

{kind=link}
Easy methods to Kind Knowledge Frames in Pandas
Pandas knowledge body has a sort_values methodology that’s used to kind the info body’s knowledge in ascending or descending order.
The sorting may be primarily based on column labels.
The sort_values methodology has completely different parameters as proven within the syntax under.
Syntax
DataFrame.sort_values(by, *, axis=0, ascending=True, inplace=False, sort=’quicksort’, na_position=’final’, ignore_index=False, key=None)
Allow us to present you examples of utilizing sort_values with its parameters under.
An instance of sorting outcomes by a column label in ascending order
Within the Python program under, we created an information body with three columns and 5 rows of knowledge.
Then we displayed the info body in its unique kind.
That is adopted through the use of the sort_values methodology the place we solely specified the column label to kind the outcomes.
Python program:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
|
import pandas as pd
#A listing for use for Knowledge Body
emp_data = [ [‘Emp1’, “Mike”, 5600],
[‘Emp2’, “Michelle”, 4750],
[‘Emp3’, “Ben”, 6500],
[‘Emp4’, “Shabee”, 3600],
[‘Emp5’, “Mina”, 3250]
]
#Creating knowledge body
df_emp = pd.DataFrame (emp_data, columns = [‘ID’, ‘Name’, ‘Salary’])
#Show knowledge body earlier than sorting
print(“DF in Orginal Order”)
print(df_emp)
#Show knowledge body after sorting
print(“===================”)
print(“DF After Sorting”)
print(df_emp.sort_values(by=‘Identify’)) |
Output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
|
DF in Orginal Order
ID Identify Wage
0 Emp1 Mike 5600
1 Emp2 Michelle 4750
2 Emp3 Ben 6500
3 Emp4 Shabee 3600
4 Emp5 Mina 3250
===================
DF After Sorting
ID Identify Wage
2 Emp3 Ben 6500
1 Emp2 Michelle 4750
0 Emp1 Mike 5600
4 Emp5 Mina 3250
3 Emp4 Shabee 3600 |
You’ll be able to see, the outcomes are sorted by Worker names within the knowledge body.
Sorting knowledge body in descending order
As it may be seen within the syntax, the default worth for sorting order is ascending i.e.
ascending=True
Through the use of the False worth, chances are you’ll get the info sorted in descending order.
See the instance under the place we used the identical knowledge body and sorted leads to descending order.
Program:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
|
import pandas as pd
#A listing for use for Knowledge Body
emp_data = [ [‘Emp1’, “Mike”, 5600],
[‘Emp2’, “Michelle”, 4750],
[‘Emp3’, “Ben”, 6500],
[‘Emp4’, “Shabee”, 3600],
[‘Emp5’, “Mina”, 3250]
]
#Creating knowledge body
df_emp = pd.DataFrame (emp_data, columns = [‘ID’, ‘Name’, ‘Salary’])
#Show knowledge body earlier than sorting
print(“DF in Orginal Order”)
print(df_emp)
#Show knowledge body after ascending=False
print(“===================”)
print(“DF After Sorting in Descending Order”)
print(df_emp.sort_values(by=‘Identify’, ascending=False)) |
Output:
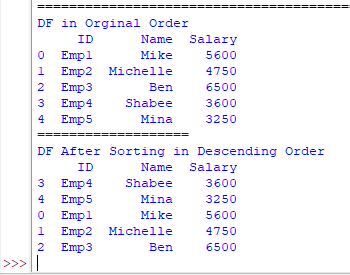
The instance of sorting by wage column
The instance under kinds the lead to descending order primarily based on the wage column:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
|
import pandas as pd
#A listing for use for Knowledge Body
emp_data = [ [‘Emp1’, “Mike”, 5600],
[‘Emp2’, “Michelle”, 4750],
[‘Emp3’, “Ben”, 6500],
[‘Emp4’, “Shabee”, 3600],
[‘Emp5’, “Mina”, 3250]
]
#Creating knowledge body
df_emp = pd.DataFrame (emp_data, columns = [‘ID’, ‘Name’, ‘Salary’])
#Kind outcomes by Highest to loweset wage
print(df_emp.sort_values(by=‘Wage’, ascending=False)) |
Consequence:
|
|
ID Identify Wage
2 Emp3 Ben 6500
0 Emp1 Mike 5600
1 Emp2 Michelle 4750
3 Emp4 Shabee 3600
4 Emp5 Mina 3250 |
Kind outcome by two columns instance
You may additionally kind the outcomes by offering two or extra columns.
The instance under kinds the outcomes by identify and wage columns in our instance knowledge body:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
|
import pandas as pd
#A listing for use for Knowledge Body
emp_data = [ [‘Emp1’, “Mike”, 5600],
[‘Emp2’, “Michelle”, 4750],
[‘Emp3’, “Ben”, 6500],
[‘Emp4’, “Shabee”, 3600],
[‘Emp5’, “Mina”, 3250]
]
#Creating knowledge body
df_emp = pd.DataFrame (emp_data, columns = [‘ID’, ‘Name’, ‘Salary’])
#Kind outcomes by a number of columns
print(df_emp.sort_values(by=[‘Name’, ‘Salary’], ascending=False)) |
Output:
|
|
ID Identify Wage
3 Emp4 Shabee 3600
4 Emp5 Mina 3250
0 Emp1 Mike 5600
1 Emp2 Michelle 4750
2 Emp3 Ben 6500 |
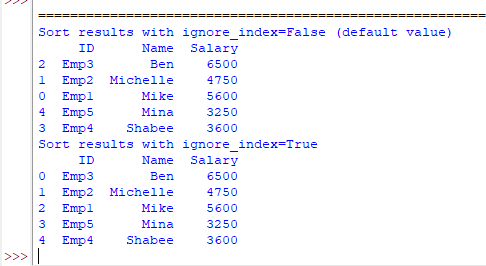
Utilizing ignore_index parameter instance
By default, the ignore_index= False. Which means the index column numbers stay in place after sorting the outcomes. Within the above instance output, you’ll be able to see 3, 4, 0, 1, 2, and the numbers which might be for the unique DF.
In the event you might ignore_index=True then the ensuing axis after sorting is labeled as 0,1, 2…
See the distinction within the instance under:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
|
import pandas as pd
#A listing for use for Knowledge Body
emp_data = [ [‘Emp1’, “Mike”, 5600],
[‘Emp2’, “Michelle”, 4750],
[‘Emp3’, “Ben”, 6500],
[‘Emp4’, “Shabee”, 3600],
[‘Emp5’, “Mina”, 3250]
]
#Creating knowledge body
df_emp = pd.DataFrame (emp_data, columns = [‘ID’, ‘Name’, ‘Salary’])
print(“Kind outcomes with ignore_index=False (default worth)”)
print(df_emp.sort_values(by=[‘Name’, ‘Salary’], ignore_index=False))
print(“Kind outcomes with ignore_index=True”)
print(df_emp.sort_values(by=[‘Name’, ‘Salary’], ignore_index=True)) |
Output:
Reference:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html