


{kind=link}
This tutorial explains get distinctive values from a column in Pandas DataFrame, together with examples.
Discover Distinctive Values in a Column
df['columnName'].distinctive()
Discover Distinctive Values in All Columns
for column in df.columns:
unique_values = df[column].distinctive()
print(f"Distinctive values in column '{column}': {unique_values}")
Discover Distinctive Values in A number of Columns
# Loop by way of specified columns and discover distinctive values
selected_columns = ['Students', 'Section']
for column in selected_columns:
unique_values = df[column].distinctive()
print(f"Distinctive values in column '{column}': {unique_values}")
Discover Distinctive Values Based mostly on A number of Columns
df.drop_duplicates(subset=['Students', 'Section'])
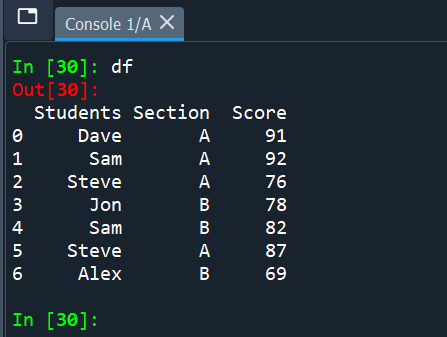
Pattern DataFrame
Let’s create a pattern pandas DataFrame to clarify examples on this tutorial.
import pandas as pd
df = pd.DataFrame({
'College students':["Dave","Sam","Steve","Jon","Sam","Steve","Alex"],
'Part':['A','A','A','B','B','A','B'],
'Rating':[91,92,76,78,82,87,69]
})
Instance 1 : Discover Distinctive Values in a Column
On this instance, we’re utilizing the dataframe named “df” and the column of curiosity is “College students” which comprises duplicate values.
Methodology 1 : distinctive()
We’re utilizing the pandas distinctive() operate to get distinctive values from a column in a dataframe.
df['Students'].distinctive()
Output
The distinctive() technique returns a NumPy array of distinctive values.
array(['Dave', 'Sam', 'Steve', 'Jon', 'Alex'], dtype=object)Incase you need the distinctive values of the column as an inventory, you should utilize the tolist() operate.
df['Students'].distinctive().tolist()
Output
['Dave', 'Sam', 'Steve', 'Jon', 'Alex']Methodology 2 : drop_duplicates()
The drop_duplicates() technique is a DataFrame technique that removes duplicate rows from the DataFrame and return distinctive values.
df.College students.drop_duplicates()
Output
The drop_duplicates() technique returns a Sequence or DataFrame.
0 Dave
1 Sam
2 Steve
3 Jon
6 Alex
Title: College students, dtype: object
If you need all of the columns akin to the distinctive values within the column “College students”, you should utilize the subset parameter and specify particular columns for locating duplicates.
df.drop_duplicates(subset=['Students'])
Output
As proven within the output under, it returns a DataFrame with distinctive values within the “College students” column, holding all different columns.
College students Part Rating
0 Dave A 91
1 Sam A 92
2 Steve A 76
3 Jon B 78
6 Alex B 69
Instance 2 : Discover Distinctive Values in All Columns
We are able to use loop to get distinctive values in all of the columns in a dataframe one after the other.
for column in df.columns:
unique_values = df[column].distinctive()
print(f"Distinctive values in column '{column}': {unique_values}")
Output
Distinctive values in column 'College students': ['Dave' 'Sam' 'Steve' 'Jon' 'Alex']
Distinctive values in column 'Part': ['A' 'B']
Distinctive values in column 'Rating': [91 92 76 78 82 87 69]
Instance 3 : Discover Distinctive Values in A number of Columns
We are able to specify a number of columns from which we wish to extract distinctive values after which run a loop to get distinctive values of these columns one after the other. On this case, we’ve got two columns – ‘College students’ and ‘Part’ for fetching distinctive values.
selected_columns = ['Students', 'Section']
# Loop by way of specified columns and discover distinctive values
for column in selected_columns:
unique_values = df[column].distinctive()
print(f"Distinctive values in column '{column}': {unique_values}")
Output
Distinctive values in column 'College students': ['Dave' 'Sam' 'Steve' 'Jon' 'Alex']
Distinctive values in column 'Part': ['A' 'B']
Instance 4 : Discover Distinctive Values Based mostly on A number of Columns
If you wish to take away duplicates based mostly on a number of columns, you’ll be able to specify the columns within the subset argument within the drop_duplicates() operate.
df.drop_duplicates(subset=['Students', 'Section'])
Output
Within the output under, you’ll discover that solely “Steve” seems as soon as, and the duplicate has been eliminated.
College students Part Rating
0 Dave A 91
1 Sam A 92
2 Steve A 76
3 Jon B 78
4 Sam B 82
6 Alex B 69
Instance 5 : Rely Distinctive Values
To depend the variety of distinctive values, we will use the nunique() operate.
# Rely Distinctive Values in a Column df['Students'].nunique() # Rely Distinctive Values in A number of Columns df[['Students', 'Section']].nunique() # Rely Distinctive Values in All Columns df.nunique()
Instance 6 : Discover and Type Distinctive Values
If you wish to kind the distinctive values from the ‘College students’ column, you should utilize the distinctive() technique after which apply the sorted() operate to the outcome.
sorted(df['Students'].distinctive())
Output
['Alex', 'Dave', 'Jon', 'Sam', 'Steve']
Deepanshu based ListenData with a easy goal – Make analytics straightforward to grasp and observe. He has over 10 years of expertise in information science. Throughout his tenure, he labored with international purchasers in varied domains like Banking, Insurance coverage, Non-public Fairness, Telecom and HR.