


💡 Gradient Descent: What’s it? The place does it come from? And what the heck is it doing in my ANN?
You’ll be able to scroll by way of the slides as you watch this video right here:
This text goals to current the gradient descent algorithm in a lightweight trend, familiarizing new Machine Studying fans with this basic method… and convincing them that it’s not rocket science 😉
Gradient descent is a extensively identified optimization algorithm, broadly utilized in Machine Studying and several other areas of Arithmetic.
Extra particularly, in gradient descent we’re looking for the minimal of a given (differentiable) operate outlined on an -dimensional Euclidean area
,

💡 Normal Thought: The method begins by choosing up a (presumably random) level within the optimization area and following the route against the gradient of the operate at that time. After transferring a bit in direction of the desired route, you repeat the method ranging from the ensuing new level.
Subsequent, we clarify why gradients are the (reverse of the) proper route to comply with, and do it by way of a small caveat: gradients don’t exist…
Why Gradients?
…naturally. Gradients are ad-hoc objects ensuing from two different entities: the differential of the operate and the underlying metric of the Euclidean area.
It exists as a consequence of the linearity of the spinoff.
That’s, for each pair of vectors v and w, the differential within the route of v+w could be computed because the sum of the differential of v and the differential of w:

One other linear object is the internal product with a hard and fast vector: fixing a vector , one has that

Now, the well-known Riez Illustration Theorem connects the 2 linear objects above by guaranteeing the existence of a singular vector whose internal product coincides with computing the differential (guess which vector it’s):

and right here it’s the gradient.
One other expression for the internal product above makes use of the angle between
and v:

By inspecting it, we conclude that the differential of f at p realizes its most within the route of and maximally decreases in direction of
.
That’s to say, the unfavorable of the gradient factors in direction of the route of best discount of the operate. Subsequently, flowing alongside the unfavorable gradient appears a fantastic path to discover a (native) minimal.
Apart from, an train utilizing the unicity a part of the Riez’s Theorem reveals that the Euclidean coordinates of the vector representing is computed by way of the well-known expression:

However, again to our caveat, this expression doesn’t generalize to different coordinate techniques because the expressions in cylindrical and spherical coordinates present… and don’t assume you may be secure from non-Euclidean geometry for lengthy 😉
How Does Gradient Descent Relate to Machine Studying?
Gradient descent performs a central position in Machine Studying, being the algorithm of alternative to reduce the price operate.
The widespread Machine Studying job is to make use of plotted knowledge to foretell the worth of recent knowledge entries.
Exactly, given a set of labeled knowledge, that’s, tuples of options and goal values, the algorithm tries to suit a candidate modeling operate to it. The higher candidate is chosen because the one evaluating the minimal price operate amongst all candidates, and that’s the place the gradient descent comes into play.
To image this, allow us to check out the information in Housing Costs Competitors for Kaggle Be taught Customers, particularly the relation between Sale’s Value and Lot Space:

Determine 1: Scatter plot of the sale’s value of a home versus its Lot Space.
The best mannequin utilized in Machine Studying is named linear regression, the place a line is fitted by way of the plotted factors. Such a process consists in selecting two parameters, the bias and the angular coefficient of the road, respectively b and a under:

A typical price operate for this job is the Imply Sq. Error (MSE), which is straight computed on the parameters a and b:

Right here stand for the Lot Space and the Sale’s Value of the i-th entry and n is the variety of factors plotted.
When the MSE is utilized to the linear regression case, the ensuing operate lies inside the particular class of convex features.
These have the great property of getting a singular minimal that’s achieved by way of gradient descent unbiased of the purpose you begin (so long as your studying charge shouldn’t be excessive).

Sadly the final case does lead us to such a simplified state of affairs, and the price operate might need a number of native minima. This can be a typical state of affairs in Synthetic Neural Networks.
Feedforward Neural Networks and Their Challenges
A extra complicated household of candidates is given by Neural Networks. Even so, within the particular case of Feedforward Neural Networks, a rephrasing of the final assertion is actually enlightening: a FNN is strictly (no more, nor lower than) one other household of candidate features.
As a substitute of utilizing a line to disclose a sample within the scattered plot, one makes use of a extra elaborate household of features. Specifically, the gradient descent works out of the field.
Within the case of FNN’s, the candidate operate is given by a composition of less complicated features:

whereas:
Activation features are theoretically arbitrary, however are often chosen as features whose spinoff could be simply calculated.
Because of the linearity of , and selection of easy activation features, the gradient of g could be effectively computed utilizing the chain rule.
Subsequently, the gradient of the price operate turns into a possible object through the use of the extra basic expression of the previous:

Be aware that x is a given knowledge entry and each different parameter described above is fastened a priori. Therefore, J is represented as a operate relying solely on the weights .
The gradient descent makes itself current as soon as extra being an inexpensive approach to discover native minima. On this case, although, J is often rather more sophisticated and a state of affairs much like the one under would possibly occur:
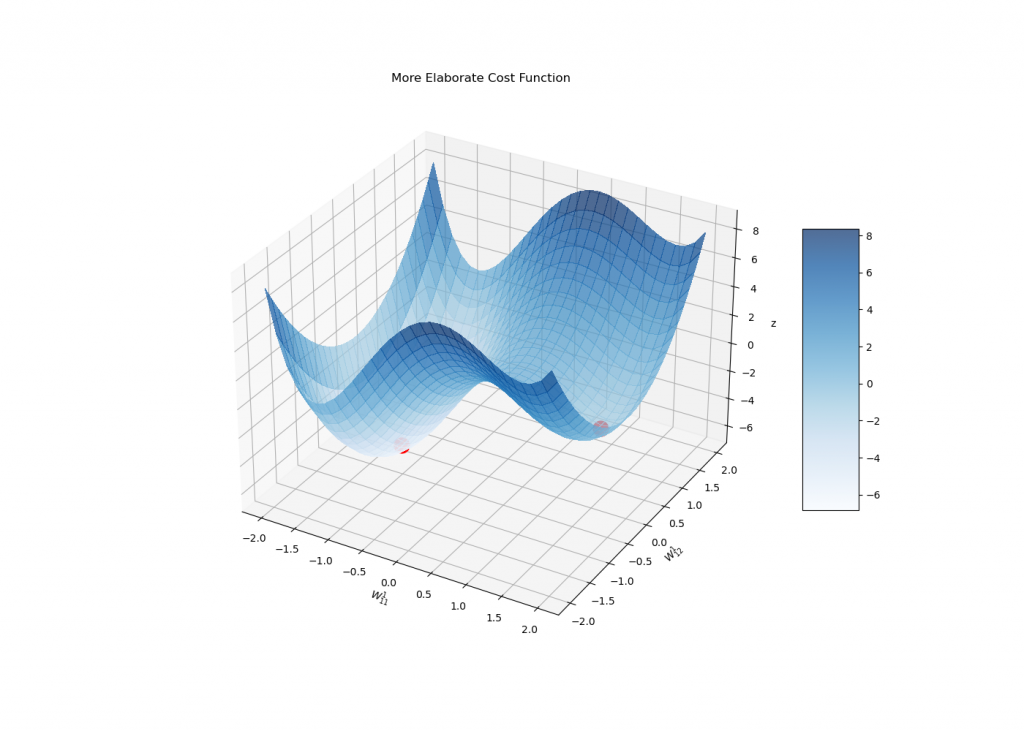
Observe how the gradient leads us to the flawed minima if not initialized rigorously:

Perhaps a facet view?
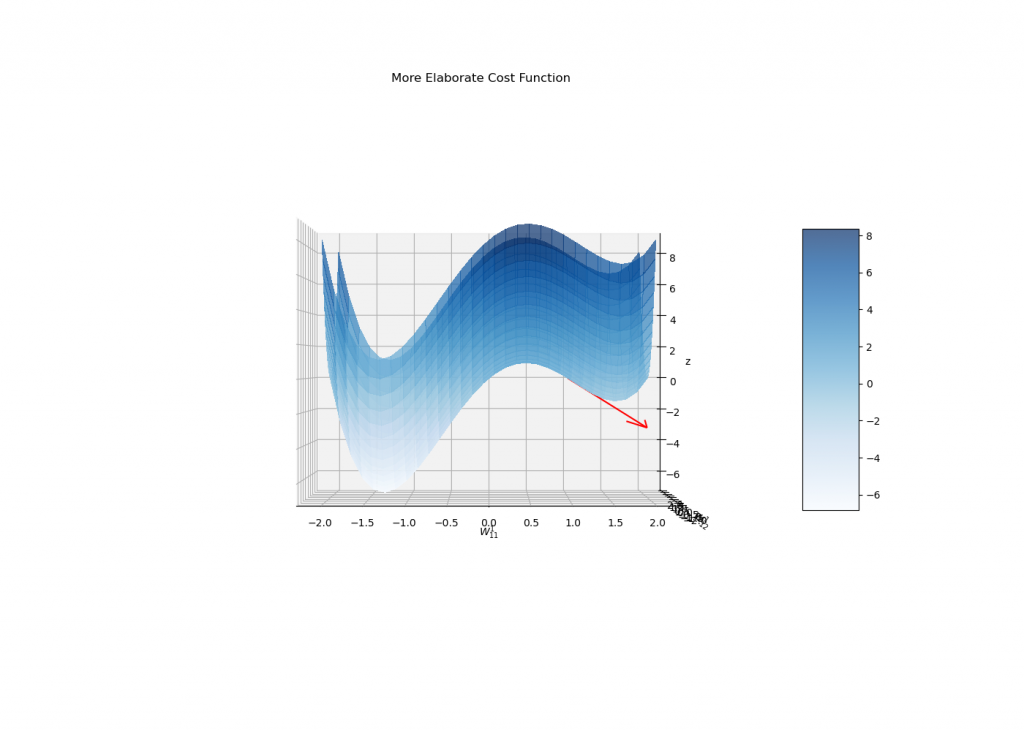
In reality, the stopping situation of the gradient descent is to achieve a important level of J, i.e., a degree whose gradient is zero.
On this sense, the algorithm itself won’t ever discriminate between reaching a world minimal or perhaps a saddle level (which isn’t even an area minima!), though the gradient move could be very unstable close to different sorts of important factors (and often don’t converge to them).
In any case, it is likely to be an inexpensive concept to ultimately initialize the gradient descent in a number of sparsely distributed random factors with a view to attain decrease price values.
Concluding Remarks
Gradient descent is a sturdy optimization methodology, extensively utilized in Machine Studying algorithms.
Though Neural Networks’ candidates current elaborate derivatives, don’t panic: your job in NN is to have enjoyable selecting the best structure, place to begin, studying charge and another stuff. The gradients and core mathematical calculations are all carried out by your favourite ML bundle.
For extra particulars on FNN, Wikipedia presents a well-tailored article on Backpropagation.
And when you didn’t purchase but the significance of utilizing gradient descent, take a couple of minutes to match it to a brute power methodology, on the part ‘Curse of dimensionality’ on this good article.
The weights on Neural Networks are often organized as tensors (TensorFlow = Tensor + (gradient) Stream, acquired it?). You’ll be able to be taught extra about them in Aaron’s nice article.
Pleased coding!