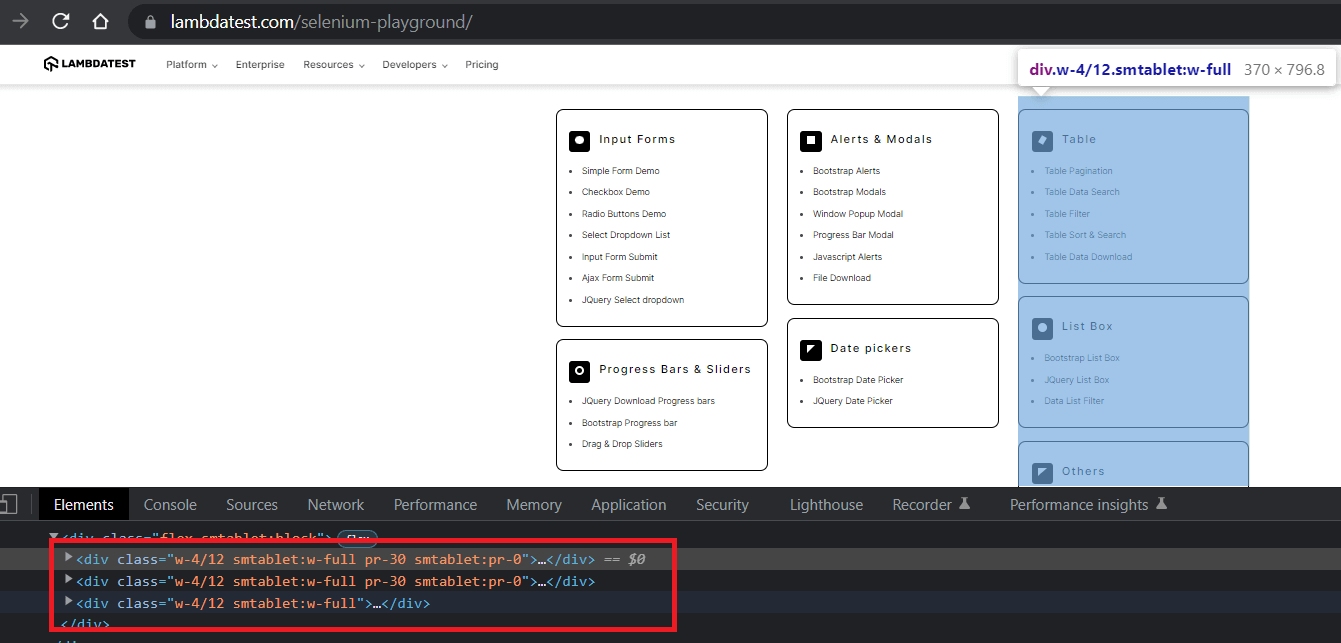
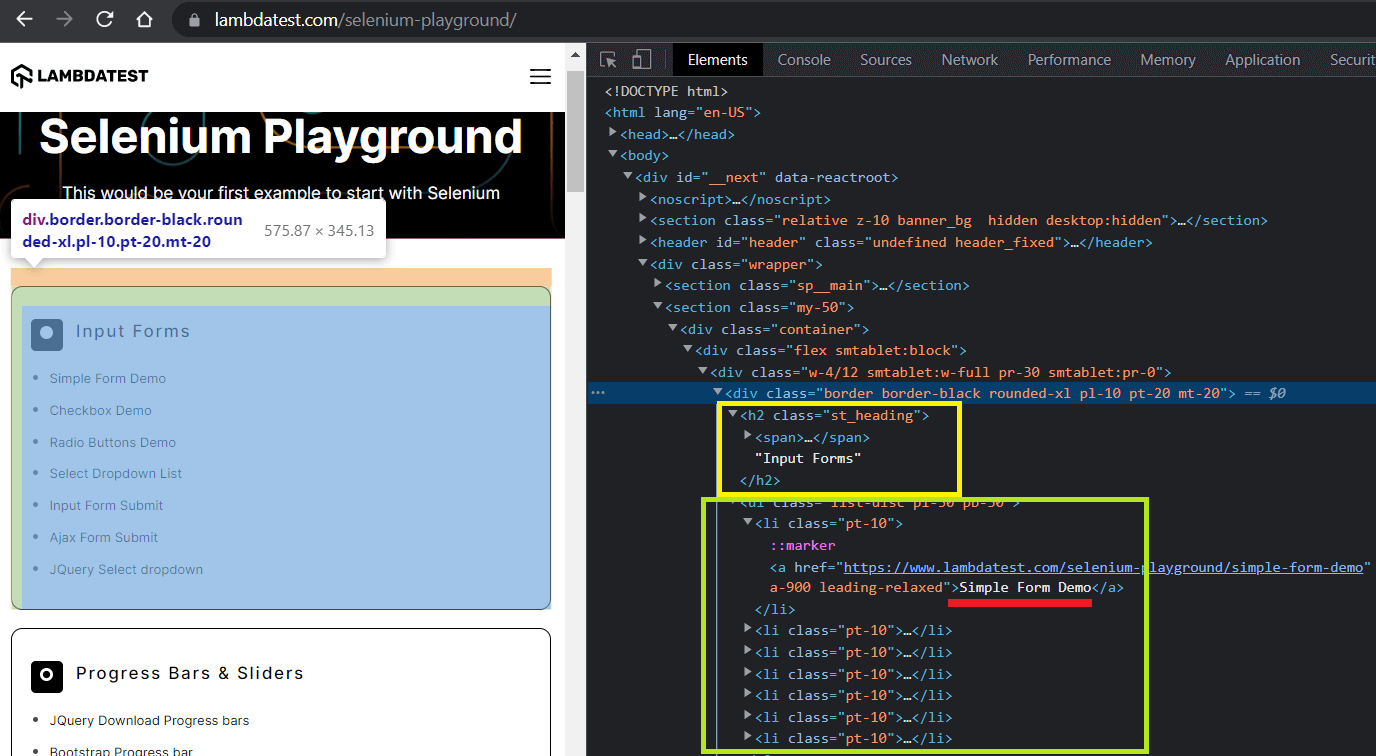
Primarily based on the inspection, we iterate over the bottom locator and for every div
- get the heading utilizing its relative XPath //h2.
- get the textual content from the hyperlink utilizing Xpath //ul/li and all_inner_texts() methodology.
- get the hyperlink url utilizing Xpath //ul/li/a and get_attribute(‘href’) component deal with.
The outermost for loop iterates over the outer container, the interior for loop will get the part title & the innermost for loop is for iterating over the record.

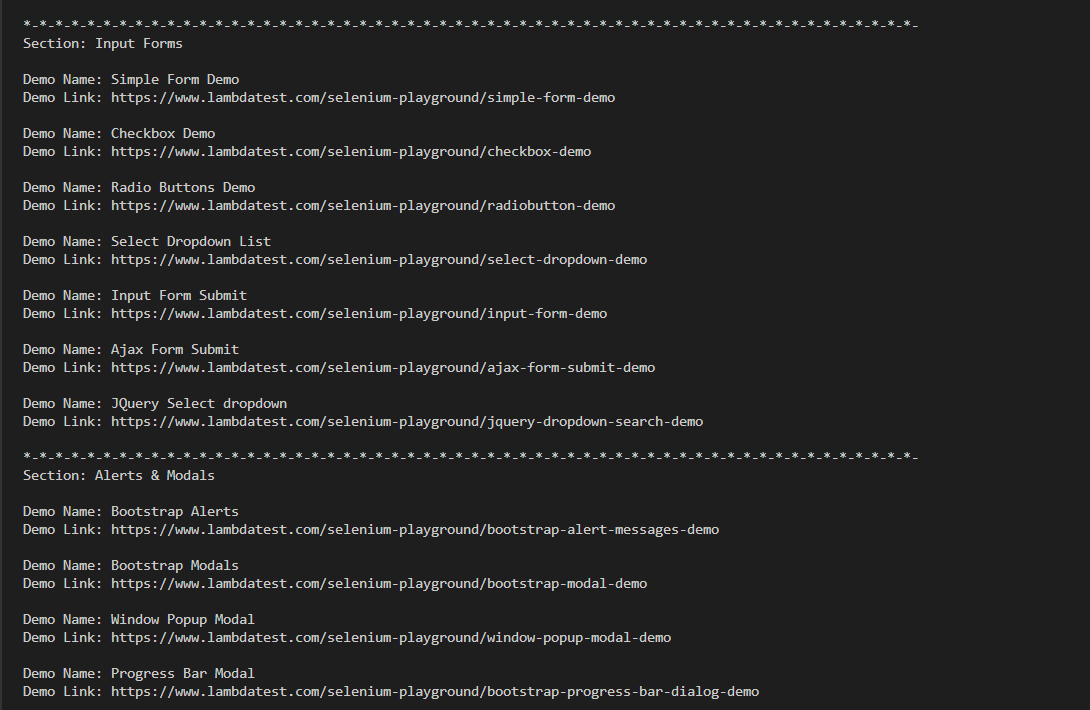
Execution:
Hey presto !!! Right here is the truncated execution snapshot from the VS Code. We now have a group of tutorials to go to at any time when we want to.
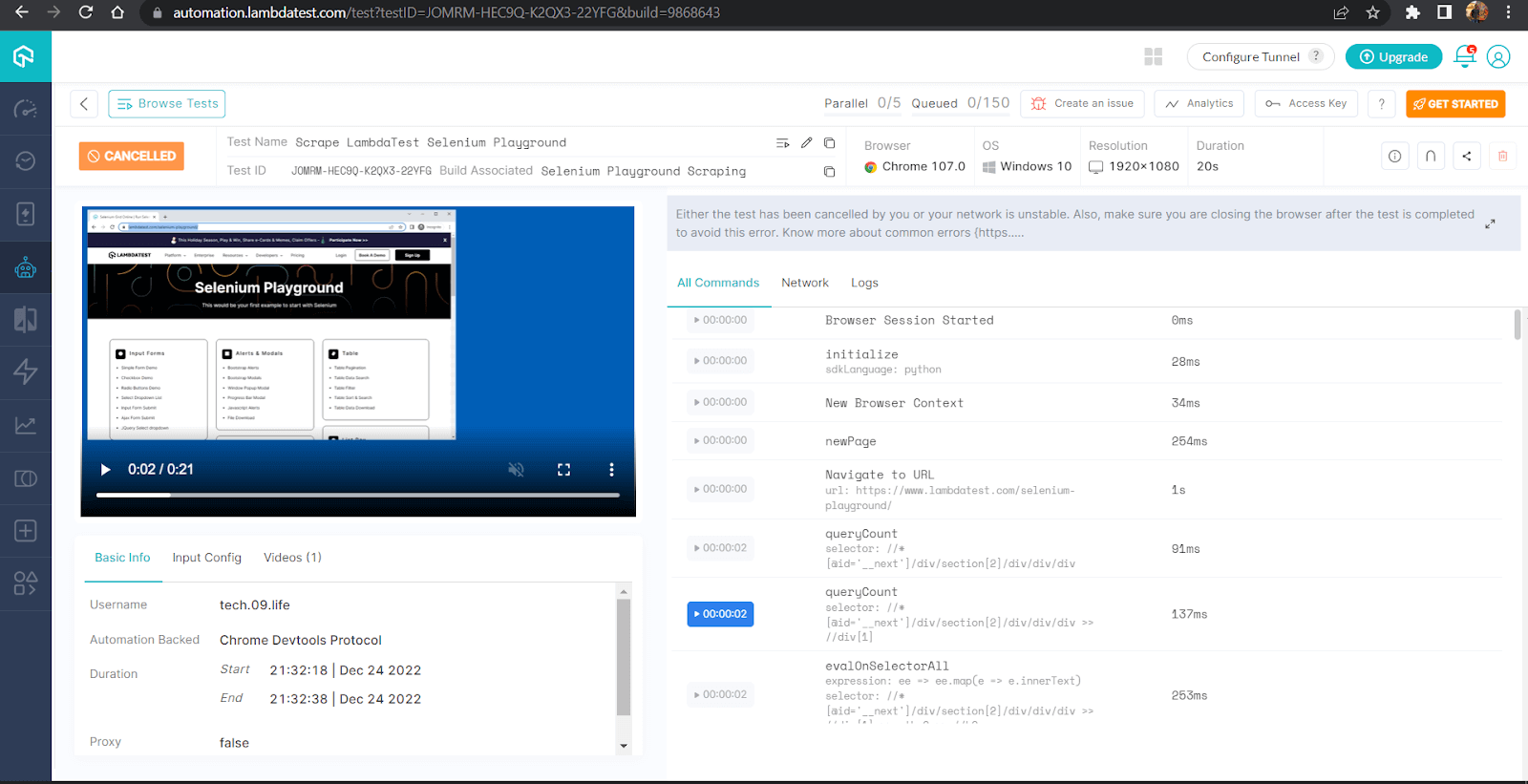
Here’s a snapshot from the LambdaTest dashboard, which exhibits all of the detailed execution together with video seize & logs of all the course of.


The Playwright 101 certification by LambdaTest is designed for builders who need to show their experience in utilizing Playwright for end-to-end testing of recent net functions. It’s the supreme option to showcase your abilities as a Playwright automation tester.
Conclusion
Python Playwright is a brand new however highly effective software for net scraping that permits builders to simply automate and management the conduct of net browsers. Its wide selection of capabilities & capacity to help completely different browsers, working programs, and languages makes it a compelling selection for any browser associated process.
On this weblog on utilizing Playwright for net scraping, we discovered intimately easy methods to arrange Python and use it with Playwright for net scraping utilizing its highly effective built-in locators utilizing each XPath & CSS Selectors.
It’s nicely value contemplating Python with Playwright for net scraping in your subsequent scraping mission, as it’s a helpful addition to the net scraping toolkit.