


{kind=link}
A few of the most necessary options in each persistence framework are those that allow us to question knowledge and retrieve it in our most popular format. In the very best case, you’ll be able to simply outline and execute commonplace queries, however you too can outline very advanced ones. Spring Knowledge JDBC gives you with all of this, and I’ll present you use these options on this article.
Because the identify signifies, Spring Knowledge JDBC is among the modules of Spring Knowledge and follows the identical ideas that you simply would possibly already know from different Spring Knowledge modules. You outline a set of entities that get mapped to database tables and group them into aggregates. For every mixture, you’ll be able to outline a repository. One of the simplest ways to try this is to increase considered one of Spring Knowledge JDBC’s commonplace repository interfaces. These offer you commonplace operations to learn and write entities and aggregates. For this text, I anticipate you to be conversant in repositories in Spring Knowledge. When you’re not, please check out the part about repositories in my introduction to Spring Knowledge JPA. They work in the identical method because the repositories in Spring Knowledge JDBC.
By default, Spring Knowledge JDBC’s repositories can solely fetch all entities of a particular sort or one entity by its major key. When you want a special question, it is advisable outline it your self. You should use Spring Knowledge’s widespread derived question function for easy queries. And if it will get extra advanced, you’ll be able to annotate the repository methodology with a @Question annotation and present your individual assertion. Earlier than we take a more in-depth have a look at each choices and focus on non-entity projections, let’s take a fast have a look at the area mannequin used on this article.
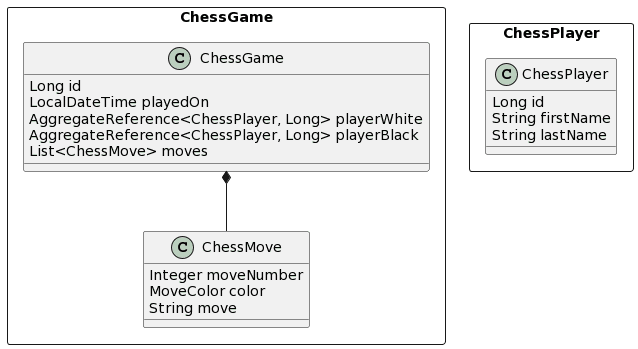
Instance area mannequin
The area mannequin that we are going to use within the examples of this put up consists of two aggregates. The ChessPlayer mixture solely consists of the ChessPlayer entity. The ChessGame mixture is impartial of the ChessPlayer and consists of the entity lessons ChessGame and ChessMove with a one-to-many affiliation between them. The ChessGame entity class additionally maps 2 overseas key references to the ChessPlayer mixture. Considered one of them references the participant with the white and the opposite to the participant taking part in the black items.
Derived queries in Spring Knowledge JDBC
Just like different Spring Knowledge modules, Spring Knowledge JDBC can generate a question assertion primarily based on the identify of a repository methodology. That is referred to as a derived question. A derived question is an effective way to generate a easy question assertion that doesn’t require JOIN clauses and doesn’t use greater than 3 question parameters.
Right here you’ll be able to see just a few typical examples of such queries.
public interface ChessGameRepository extends CrudRepository<ChessGame, Lengthy> {
Checklist<ChessGame> findByPlayedOn(LocalDateTime playedOn);
Checklist<ChessGame> findByPlayedOnIsBefore(LocalDateTime playedOn);
int countByPlayedOn(LocalDateTime playedOn);
Checklist<ChessGame> findByPlayerBlack(AggregateReference<ChessPlayer, Lengthy> playerBlack);
Checklist<ChessGame> findByPlayerBlack(ChessPlayer playerBlack);
}
Derived queries in Spring Knowledge JDBC observe the identical ideas as in different Spring Knowledge modules. In case your methodology identify matches one of many following patterns, Spring Knowledge JDBC tries to generate a question assertion:
- discover<some string>By<the place clause>
- get<some string>By<the place clause>
- question<some string>By<the place clause>
- exists<some string>By<the place clause>
- depend<some string>By<the place clause>
Spring Knowledge JDBC parses the <the place clause> and maps it to attributes of the entity class managed by the repository interface. Joins to different entity lessons are usually not supported.
By default, Spring Knowledge JDBC generates an equal comparability for every referenced attribute and compares it with a technique parameter with the identical identify. You possibly can customise the comparability through the use of key phrases like “After”, “Better Than”, “Like”, and “IsTrue”. You will discover a full checklist of all supported key phrases within the official documentation. It’s also possible to mix a number of parameters in your WHERE clause declaration utilizing the key phrases “And” and “Or”.
Primarily based on this info, Spring Knowledge JDBC generates an SQL assertion and executes it once you name the repository methodology in what you are promoting code.
Checklist<ChessGame> video games = gameRepo.findByPlayedOnIsBefore(LocalDateTime.of(2022, 05, 19, 18, 00, 00));
video games.forEach(g -> log.information(g.toString()));
2022-05-20 18:39:56.561 DEBUG 2024 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL question
2022-05-20 18:39:56.562 DEBUG 2024 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL assertion [SELECT "chess_game"."id" AS "id", "chess_game"."played_on" AS "played_on", "chess_game"."player_black" AS "player_black", "chess_game"."player_white" AS "player_white" FROM "chess_game" WHERE "chess_game"."played_on" < ?]
Please keep in mind that this function is designed for easy queries. As a rule of thumb, I like to recommend solely utilizing it for queries that don’t require greater than 2-3 question parameters.
Customized queries in Spring Knowledge JDBC
In case your question is simply too advanced for a derived question, you’ll be able to annotate your repository methodology with a @Question annotation and supply a database-specific SQL assertion. When you’re conversant in Spring Knowledge JPA, that is mainly the identical because the native question function, however it doesn’t require you to set the nativeQuery flag as a result of Spring Knowledge JDBC doesn’t present its personal question language.
As you’ll be able to see within the following code snippet, defining your individual question is so simple as it sounds, and you need to use all options supported by your database.
public interface ChessGameRepository extends CrudRepository<ChessGame, Lengthy> {
@Question("""
SELECT g.*
FROM chess_game g
JOIN chess_move m ON g.id = m.chess_game
WHERE m.transfer = :transfer
""")
Checklist<ChessGame> findByMovesMove(String transfer);
}
On this case, I exploit a press release that selects all columns of the chess_game desk of every sport by which the offered transfer was performed. The strikes are saved within the chess_move desk, which will get mapped to the ChessMove entity class. Within the SQL assertion, I exploit a easy JOIN clause to affix the two tables and supply a WHERE clause to filter the consequence.
The WHERE clause makes use of the named bind parameter :transfer, and the repository methodology defines a technique parameter with the identical identify. When executing this assertion, Spring Knowledge JDBC mechanically units the worth of the tactic parameter transfer because the bind parameter with identify transfer.
As you’ll be able to see, the question itself doesn’t present any details about the format by which I wish to retrieve the chosen info. That is outlined by the return sort of the repository methodology. On this case, the SQL assertion selects all columns of the chess_game desk, and Spring Knowledge JDBC will map the consequence to ChessGame entity objects.
Checklist<ChessGame> video games = gameRepo.findByMove("e4");
video games.forEach(g -> log.information(g.toString()));
As you’ll be able to see within the log output, Spring Knowledge JDBC used the offered SQL assertion, set all methodology parameters as bind parameter values, and executed the question. And when it mapped the question consequence to ChessGame objects, it needed to execute an extra question to get all strikes performed within the sport and initialize the Checklist<ChessMove> strikes affiliation. That is referred to as an n+1 choose situation, which may trigger efficiency issues. One of the simplest ways to scale back the efficiency affect is to maintain your aggregates small and concise or use non-entity projections, which I’ll present within the subsequent part.
2022-05-20 19:06:16.903 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL question
2022-05-20 19:06:16.905 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL assertion [SELECT g.*
FROM chess_game g
JOIN chess_move m ON g.id = m.chess_game
WHERE m.move = ?
]
2022-05-20 19:06:17.018 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL question
2022-05-20 19:06:17.018 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL assertion [SELECT "chess_move"."move" AS "move", "chess_move"."color" AS "color", "chess_move"."move_number" AS "move_number", "chess_move"."chess_game_key" AS "chess_game_key" FROM "chess_move" WHERE "chess_move"."chess_game" = ? ORDER BY "chess_game_key"]
2022-05-20 19:06:17.037 INFO 16976 - – [ main] com.thorben.janssen.TestQueryMethod : ChessGame [id=16, playerBlack=IdOnlyAggregateReference{id=10}, playerWhite=IdOnlyAggregateReference{id=9}, moves=[ChessMove [moveNumber=1, color=WHITE, move=e4], ChessMove [moveNumber=1, color=BLACK, move=e5]]]
Non-entity/non-aggregate projections in Spring Knowledge JDBC
Entity objects are usually not the one projection supported by Spring Knowledge JDBC. It’s also possible to retrieve your question consequence as Object[] or map every document to a DTO object. Working with Object[]s may be very uncomfortable and will get solely hardly ever used. I like to recommend utilizing the DTO projection for all use instances that don’t require your entire mixture. That ensures that you simply don’t execute any pointless statements to initialize associations you’re not utilizing and improves the efficiency of your utility.
To make use of a DTO projection, it is advisable outline a DTO class. That’s a easy Java class with an attribute for every database column you wish to choose. Sadly, Spring Knowledge JDBC doesn’t help interface-based projections, which you would possibly know from Spring Knowledge JPA.
public class ChessGamePlayerNames {
non-public Lengthy gameId;
non-public LocalDateTime playedOn;
non-public String playerWhiteFirstName;
non-public String playerWhiteLastName;
non-public String playerBlackFirstName;
non-public String playerBlackLastName;
// omitted getter and setter strategies for readability
@Override
public String toString() {
return "ChessGamePlayerNames [gameId=" + gameId + ", playedOn=" + playedOn + ", playerBlackFirstName="
+ playerBlackFirstName + ", playerBlackLastName=" + playerBlackLastName + ", playerWhiteFirstName="
+ playerWhiteFirstName + ", playerWhiteLastName=" + playerWhiteLastName + "]";
}
}
So long as the aliases of the chosen database columns match the attribute names of your DTO class, Spring Knowledge JDBC can map every document of your question’s consequence set mechanically. The one factor it is advisable do is to set the return sort of your repository methodology to your DTO class or a Checklist of your DTO lessons.
public interface ChessGameRepository extends CrudRepository<ChessGame, Lengthy> {
@Question("""
SELECT g.id as game_id,
g.played_on as played_on,
w.first_name as player_white_first_name,
w.last_name as player_white_last_name,
b.first_name as player_black_first_name,
b.last_name as player_black_last_name
FROM chess_game g
JOIN chess_player w ON g.player_white = w.id
JOIN chess_player b ON g.player_black = b.id
""")
Checklist<ChessGamePlayerNames> findGamePlayerNamesBy();
}
As you’ll be able to see, the question assertion and the projection are impartial of your aggregates and their boundaries. That’s one other good thing about a non-entity projection. It offers you the liberty and suppleness to fetch the info within the type that most closely fits what you are promoting logic.
Spring Knowledge JDBC executes the offered SQL assertion once you use that repository methodology in what you are promoting code. And when it retrieves the consequence, it maps every document of the consequence set to a ChessGamePlayerNames object.
Checklist<ChessGamePlayerNames> video games = gameRepo.findGamePlayerNamesBy();
video games.forEach(g -> log.information(g.toString()));
2022-05-20 19:09:16.592 DEBUG 12120 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL question
2022-05-20 19:09:16.593 DEBUG 12120 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing ready SQL assertion [SELECT g.id as game_id,
g.played_on as played_on,
w.first_name as player_white_first_name,
w.last_name as player_white_last_name,
b.first_name as player_black_first_name,
b.last_name as player_black_last_name
FROM chess_game g
JOIN chess_player w ON g.player_white = w.id
JOIN chess_player b ON g.player_black = b.id
]
2022-05-20 19:09:16.675 INFO 12120 - – [ main] com.thorben.janssen.TestQueryMethod : ChessGamePlayerNames [gameId=16, playedOn=2022-05-19T18:00, playerBlackFirstName=A better, playerBlackLastName=player, playerWhiteFirstName=Thorben, playerWhiteLastName=Janssen]
Within the log output, you’ll be able to see that Spring Knowledge JDBC solely executed the question outlined for the repository methodology. Within the earlier instance, it needed to carry out an extra question to initialize the mapped affiliation from the ChessGame to the ChessMove entities. DTOs don’t help mapped associations and, on account of that, don’t set off any extra question statements.
Conclusion
Spring Knowledge JDBC gives 2 choices to outline customized queries:
- Derived queries are an important match for all easy queries that don’t require any JOIN clauses and don’t use greater than 3 question parameters. They don’t require you to supply any customized SQL statements. You solely have to outline a technique in your repository interface that follows Spring Knowledge JDBC’s naming conference. Spring then generates the question assertion for you.
- In case your question will get extra advanced, you need to annotate your repository methodology with a @Question annotation and supply a customized SQL assertion. You need to be certain that your SQL assertion is legitimate and matches your database’s SQL dialect. Once you name the repository methodology, Spring Knowledge JDBC takes that assertion, units the offered bind parameter values, and executes it.
You should use completely different projections for each sorts of queries:
- The best one is the entity projection. Spring Knowledge JDBC then applies the mapping outlined to your entity class to every document within the consequence set. In case your entity class comprises mapped associations to different entity lessons, Spring Knowledge JDBC executes extra queries to initialize these associations.
Entity projections are an important match if you wish to change knowledge or if what you are promoting logic requires your entire mixture. - Object[]s are a hardly ever used projection that may be an excellent match for read-only operations. They allow you to solely choose the columns you want.
- DTO projections present the identical advantages as Object[] projections however utilizing them is way more comfy. That’s why they’re extra generally used and my most popular projection for read-only operations.
As you noticed within the instance, DTO projections are indepent of your aggregates and their boundaries. This lets you question the info within the format that matches what you are promoting logic.