

{kind=link}
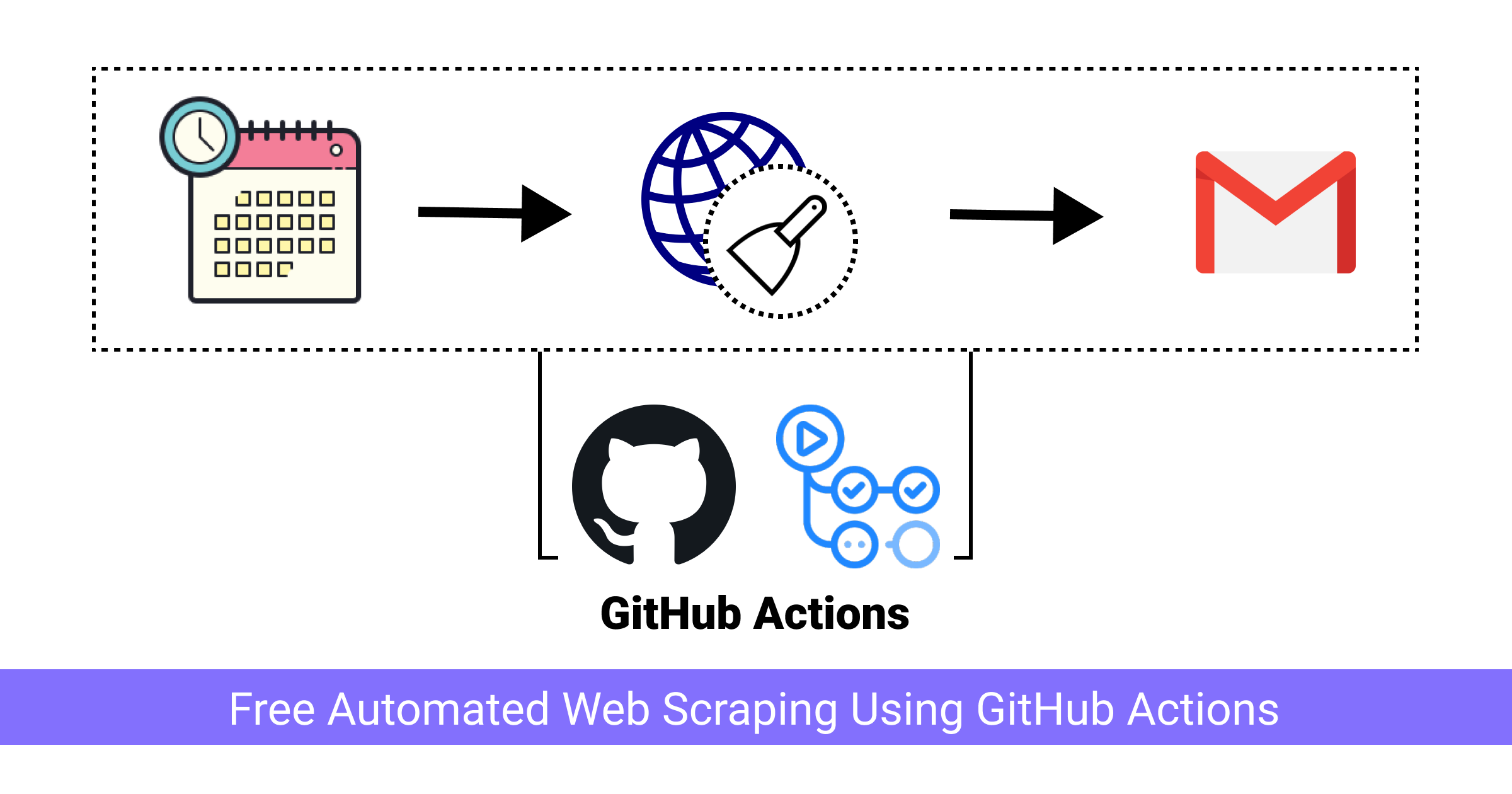
Hello everybody! 👋 It’s been a very long time since I final posted on this weblog. I used to be busy graduating from school and transferring locations and that didn’t go away sufficient time for enjoyable new tasks. I’m nonetheless in the midst of all of it however just lately did a challenge that gave me a tutorial concept to write down about. I used to be requested to create an internet scraper that might scrape a sure web site, filter the info after which ship an e-mail with that information. I’ll present you what I used to be tasked with, how I developed it, and the way I deployed it at no cost utilizing GitHub Actions.
Observe: Yow will discover the corresponding GitHub repo right here
Necessities
I used to be requested if I might write an utility that might monitor this web site under and extract tender info and e-mail solely the newest tenders to an e-mail id. I explored the web site and shortly agreed.

Plan of Motion
I had come throughout some enjoyable tasks by the likes of Simon Wilson and needed to check out GitHub Actions for myself. What higher solution to check it out than deploying a working scraper that mechanically runs on a schedule and emails the scraped information?
Step one is to obtain the online web page utilizing Python and pull out the desk right into a extra useable information construction. I opted for regex initially after which settled on Pandas for the preliminary extraction.
The following step is to e-mail the parsed information. For that, I’m going to depend on a GitHub motion created by Dawid Dziurla.
Putting in the required libraries
We will likely be making use of the next two libraries:
Go forward and add each of those libraries right into a necessities.txt file within the root of your challenge listing/repository and set up them for those who haven’t already. In a while, we will likely be utilizing this file to put in these dependencies within the GitHub Actions execution atmosphere.
Writing the scraper
That is by far essentially the most time-consuming a part of the entire course of. Nevertheless, it’s fairly easy as soon as you recognize what you’re doing. Step one is to determine the URL of the tenders web page. The web site makes use of AJAX so going to the tenders web page doesn’t change the URL within the handle bar. To seek out the precise URL, we will open up Developer Instruments and have a look at the requests made whereas navigating to the tenders web page.

This primary URL is the direct URL of the tenders web page nevertheless it doesn’t have a web page quantity within the URL. For it to make use of the web page quantity as properly we will navigate to the 2nd web page of the tenders and try the brand new request (discover the PageNo=2 on the finish of the URL). We are able to now comply with the sample of this request to question for nevertheless many pages we would like.

At this level, we will write some Python code to obtain the web page utilizing requests.
import requests as r
html = r.get('https://ppra.org.pk/dad_tenders.asp?PageNo=1')
Now that we all know the best way to question for various pages, we have to determine the best way to parse the desk. I initially tried utilizing regex as for such easy use instances it has all the time labored out fairly properly for me. I learn about this SO reply however we’re parsing a recognized, restricted subset of HTML so it’s completely tremendous to make use of regex for that.
Nevertheless, regex posed a couple of points. It wasn’t working precisely the way in which I needed it to. I had forgotten in regards to the re.DOTALL flag whereas writing my preliminary sample and my regex sample wasn’t working previous the n character. As a substitute of fixing this situation, I made a decision to provide Pandas a strive. I had heard that you possibly can simply parse an HTML desk utilizing Pandas however I had by no means tried it so I thought of giving {that a} strive as a substitute.
My principal motivation for taking over new tasks is that I get to discover and study new stuff after which write about it on this weblog so I actively attempt to go for new strategies even when I do know the outdated methodology works completely tremendous. You’ll by no means study new and higher methods for those who don’t discover, proper?
Utilizing Pandas is extraordinarily simple. We are able to use the next snippet to parse the tables within the doc:
import pandas as pd
dfs = pd.read_html(html.textual content)
Nevertheless, by solely supplying the HTML to read_html methodology, Pandas extracts all of the tables from the web page. In my testing, this resulted in 4 tables.
>>> dfs
[ 0
0 Please Click on image to Download/View. Only 1..., 0 1
0 Tender Closing Date : Month January Feburay March April May Jun..., 0
0 PPRA Ref No: TSE, 0 1 2 3 4
0 Tender No Tender Details Download Advertised Date Closing Date
1 TS455000E Pakistan Aeronautical Complex, Kamra Procureme... NaN 30/7/2021 4/8/2021 10:30:00 AM
2 TS454835E Pakistan State Oil, Karachi Miscellaneous Work... NaN 30/7/2021 5/8/2021 2:15:00 PM
3 TS453722E State Life Insurance Corporation of Pakistan, ... NaN 30/7/2021 24/8/2021
4 TS453262E Sui Southern Gas Company Limited, Karachi SSGC... NaN 30/7/2021 23/8/2021 3:00:00 PM
5 TS455691E National Database and Registration Authority N... NaN 30/7/2021 16/8/2021 11:00:00 AM
6 TS453260E Sui Southern Gas Company Limited, Karachi SSGC... NaN 30/7/2021 23/8/2021 12:30:00 PM
7 TS456503E National Heritage & Intrigation Division, Isla... NaN 30/7/2021 24/8/2021 11:00:00 AM
...
To only extract the table we need, we can tell Pandas to extract the table with the width attribute set to 656. There is only one table in the whole HTML with that specific attribute value so it only results in 1 extracted table.
dfs = pd.read_html(html.text, attrs={'width': '656'})
>>> dfs
[ 0 1 2 3 4
0 Tender No Tender Details Download Advertised Date Closing Date
1 TS456131E Sui Southern Gas Company Limited, Karachi Supp... NaN 30/7/2021 25/8/2021 3:30:00 PM
2 TS456477E National Accountability Bureau, Sukkur Service... NaN 30/7/2021 16/8/2021 11:00:00 AM
3 TS456476E Sukkur Electric Power Company (SEPCO), Sukkur ... NaN 30/7/2021 12/8/2021 11:00:00 AM
4 TS456475E Evacuee Trust Property Board, Multan Services ... NaN 30/7/2021 17/8/2021 10:00:00 AM
5 TS456474E Military Engineering Services (Navy), Karachi ... NaN 30/7/2021 13/8/2021 11:30:00 AM
6 TS456473E National University of Science and Technology,... NaN 30/7/2021 17/8/2021 11:00:00 AM
7 TS456490E Shaikh Zayed Hospital, Lahore Miscellaneous Wo... NaN 30/7/2021 19/8/2021 11:00:00 AM
8 TS456478E Ministry of Religious Affairs & Interfaith Har... NaN 30/7/2021 16/8/2021 11:00:00 AM
9 TS456489E Cantonment Board, Rawalpindi Services Required... NaN 30/7/2021 17/8/2021 12:00:00 PM
10 TS456480E National Bank of Pakistan, Lahore Miscellaneou... NaN 30/7/2021 16/8/2021 11:00:00 AM
11 TS456481E National Bank of Pakistan, Lahore Miscellaneou... NaN 30/7/2021 16/8/2021 11:00:00 AM
...
There are still a few issues with this extraction.
- Pandas isn’t able to automatically extract header for our table
Advertised Datecolumn data isn’t parsed as a date- Download column is all
NaNs
To fix the first issue, we can pass in the header parameter to read_html and Pandas will make the respective row the header of the table. The second issue can be fixed by passing in parse_dates parameter and Pandas will parse the data in the respective column as dates. There are multiple ways to resolve the third issue. I ended up using regex to extract the download links into a list and then assigning that list to the Download column in our data frame.
The read_html method call looks something like this after fixing the first two issues:
dfs = pd.read_html(html.text, attrs={'width': '656'}, header=0, parse_dates=['Advertised Date'])
The regex for extracting the Obtain hyperlinks and assigning them to the Obtain column seems to be like this:
download_links = re.findall('<a goal="_blank" href="(.+?)"><img border="0" src="photos/(?:.+?)"></a>',html.textual content)
download_links = ["<a href="https://ppra.org.pk/"+link+"" style="display: block;text-align: center;"> <img src="https://ppra.org.pk/images/download_icon.gif"/></a>" for link in download_links]
tender_table = dfs[0]
tender_table['Download'] = download_links
The extracted hyperlinks are relative so we will use record comprehension to prepend the precise URL to the extracted hyperlink. I’m changing the hyperlink into an anchor tag and encapsulating a picture with that due to two causes. Firstly, it might look good in our last e-mail, and secondly, the desk would look much like what our shopper is used to seeing on the web site so there could be much less visible fatigue whereas wanting on the e-mail.
The shopper requested me to generate emails with the tenders for the newest date solely. The tenders for the newest date generally span a number of pages so we will put all of the code we’ve got to this point right into a separate operate after which move in web page numbers to that operate to extract the tables from a selected web page.
The code with the operate seems to be like this:
import requests as r
import pandas as pd
import re
url_template = "https://ppra.org.pk/dad_tenders.asp?PageNo="
def download_parse_table(url):
html = r.get(url)
dfs = pd.read_html(html.textual content, attrs={'width': '656'}, header=0, parse_dates=['Advertised Date'])
download_links = re.findall('<a goal="_blank" href="(.+?)"><img border="0" src="photos/(?:.+?)"></a>',html.textual content)
download_links = ["<a href="https://ppra.org.pk/"+link+"" style="display: block;text-align: center;"> <img src="https://ppra.org.pk/images/download_icon.gif"/></a>" for link in download_links]
tender_table = dfs[0]
tender_table['Download'] = download_links
return tender_table
To place all of the extracted tables into one information body, we have to put all of them into a listing and use the pd.concat methodology. The code for that appears like this:
combined_df = []
for index in vary(1,8):
df = download_parse_table(url_template+str(index))
combined_df.append(df)
combined_df = pd.concat(combined_df)
>>> combined_df
Tender No Tender Particulars Obtain Marketed Date Closing Date
0 TS455000E Pakistan Aeronautical Complicated, Kamra Procureme... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-30 4/8/2021 10:30:00 AM
1 TS454835E Pakistan State Oil, Karachi Miscellaneous Work... <a href="https://ppra.org.pk/doc/30-7/42pso307... 2021-07-30 5/8/2021 2:15:00 PM
2 TS453722E State Life Insurance coverage Company of Pakistan, ... <a href="https://ppra.org.pk/doc/30-7/42life30... 2021-07-30 24/8/2021
3 TS453262E Sui Southern Gasoline Firm Restricted, Karachi SSGC... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-30 23/8/2021 3:00:00 PM
4 TS455691E Nationwide Database and Registration Authority N... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-30 16/8/2021 11:00:00 AM
.. ... ... ... ... ...
25 TS456443E Civil Aviation Authority, Karachi TENDER NOTIC... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-29 13/8/2021 11:00:00 AM
26 TS454178E Zarai Taraqiati Financial institution Ltd (ZTBL), Islamabad Inf... <a href="https://ppra.org.pk/doc/28-7/ztb287-1... 2021-07-28 10/8/2021 11:00:00 AM
27 TS454566E Sui Northern Gasoline Pipelines Restricted, Lahore Rel... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-28 1/9/2021 3:30:00 PM
28 TS455579E Pakistan Ordnance Factories, Wah Cantt Restore ... <a href="https://ppra.org.pk/doc/28-7/pof287-4... 2021-07-28 4/8/2021 10:20:00 AM
29 TS455365E Pakistan Nationwide Transport Company (PNSC),... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-28 24/8/2021 11:00:00 AM
[210 rows x 5 columns]
It seems to be principally tremendous however there’s one situation. The index is preserved after the concat. I wish to reset it in order that it goes from 0-209 as a substitute of 0-29 a number of instances. That is additionally simple to acomplish. We simply want to change the concat methodology name like this:
combined_df = pd.concat(combined_df).reset_index(drop=True)
>>> combined_df
Tender No Tender Particulars Obtain Marketed Date Closing Date
0 TS455000E Pakistan Aeronautical Complicated, Kamra Procureme... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-30 4/8/2021 10:30:00 AM
1 TS454835E Pakistan State Oil, Karachi Miscellaneous Work... <a href="https://ppra.org.pk/doc/30-7/42pso307... 2021-07-30 5/8/2021 2:15:00 PM
2 TS453722E State Life Insurance coverage Company of Pakistan, ... <a href="https://ppra.org.pk/doc/30-7/42life30... 2021-07-30 24/8/2021
3 TS453262E Sui Southern Gasoline Firm Restricted, Karachi SSGC... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-30 23/8/2021 3:00:00 PM
4 TS455691E Nationwide Database and Registration Authority N... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-30 16/8/2021 11:00:00 AM
.. ... ... ... ... ...
205 TS456443E Civil Aviation Authority, Karachi TENDER NOTIC... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-29 13/8/2021 11:00:00 AM
206 TS454178E Zarai Taraqiati Financial institution Ltd (ZTBL), Islamabad Inf... <a href="https://ppra.org.pk/doc/28-7/ztb287-1... 2021-07-28 10/8/2021 11:00:00 AM
207 TS454566E Sui Northern Gasoline Pipelines Restricted, Lahore Rel... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-28 1/9/2021 3:30:00 PM
208 TS455579E Pakistan Ordnance Factories, Wah Cantt Restore ... <a href="https://ppra.org.pk/doc/28-7/pof287-4... 2021-07-28 4/8/2021 10:20:00 AM
209 TS455365E Pakistan Nationwide Transport Company (PNSC),... <a href="https://ppra.org.pk/obtain.asp?have a tendency... 2021-07-28 24/8/2021 11:00:00 AM
[210 rows x 5 columns]
This seems to be a lot better!
Subsequent we have to filter this information for the newest date. We are able to try this utilizing simply two traces:
latest_date = combined_df.iloc[0]['Advertised Date']
filtered_df = combined_df[combined_df['Advertised Date'] == latest_date]
We first extract the newest date which is the Marketed Date of the primary merchandise within the desk after which filter the remainder of the desk utilizing that worth.
Now we will convert this into an HTML desk. Pandas doesn’t create a full HTML doc so we have to create one ourselves after which embed the Pandas output in it:
html_string = """
<html>
<head><title>Newest PPRA Tenders</title></head>
<physique>
<fashion>
desk {
border-collapse: collapse;
border: 1px stable silver;
}
desk tr:nth-child(even) {
background: #E0E0E0;
}
</fashion>
%s
</physique>
</html>
"""
table_html = filtered_df.to_html(index=False,render_links=True, justify="middle",
escape=False, border=4)
with open('ppra.html', 'w') as f:
f.write(html_string %(table_html))
I used the %s string interpolation methodology as a result of I’ve some <fashion> tags with {} braces and it confuses Python if I exploit the f-strings.
After working what we’ve got to this point, the output (ppra.html) seems to be like this:
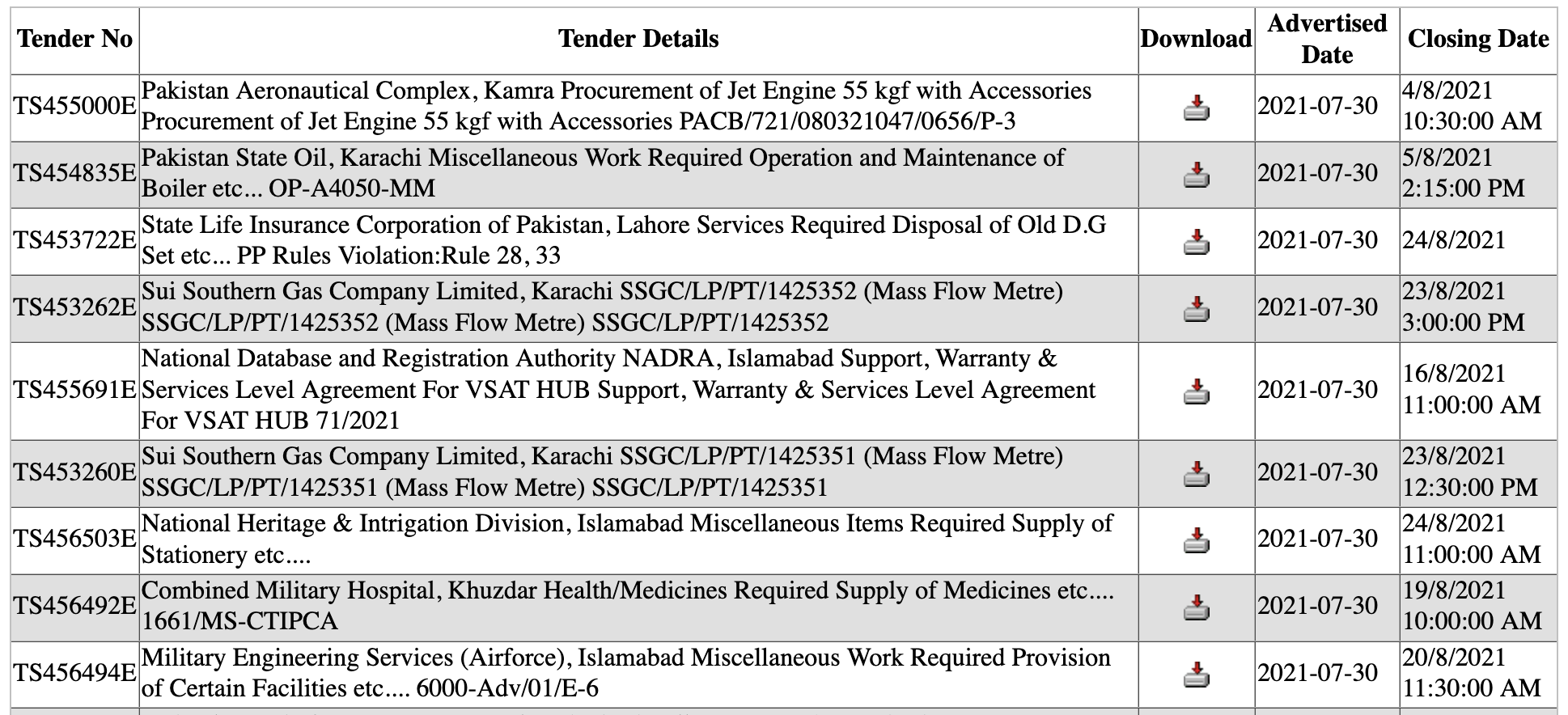
There’s one situation, the Tender Particulars column seems to be very cluttered. As a substitute of placing the main points information in a single font-weight and on the identical line, we have to break it up as they do on the unique web site. The best approach to try this is to extract the main points utilizing regex after which change the main points within the information body with the extracted ones.
The regex for particulars extraction seems to be one thing like this:
particulars = re.findall('<td bgcolor="(?:.+?)" width="305">(.+?)</td>', html.textual content, re.DOTALL)
The element cells have a selected width so we extract the info primarily based on that. We use re.DOTALL as a result of the main points span a number of traces and we would like . to match the carriage return (r) and newline character (n) as properly. The extracted particulars include rn and we will eliminate them utilizing this record comprehension:
particulars = [detail.replace('rn','') for detail in details]
Let’s assign this particulars record to our information body:
tender_table["Tender Details"] = particulars
Ultimate scraper code
The ultimate scraper code seems to be like this:
import requests as r
import pandas as pd
import re
url_template = "https://ppra.org.pk/dad_tenders.asp?PageNo="
html_string = """
<html>
<head><title>Newest PPRA Tenders</title></head>
<physique>
<fashion>
desk {
border-collapse: collapse;
border: 1px stable silver;
}
desk tr:nth-child(even) {
background: #E0E0E0;
}
</fashion>
%s
</physique>
</html>
"""
def download_parse_table(url):
html = r.get(url)
particulars = re.findall('<td bgcolor="(?:.+?)" width="305">(.+?)</td>', html.textual content, re.DOTALL)
particulars = [detail.replace('rn','') for detail in details]
dfs = pd.read_html(html.textual content, attrs={'width': '656'}, header=0,
parse_dates=['Advertised Date'])
download_links = re.findall(
'<a goal="_blank" href="(.+?)"><img border="0" src="photos/(?:.+?)"></a>',
html.textual content)
download_links = ["<a href="https://ppra.org.pk/"+link+"" style="display: block;text-align: center;"> <img src="https://ppra.org.pk/images/download_icon.gif"/></a>" for link in download_links]
tender_table = dfs[0]
tender_table['Download'] = download_links
tender_table["Tender Details"] = particulars
return tender_table
combined_df = []
for index in vary(1,8):
df = download_parse_table(url_template+str(index))
combined_df.append(df)
combined_df = pd.concat(combined_df).reset_index(drop=True)
latest_date = combined_df.iloc[0]['Advertised Date']
filtered_df = combined_df[combined_df['Advertised Date'] == latest_date]
table_html = filtered_df.to_html(index=False,render_links=True, justify="middle",
escape=False, border=4)
with open('ppra.html', 'w') as f:
f.write(html_string %(table_html))
Getting began with Github Motion
I’m going to maintain this intro to GitHub Actions very quick. GitHub Actions have an idea of workflows. Actions will execute workflows. These workflows are contained contained in the .github/workflows folder within the root of the repo and record the steps we would like Actions to execute. I went forward and created a .github/workflows folder in my challenge root after which created a scrape.yml file contained in the workflows folder. GH Actions would make extra sense if I present you the entire YAML file after which clarify it.
The contents of the scrape.yml file are this:
title: Scrape
on:
schedule:
- cron: "0 4 * * *"
workflow_dispatch:
env:
ACTIONS_ALLOW_UNSECURE_COMMANDS: true
jobs:
scrape-latest:
runs-on: ubuntu-latest
steps:
- title: Checkout repo
makes use of: actions/checkout@v2
- title: Arrange Python
makes use of: actions/setup-python@v2.0.0
with:
python-version: '3.7'
- title: Set up necessities
run: pip set up -r necessities.txt
- title: Run Scraper
run: python scraper.py
- title: Set env vars
run: |
echo "DATE=$(python -c 'import datetime as dt; print(dt.datetime.now().date())')" >> $GITHUB_ENV
- title: Ship mail
makes use of: dawidd6/action-send-mail@v3
with:
server_address: smtp.gmail.com
server_port: 465
username: ${{secrets and techniques.MAIL_USERNAME}}
password: ${{secrets and techniques.MAIL_PASSWORD}}
topic: Newest PPRA tenders for ${{env.DATE}}
to: hello@yasoob.me
from: Automated Electronic mail
ignore_cert: true
safe: true
html_body: file://ppra.html
We begin by naming the Motion. In our case, we named it Scrape. Subsequent, we inform GitHub when to execute this motion. The primary time is through a cron schedule and the second is through the net workflow dispatcher. The cron worth is much like the crontab you may need used on Linux. You need to use Crontab Guru to discover crontabs. The one I’m utilizing will trigger the workflow to run day-after-day at 4 o’clock. That is in UTC. The workflow_dispatch is used only for testing. This manner we don’t have to attend till 4 o’clock simply to check it and might set off the workflow manually utilizing the net interface.
Subsequent, we create an atmosphere variable to which our execution atmosphere could have entry. ACTIONS_ALLOW_UNSECURE_COMMANDS is required for Python on GitHub on account of a bug. I’m not certain whether it is fastened or not. Afterward, we set up Python, set up the necessities and run the scraper. Then we set the DATE variable to the present server time. This will likely be used within the topic of our e-mail.
For the e-mail sending half, I’m utilizing the superior send-email motion which makes the entire course of tremendous easy. I present it with my Gmail username and password and level it to the generated HTML file and it mechanically sends the e-mail.
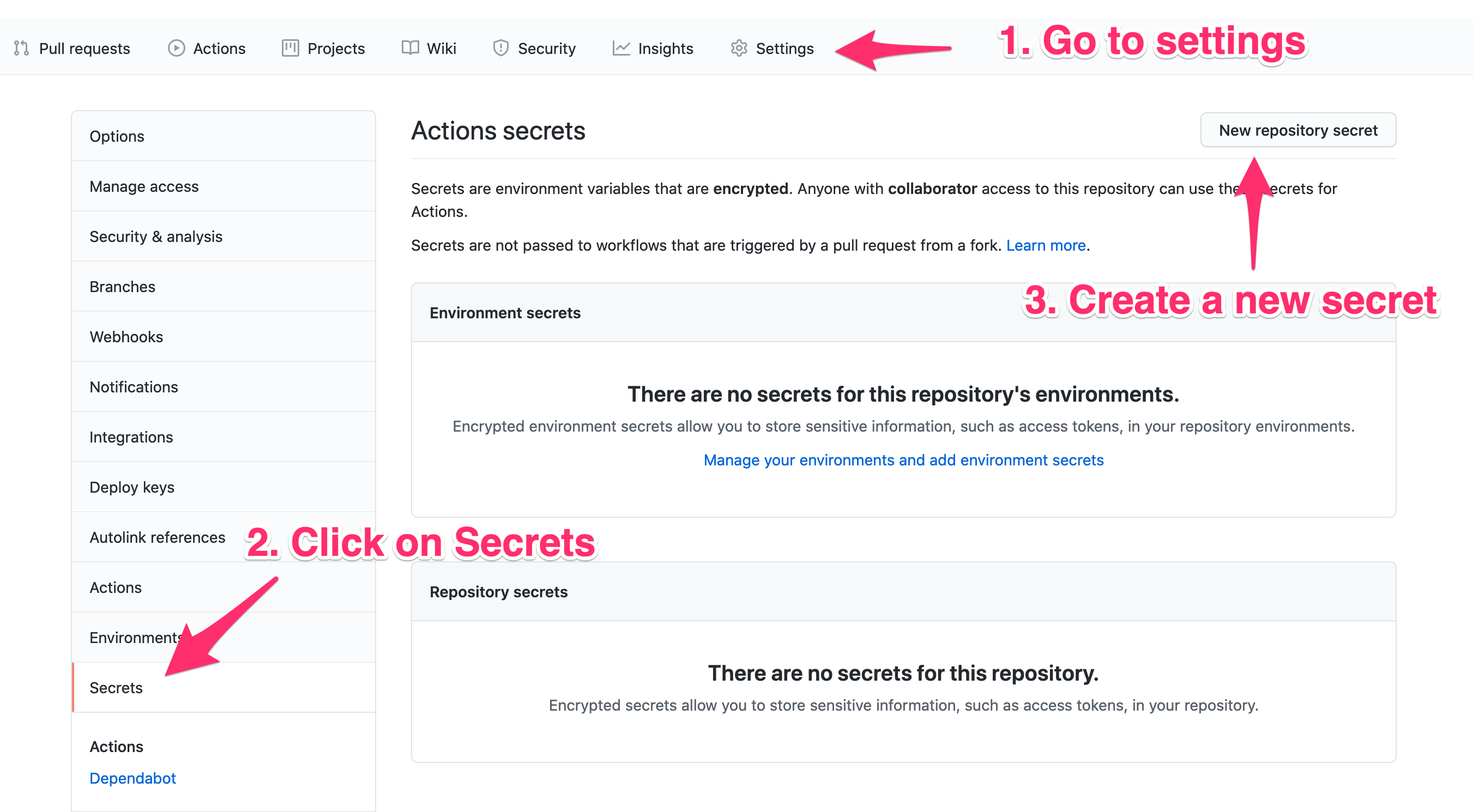
We additionally want to verify we configure the secrets and techniques within the repository settings web page in order that the send-email motion has entry to the MAIL_USERNAME and MAIL_PASSWORD.
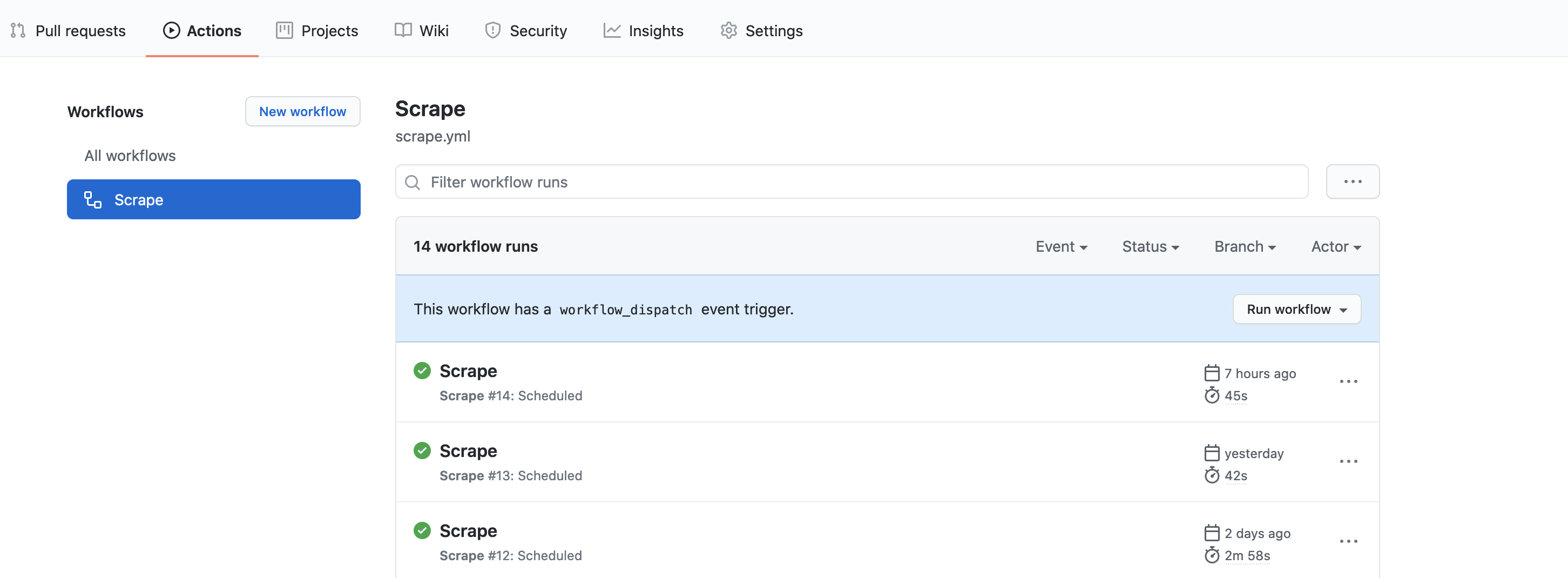
We are able to check the execution by pushing every part to GitHub after which going to the Actions tab of the repo. From there we will choose our workflow and manually set off it.
GitHub Actions Suggestions
The Motion has been working efficiently for a couple of days now. I’ve fallen in love with the simplicity of Actions. The one main situation is that you shouldn’t use the free model for something time-sensitive. The motion execution is sort of all the time delayed by a couple of minutes when utilizing the scheduler. For most straightforward instances it’s tremendous although. I’m additionally unsure if the state of affairs is any totally different below the paid plan. Nevertheless, for those who dispatch the workflow utilizing the net interface, it principally will get scheduled for execution straight away.
I’ll use Actions once more sooner or later when I’ve related tasks. The one factor to bear in mind is that Actions solely have a restricted quantity of free minutes. In the event you transcend this restrict, you’ll have to pay and the value varies primarily based on the working system. The free account is restricted to 2000 minutes per thirty days.
Conclusion
I hope you all loved this tutorial. Yow will discover the corresponding GitHub repo right here. I had a ton of enjoyable engaged on it. You probably have any questions, feedback, or options, please be happy to remark under or ship me an e-mail (hello @ yasoob.me) or a tweet. I do plan on writing a couple of bunch of different stuff however time is at a premium nowadays. Nevertheless, I hope the state of affairs would quickly change 😄 I’ll see you within the subsequent article ❤️