


{kind=link}
For the previous a number of weeks, I have been attempting to repair a cranky spec in Karafka integrations suite, which in the long run, lead me to grow to be a Ruby on Rails micro-contributor and submitting related repair to a number of different high-popularity initiatives from the Ruby ecosystem. This is my story of attempting to make sense of my specs and Ruby concurrency.
Ephemeral bug from a test-suite
Karafka is a Ruby and Rails multi-threaded environment friendly Kafka processing framework. To offer dependable OSS that’s multi-threaded, I needed to have the choice to run my take a look at suite concurrently to simulate how Karafka operates. Because it was a selected use case, I created my micro-framework.
Lengthy story brief: It runs end-to-end integration specs by operating them in separate Ruby processes. Every begins Karafka, runs all of the code in numerous configurations, connects to Kafka, checks assertions, and on the finish, shuts down.
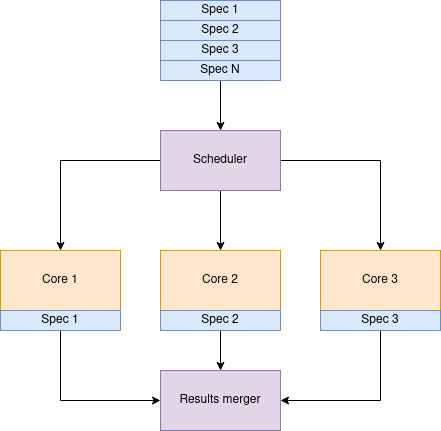
Such an strategy allowed me to make sure that the method’s entire lifecycle and its elements work as anticipated. Specs are began with supervision, so in case of any cling, will probably be killed after 5 minutes.
Karafka itself additionally has an inside shutdown supervisor. In case of a person shutdown request, if the shutdown takes longer than the outlined anticipated time, Karafka will cease regardless of having issues operating. And that is what was occurring with this single spec:
E, [2022-11-19T16:47:49.602718 #14843] ERROR -- : Forceful Karafka server cease
F, [2022-11-19T16:47:49.602825 #14843] FATAL -- : #<Karafka::Core::Monitoring::Occasion:0x0000562932d752b0 @id="error.occurred", @payload={:caller=>Karafka::Server, :error=>#<Karafka::Errors::ForcefulShutdownError: Karafka::Errors::ForcefulShutdownError>, :sort=>"app.stopping.error"}>This rattling spec didn’t need to cease!
Many issues are working beneath the hood:
- employees that course of jobs that would cling and drive the method to attend
- jobs queue that can be linked to the polling thread (to ballot extra knowledge when no work is to be finished)
- listeners that ballot knowledge from Kafka that would cling
- shopper teams with a number of threads polling Kafka knowledge which may get caught due to some underlying error
- Different bugs within the coordination of labor and states.
One factor that definitely labored was the method supervision that might forcefully kill it after 30 seconds.
Course of shutdown coordination
The sleek shutdown of such a course of takes work. When you have got many connections to Kafka, upon a poorly organized shutdown, you could set off a number of rebalances which will trigger short-lived matters assignments inflicting nothing besides friction and probably blocking the entire course of.
To mitigate this, Karafka shuts down actively and gracefully. That’s, till absolutely the finish, it claims the possession of given matters and partitions, actively ready for all the present work to be completed. This appears to be like roughly like so:
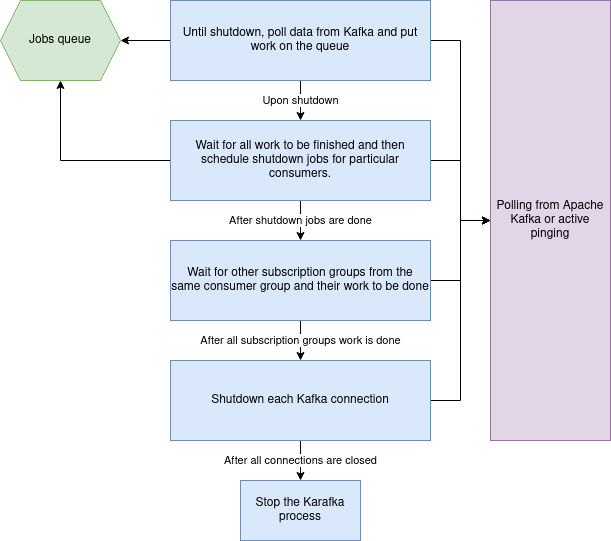
Word: Client teams internally in Karafka are a bit totally different than Kafka shopper teams. Right here we concentrate on inside Karafka ideas.
Pinpointing the problem
After a number of failed makes an attempt and fixing different bugs, I added loads of further instrumentation to verify what Karafka hangs on. It was hanging as a result of there have been hanging listener threads!
As acknowledged above, to shut Karafka gracefully, all work from the roles queue must be completed, and listeners that ballot knowledge from Kafka want to have the ability to exit the polling loops. It is all coordinated utilizing a job queue. The job queue we’re utilizing is fairly complicated with some blocking capabilities, and you may examine it right here, however the fascinating a part of the code could be lowered to this:
@semaphores = Concurrent::Map.new h[k] = Queue.new These queues are used as semaphores within the polling loops till all the present work is completed. Since every Queue is assigned to a unique subscription group inside its thread and hidden behind a concurrent map, there must be no drawback. Proper?

Replica
As soon as I had my loopy suspicion, I made a decision to cut back it all the way down to a proof of idea:
require 'concurrent-ruby'
100.instances do
ids = Set.new
semaphores = Concurrent::Hash.new h[k] = Queue.new
100.instances.map do
Thread.new do
ids << semaphores['test'].object_id
finish
finish.every(&:be a part of)
elevate "I anticipated 1 semaphore however obtained #{ids.measurement}" if ids.measurement != 1
finishas soon as executed, growth:
poc.rb:13:in `<principal>': I anticipated 1 semaphore however obtained 2 (RuntimeError)There’s multiple semaphore for one listener! This brought about Karafka to attend till compelled to cease as a result of the employee thread would use a unique semaphore than the listener thread.
However how is that even doable?
Properly, Concurrent::Hash and Concurrent::Map initialization is certainly thread-safe however not exactly as you’ll anticipate them to be. The docs state that:
This model locks towards the item itself for each methodology name, guaranteeing just one thread could be studying or writing at a time. This consists of iteration strategies like #every, which takes the lock repeatedly when studying an merchandise.
“just one thread could be studying or writing at a time”. Nonetheless, we’re doing each at totally different instances. Our code:
semaphores = Concurrent::Hash.new h[k] = Queue.new is definitely equal to:
semaphores = Concurrent::Hash.new do |h, ok|
queue = Queue.new
h[k] = queue
finishand the block content material is not locked absolutely. One threads queue can overwrite the opposite if the Ruby scheduler stops the execution within the center. This is the movement of issues occurring within the type of a diagram:
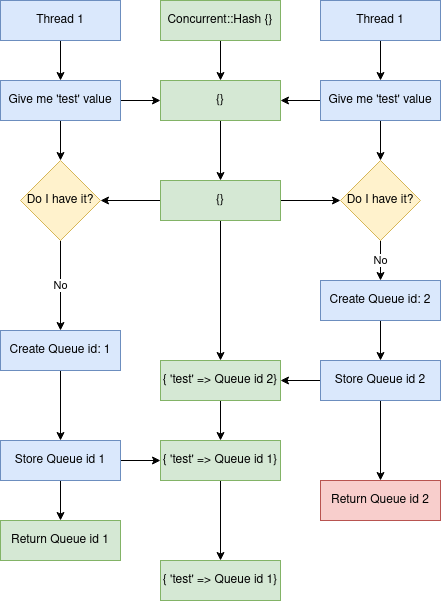
From time to time listener would obtain a dangling queue object, successfully blocking the polling course of.

Fixing the problem
This may be fastened both by changing the Concurrent::Hash with Concurrent::Map and utilizing the #compute_if_absent methodology or by introducing a lock inside the Concurrent::Hash initialization block:
Concurrent::Map.new do |ok, v|
ok.compute_if_absent(v) { [] }
finish
mutex = Mutex.new
Concurrent::Hash.new do |ok, v|
mutex.synchronize do
ok[v] = []
finish
finishOkay, however what does Ruby on Rails and different initiatives do with all of this?
Fixing the world
I found out that if I made this error, possibly others did. I made a decision to verify my native gems to search out occurrences shortly. Inside my native gem cache, I executed the next code:
fgrep -R 'Concurrent::Hash.new {' ./
fgrep -R 'Concurrent::Hash.new do' ./
fgrep -R 'Concurrent::Map.new {' ./
fgrep -R 'Concurrent::Map.new do' ./and validated that I am not an remoted case. I wasn’t alone!
Then utilizing Sourcegraph I pinpointed a number of initiatives that had the potential for fixes:
- rails (activesupport and actionview)
- i18n
- dry-schema
- finite_machine
- graphql-ruby
- rom-factory
- apache whimsy
- krane
- puppet
I’m not a website professional in any of these, and understanding the severity of every was past my time constraints, however I made a decision to provide it a shot.
Rails (ActiveSupport and ActionView)
Inside Rails, this “sample” was used twice: in ActiveSupport and ActionView.
In ActionView, it was used inside a cache:
PREFIXED_PARTIAL_NAMES = Concurrent::Map.new do |h, ok|
h[k] = Concurrent::Map.new
finishand assuming that the cached result’s stateless (identical outcome every time for a similar key), the problem might solely trigger an additional computation upon first parallel requests to this cache.
Within the case of ActiveSupport, not one of the concurrency code was wanted, so I simply changed it with a easy Hash.
Each, fortunately, weren’t that extreme, although value fixing nonetheless.
PR: https://github.com/rails/rails/pull/46536
PR: https://github.com/rails/rails/pull/46534
Each had been merged, and that is how I turned a Ruby on Rails contributor 🙂
i18n
This case was barely extra fascinating as a result of the concurrent cache shops all translations. In concept, this might trigger related leakage as in Karafka, successfully dropping a language by loading it to a unique Concurrent::Hash:
100.instances.map do
Thread.new do
I18n.backend.store_translations(rand.to_s, :foo => { :bar => 'bar', :baz => 'baz' })
finish
finish.every(&:be a part of)
I18n.available_locales.rely #=> 1This might result in hard-to-debug issues. From time to time, your system might elevate one thing like this:
:en shouldn't be a sound locale (I18n::InvalidLocale)with out an obvious motive, and this drawback would go away after a restart.
PR: https://github.com/ruby-i18n/i18n/pull/644
dry-schema
One other cache case the place the chance would revolve round double-computing.
PR: https://github.com/dry-rb/dry-schema/pull/440
rom-factory
This one is fascinating! Let’s scale back the code to a smaller POC first and see what is going to occur beneath heavy threading:
require 'singleton'
require 'concurrent-ruby'
class Sequences
embrace Singleton
attr_reader :registry
def initialize
reset
finish
def subsequent(key)
registry[key] += 1
finish
def reset
@registry = Concurrent::Map.new h, ok
self
finish
finish
seq = Sequences.occasion
loop do
100.instances.map do
Thread.new { seq.subsequent('growth') }
finish.every(&:be a part of)
measurement = seq.registry['boom']
elevate "Needed 100 however obtained #{measurement}" until measurement == 100
seq.reset
finishpoc.rb:37:in `block in <principal>': Needed 100 however obtained 1 (RuntimeError)The counter worth will get biased. What’s much more fascinating is that making the map secure will not be sufficient:
@registry = Concurrent::Map.new { |h, ok| h.compute_if_absent(ok) { 0 } }poc.rb:36:in `block in <principal>': Needed 100 however obtained 55 (RuntimeError)there’s yet another “unsafe” methodology:
def subsequent(key)
registry[key] += 1
finishthis operation additionally shouldn’t be atomic, thus must be wrapped with a mutex:
def initialize
@mutex = Mutex.new
reset
finish
def subsequent(key)
@mutex.synchronize do
registry[key] += 1
finish
finishSolely then is that this code secure for use.
https://github.com/rom-rb/rom-factory/pull/80
Different repositories
Abstract
In my view, there are a number of outcomes of this story:
- Karafka has a strong test-suite!
- If you’re doing concurrency-related work, you higher take a look at it in a multi-threaded setting and take a look at it properly.
- Concurrency is tough to many people (possibly that is as a result of we’re particular 😉 ).
- RTFM and browse it properly 🙂
- Don’t be afraid to assist others by submitting pull requests!
However, wanting on the frequency of this subject, it could be value opening a dialogue about altering this habits and making the initialization absolutely locked.
Afterwords
Concurrent::Hash beneath cRuby is only a Hash. You’ll be able to test it out right here.
Cowl picture by James Broad on Attribution-NonCommercial-ShareAlike 2.0 Generic (CC BY-NC-SA 2.0). Picture has been cropped.