


A question with an index is typically 100 occasions quicker than a question with out an index, after all relying upon how huge your desk is, however, it’s essential to index on columns which can be incessantly used within the WHERE clause of the SELECT question, or which varieties a serious criterion for looking out within the database.
For instance within the Worker database, EmployeeId or EmployeeName are frequent situations to seek out an Worker within the database.
As I mentioned, there could be both clustered index or non clustered index within the database, the previous is used to resolve how knowledge is bodily saved in disk and that is why there could be just one clustered index on any desk.
On this article, we’ll discover extra about each of those indexes and study some key variations between clustered and non clustered indexes from the interview and efficiency perspective.
2 Kinds of Indexes in SQL
The Question optimizer is a element of the database, which decides whether or not to make use of an index or to not execute a SELECT question or if use index then which one. You’ll be able to even see, which index is used for executing your question by wanting on the question plan, a FULL TABLE SCAN means no index is used and each row of the desk is scanned by the database to seek out knowledge.
Then again INDEX UNIQUE SCAN or INDEX RANGE SCAN counsel use of Index for locating knowledge. By the Index additionally has there personal drawback as they make INSERT and UPDATE question slower they usually additionally want house. A cautious use of index is one of the simplest ways to go.
And in case you like variations in tabular format, here’s a good desk highlighting distinction between clustered and non-clustered index in SQL
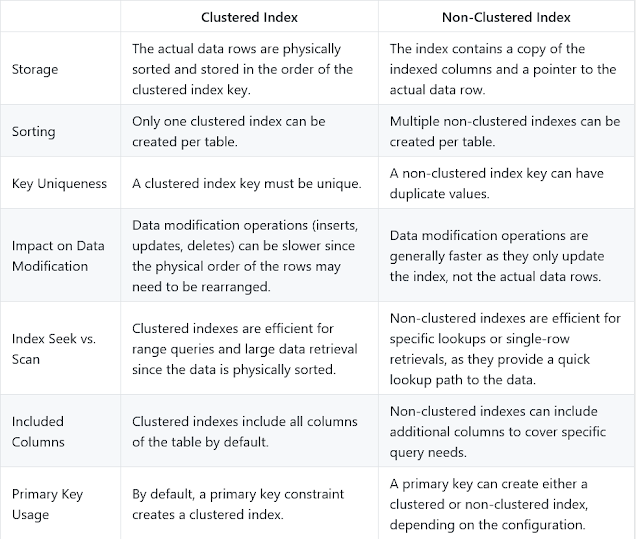
Clustered vs Non Clustered Index in SQL
Now we now have some thought about what’s Index in database and the way they work, it is time to look some key variations between clustered and non clustered index in SQL Server, which is usually true for different database as nicely e.g. Oracle or MySQL.
1) Restrict per desk
One of many essential variations between clustered and non clustered index in SQL Server is that one desk can solely have one clustered Index however It may well have many non clustered index, roughly 250. This limitation comes from the actual fact clustered index is used to determines how knowledge is saved bodily within the desk.
You ought to be very cautious whereas selecting clustered index and may use columns which could be queried in vary e.g. choose * from Worker the place EMP_ID > 20 and EMP_ID < 50. Since clustered index shops knowledge within the cluster, associated knowledge are saved collectively and it is simple for the database to retrieve all knowledge in a single shot. This additional reduces a lot of disk IO which is a really costly operation.
The Clustered Index can also be excellent on discovering distinctive values in a desk e.g. queries like choose * from Worker the place EMP_ID=40; could be very quick if EMP_ID has clustered index on it.
2) Major Key
One other key distinction between the Clustered Index and Non-Clustered Index within the database is that many relational databases together with SQL Server by default creates clustered index on the PRIMARY KEY constraint, if there isn’t any clustered index exists in database and a nonclustered index is just not specified whereas declaring PRIMARY KEY constraint.
3. Information vs Deal with
Another distinction between them is that clustered index comprises knowledge i..e rows of their leaf node, as Index is represented as BST, whereas nonclustered index comprises pointer to knowledge (tackle or rows) of their leaf node, which implies another additional step to get the information.
 4) By the way in which, there’s a false impression that we will solely outline clustered index with one column, which isn’t true. You’ll be able to create clustered index with a number of columns, often known as the composite index.
4) By the way in which, there’s a false impression that we will solely outline clustered index with one column, which isn’t true. You’ll be able to create clustered index with a number of columns, often known as the composite index. For instance in Worker desk, a composite index on firstname and lastname generally is a good clustered index, as a result of many of the question makes use of this as criterion. Although it is best to attempt to decrease the variety of columns within the clustered index for higher efficiency in SQL Server.
On a associated notice, whereas declaring composite index, pay some consideration to the order of columns within the index, which might resolve which assertion will use index and which won’t. In reality, this is likely one of the most requested questions as does the order of columns in composite index matter.
Final however not the least, pay some consideration whereas creating clustered and non clustered indexes within the database. Create a clustered index for columns that comprises distinctive values, are accessed sequentially, utilized in vary queries and return a big outcome set. Keep away from making a clustered index on columns, that are up to date incessantly as a result of that might result in rearrangement of rows on disk degree, a probably gradual operation.
That is all on the distinction between clustered and nonclustered index in SQL Server database. Do not forget that, it is doable to create clustered index on non PRIMARY KEY column and PRIMARY KEY constraint solely creates a clustered index, if there’s not already in database and a nonclustered index is just not offered. Key distinction is that, clustered index decides bodily sorting or order of knowledge in disk.