{kind=link}
Python Pandas Knowledge Body to CSV
Within the earlier tutorial, we realized the way to create a CSV file based mostly on Pandas Knowledge body. There, we used a single knowledge body based mostly on a listing after which created a CSV file through the use of Pandas DF’s to_csv technique.
On this tutorial, we’re going to share examples of making CSV information based mostly on a number of knowledge frames.
For the sake of simplicity, we’re utilizing nearly comparable forms of knowledge within the lists.
An instance of making CSV by two knowledge frames
On this instance, we’ve got two product lists that we’ll use to create a CSV file.
See the code and output beneath and we are going to clarify the way it labored.
The code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
|
import pandas as pd
#First Knowledge Body’s knowledge
product_list1 = [ [‘p001’, “Wheat”],
[‘p002’, “Rice”],
[‘p003’, “Sugar”]
]
#Second Knowledge Body’s knowledge
product_list2 = [ [“25.99”,“Out of Stock”],
[“8”,“In Stock”],
[“10”,“In Stock”]
]
#Creating knowledge body objects
df_1 = pd.DataFrame (product_list1, columns = [‘Product ID’, ‘Product Name’])
df_2 = pd.DataFrame (product_list2, columns = [‘Price’, ‘Status’])
#Concat and Write to CSV
pd.concat([df_1, df_2], axis=1).to_csv(‘multi_dfs.csv’) |
Output:
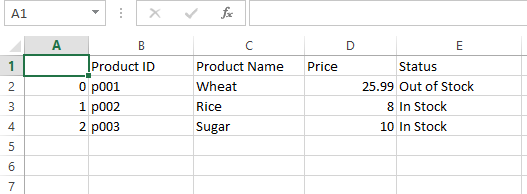
How above code work?
- To begin with, we imported the Pandas library
- That is adopted by creating two lists with completely different columns
- Then knowledge frames are created the place we specified these lists and column names
- Lastly, we used concat technique to concatenate each knowledge frames horizontally.
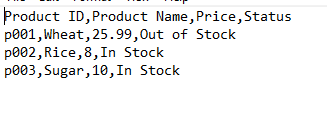
Writing with out index column
Within the above output pictures, chances are you’ll discover an index column “A” with numbers beginning at 0,1,..
To keep away from this, chances are you’ll use the index = False attribute within the to_csv technique as follows:
Code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
|
import pandas as pd
#First Knowledge Body’s knowledge
product_list1 = [ [‘p001’, “Wheat”],
[‘p002’, “Rice”],
[‘p003’, “Sugar”]
]
#Second Knowledge Body’s knowledge
product_list2 = [ [“25.99”,“Out of Stock”],
[“8”,“In Stock”],
[“10”,“In Stock”]
]
#Creating knowledge body objects
df_1 = pd.DataFrame (product_list1, columns = [‘Product ID’, ‘Product Name’])
df_2 = pd.DataFrame (product_list2, columns = [‘Price’, ‘Status’])
#Concat and Write to CSV with out Index column
pd.concat([df_1, df_2], axis=1).to_csv(‘multi_dfs.csv’, index=False) |
Output in Notepad:
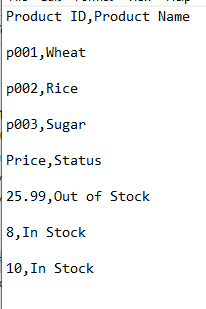
An instance of writing knowledge frames one after one other vertically
Chances are you’ll use the append mode in .to_csv technique for writing knowledge vertically. That’s, the second DF knowledge goes down after the primary DF, and so forth.
See the code beneath and output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
|
import pandas as pd
#First Knowledge Body’s knowledge
product_list1 = [ [‘p001’, “Wheat”],
[‘p002’, “Rice”],
[‘p003’, “Sugar”]
]
#Second Knowledge Body’s knowledge
product_list2 = [ [“25.99”,“Out of Stock”],
[“8”,“In Stock”],
[“10”,“In Stock”]
]
#Creating knowledge body objecst
df_1 = pd.DataFrame (product_list1, columns = [‘Product ID’, ‘Product Name’])
df_2 = pd.DataFrame (product_list2, columns = [‘Price’, ‘Status’])
#Utilizing mode=”a” for the second DF and so forth
df_1.to_csv(‘multi_dfs.csv’, index=False)
df_2.to_csv(‘multi_dfs.csv’, mode=‘a’, index=False) |
Output:
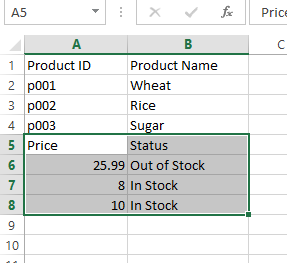
Second manner
So as to write second/different knowledge frames vertically, chances are you’ll iterate by means of every knowledge body with Python open technique and append the df.
See an instance beneath the place we are going to write the identical knowledge frames as within the above examples however vertically:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
|
import pandas as pd
#First Knowledge Body’s knowledge
product_list1 = [ [‘p001’, “Wheat”],
[‘p002’, “Rice”],
[‘p003’, “Sugar”]
]
#Second Knowledge Body’s knowledge
product_list2 = [ [“25.99”,“Out of Stock”],
[“8”,“In Stock”],
[“10”,“In Stock”]
]
#Creating knowledge body objecst
df_1 = pd.DataFrame (product_list1, columns = [‘Product ID’, ‘Product Name’])
df_2 = pd.DataFrame (product_list2, columns = [‘Price’, ‘Status’])
all_dfs = [df_1,df_2]
#Write to CSV vertically
with open(‘multi_dfs.csv’,‘a’) as f:
for df in all_dfs:
df.to_csv(f, index=False) |
Consequence: