


{kind=link}
On it is personal, Google does an incredible job of parsing, inspecting, and conveying the content material of web-pages of their search outcomes. Nonetheless, as content material creators, we may also help Google perceive the that means of a web page by embedding structured information in our markup. In an ideal world, I might have all of this structured information able to go. However, in actuality, I’ll try to retroactively squeeze my present content material right into a structured information format: JSON+LD. And, to get this accomplished, I’ll use jSoup to find and extract picture URLs in my ColdFusion 2021 weblog.
For some time now, I have been utilizing jSoup to cleanup and normalize my content material. In reality, this is not even the primary time that I’ve used jSoup to remodel my content material for brand new use-cases: earlier this yr, I checked out utilizing jSoup to extract Open Graph / Twitter playing cards in ColdFusion.
On this put up, I am making use of that very same technique: utilizing jSoup to parse my weblog put up right into a Doc Object Mannequin (DOM) such that I can question it and extract free-form data-points to be used inside my JSON+LD web page aspect.
JSON+LD is a lightweight “Linked Information” format that makes use of JSON (JavaScript Object Notation) to outline machine-readable info. And, we are able to present this information to Google’s search bot by together with a <script> tag of kind="software/ld+json" in our <head> aspect. For instance:
<!doctype html>
<html lang="en">
<head>
<title>
ColdFusion is so Fantastic!
</title>
<script kind="software/ld+json">
{
"@context": "https://schema.org",
"@kind": "NewsArticle",
"headline": "ColdFusion is so Fantastic!",
"picture": [],
"datePublished": "2022-08-21T07:05:00Z",
"writer": [
{
"@type": "Person",
"name": "Ben Nadel",
"jobTitle": "Principal Engineer",
"url": "https://www.bennadel.com/about/about-ben-nadel.htm"
}
]
}
</script>
</head>
<physique>
<!--- Physique of your doc. --->
</physique>
</html>
With the info above, there’s actually no want for jSoup. It is that picture property that requires a little bit extra elbow-grease. I want to make use of jSoup to parse my content material in order that I can seek for embedded pictures, extract them, and supply them within the JSON+LD construction.
This is a truncated model of the ColdFusion part that prepares the info from my blog-detail web page. Discover that I’m querying the Doc Object Mannequin for picture tags with a src attribute that time to my uploads folder:
part {
/**
* I get the JSON+LD structured information for the given put up.
*/
non-public struct perform getStructuredData( required struct put up ) {
var dom = jSoupJavaLoader
.create( "org.jsoup.Jsoup" )
.parse( put up.content material )
.physique()
;
// CAUTION: We all know that the partial-normalizer has changed all the useful resource
// uploads with CDN-based URLs. As such, all the uploaded pictures ought to already
// be fully-qualified URLs.
var pictures = dom
.choose( "img[src*='/resources/uploads/']" )
.map(
( node ) => {
return( node.attr( "src" ) );
}
)
;
var information = {
"@context": "https://schema.org",
"@kind": "NewsArticle",
"headline": "#encodeForHtml( put up.title.left( 110 ) )#",
"picture": pictures,
"datePublished": dateTimeFormat( put up.datePosted, "iso" ),
"dateModified": dateTimeFormat( put up.updatedAt, "iso" ),
"writer": [
{
"@type": "Person",
"name": "Ben Nadel",
"jobTitle": "Principal Engineer",
"url": "https://www.bennadel.com/about/about-ben-nadel.htm"
}
]
};
return( information );
}
}
As you’ll be able to see, I am finding my <img> components, mapping them onto an array of fully-qualified URLs, after which I am utilizing that array to outline the picture property within the JSON+LD construction. The one actual funky factor right here is that I’ve to encode the headline for an HTML context. Since this information goes to be rendered inside a <script> tag, I’ve to ensure that a closing </script> tag in my headline would not by chance break-out of the JSON-LD definition.
With this information in place, I then serialize and output in my website’s structure template:
<!--- Reset the output buffer. --->
<cfcontent kind="textual content/html; charset=utf-8" />
<cfoutput>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>
#encodeForHtml( request.template.metaTitle )#
</title>
<script kind="software/ld+json">
#serializeJson( request.template.structuredData )#
</script>
<!--- Truncated for demo. --->
</head>
<physique>
<!--- Truncated for demo. --->
</physique>
</html>
</cfoutput>
As soon as I had this stay, I used to be capable of validate it utilizing Schema.org’s JSON+LD Validator:
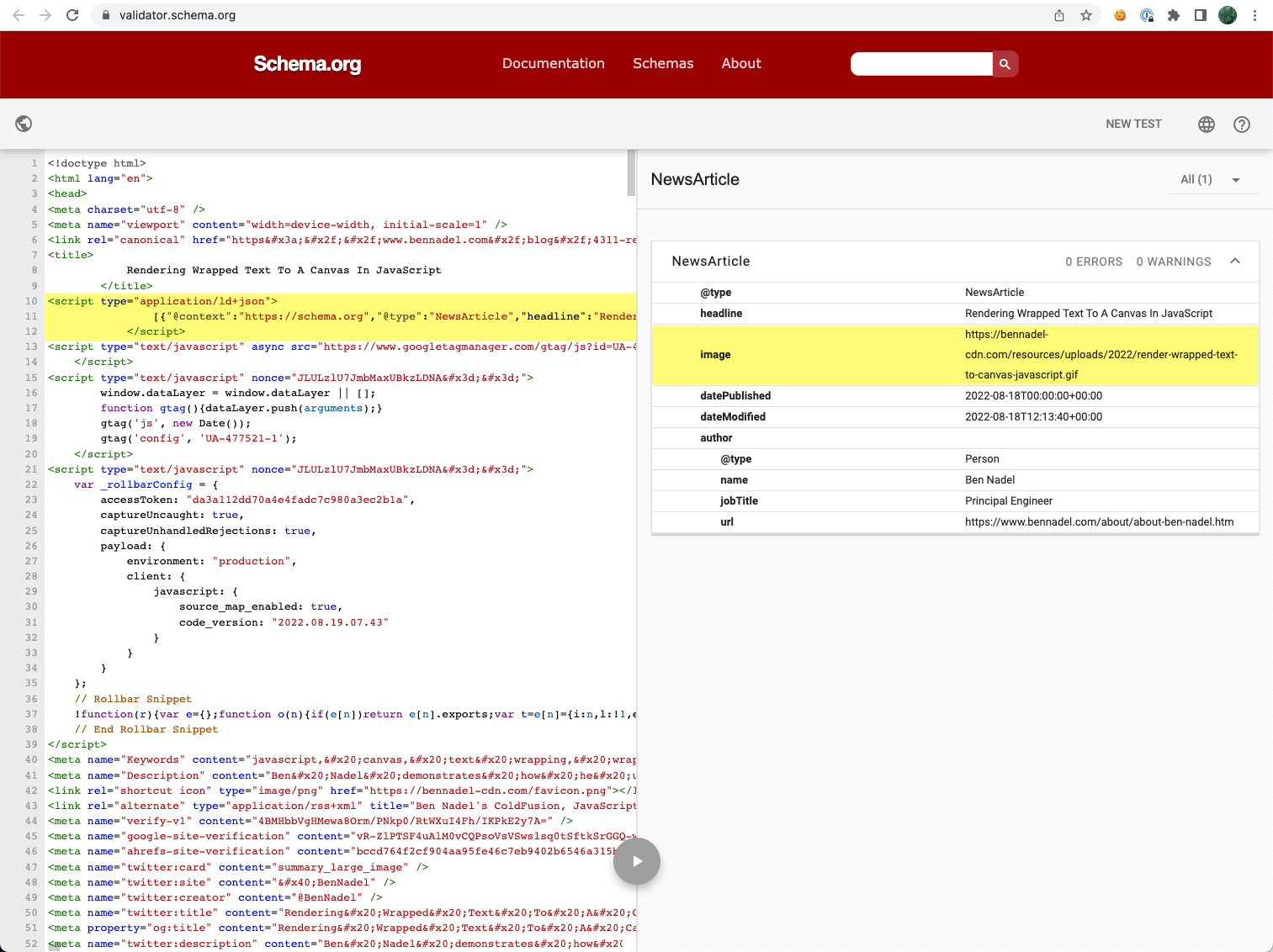
As you’ll be able to see, I used to be capable of efficiently extract the picture inside the given weblog put up and embody it inside my JSON+LD schema markup.
At the moment, I solely have JSON+LD information embedded inside my weblog’s article pages; however, I do consider that I can outline several types of entries for the varied pages on my ColdFusion weblog. And, to be clear, I do not know if this may really make one iota of a distinction by way of how the world (of machines) sees my weblog put up. However, I figured it will be price an experiment. If nothing else, it simply gave me yet another excuse to play with jSoup in ColdFusion.
Need to use code from this put up?
Try the license.