


{kind=link}
Listed below are a number of the methods you may uncover your information processing jobs are too gradual:
- Jobs begin getting killed once they hit timeouts.
- Prospects begin complaining about gradual or failed jobs.
- Your cloud computing invoice is twice what it was final month.
Whereas these notification mechanisms do work, it’s most likely greatest to not depend on them.
Life is simpler when jobs end efficiently, clients are blissful, and you’ve got loads of cash left over in your finances.
Meaning you need to determine surprising slowness or excessive reminiscence utilization earlier than the scenario get that dangerous.
The earlier you may determine efficiency issues, the earlier you may repair them.
So how will you determine inefficient duties in your information pipeline or workflow?
Let’s discover out!
From “all the time gradual” to “typically gradual”
We’ll be specializing in information processing duties, typically operating as half of a bigger workflow or pipeline; this consists of information science, scientific computing, and information evaluation.
Not like an internet software these jobs might run for fairly some time, minutes and even hours.
Every job’s runtime has a specific construction:
- Load some information because the enter.
- Course of or analyze the enter ultimately, creating an output.
- Retailer the ensuing output, after which the job or activity is completed.
Whenever you first begin implementing these form of long-running duties, you may fairly assume that your code is inefficient.
So to start with, you may profile jobs at random, ideally in manufacturing, and use the profiling outcomes to determine locations the place your code is simply too gradual, or utilizing an excessive amount of reminiscence.
You repair the bottlenecks, measure once more, and iterate till finally you’ve created a sufficiently environment friendly baseline.
That is the place the scenario get extra advanced.
At this level most jobs are quick, however sometimes they’re gradual.
Maybe due to environmental causes, maybe as a result of totally different inputs give totally different habits.
Regardless of the trigger, step one to fixing the underlying drawback is figuring out the particular jobs which can be outliers: the roles which can be operating extra slowly than anticipated.
How do you determine these gradual outliers?
One method is to make use of logging, one thing you most likely need to do anyway to assist with debugging and diagnostics.
Modeling efficiency and figuring out outliers with logging
We are able to use logging to repair efficiency issues utilizing a 4 step course of:
- Add logging to your program, ideally tracing-based logging.
- Use logged data to construct a mannequin of your jobs’ pace.
- The mannequin can then provide help to determine outliers.
- Examine the outliers to determine and repair the issue.
Step 1. Add logging, which is critical however not enough
To see how logging might be helpful in figuring out excessively gradual duties, I’m going to make use of trace-based logging, tracing for brief, a superior type of logging.
Particularly I’ll be utilizing the OpenTelemetry commonplace, supported by many companies and instruments, and I’ll use the Honeycomb observability platform to visualise the info the place attainable.
In apply you need to use different companies and/or regular logging and nonetheless get comparable outcomes, with differing levels of issue.
Notice: Honeycomb is fairly good, however this use case is just not its most important focus. You probably have recommendations for tracing observability companies which can be higher designed for information processing jobs, let me know!
Let’s begin with an instance, a program that masses in a textual content file, filters out some phrases we don’t care about, after which writes out the phrases to a JSON file:
import sys
import json
def to_words(textual content):
return [word.lower() for word in text.strip().split()]
def load_filter_words(filterwords_path):
with open(filterwords_path) as f:
return to_words(f.learn())
def remove_filter_words(filter_words, countwords_path):
outcome = []
with open(countwords_path) as f:
for line in f:
for phrase in to_words(line):
if phrase not in filter_words:
outcome.append(phrase)
return outcome
def most important(filterwords_path, countwords_path, output_path):
filter_words = load_filter_words(filterwords_path)
outcome = remove_filter_words(
filter_words, countwords_path
)
with open(output_path, "w") as f:
json.dump(outcome, f)
if __name__ == "__main__":
most important(sys.argv[1], sys.argv[2], sys.argv[3])
Subsequent, let’s add some tracing with OpenTelemetry.
Not like regular logging which is a sequence of remoted occasions, OpenTelemetry traces execution utilizing spans which have a starting and finish.
Spans can have baby spans, forming a tree of spans, and spans can have hooked up attributes.
Within the OpenTelemetry API, spans might be added utilizing decorators, or with context managers:
@tracer.start_as_current_span("myspan")
def f():
# ...
def g():
with tracer.start_as_current_span("myspan2"):
# ...
Every span is routinely nested inside a mother or father span if it’s known as inside its context.
Within the following instance, discover how the totally different steps of the duty—loading, processing, and outputting information—every get their very own span.
We additionally make certain to report the enter file measurement and the variety of filter phrases as attributes.
# ...
from opentelemetry import hint
from opentelemetry.exporter.otlp.proto.http.trace_exporter import (
OTLPSpanExporter,
)
from opentelemetry.sdk.hint import TracerProvider
from opentelemetry.sdk.hint.export import BatchSpanProcessor
TRACER = hint.get_tracer("instance")
# ...
@TRACER.start_as_current_span("load_data")
def load_filter_words(filterwords_path):
# ...
@TRACER.start_as_current_span("process_data")
def remove_filter_words(filter_words, countwords_path):
# ...
def most important(filterwords_path, countwords_path, output_path):
# Initialize tracing:
supplier = TracerProvider()
processor = BatchSpanProcessor(OTLPSpanExporter())
supplier.add_span_processor(processor)
hint.set_tracer_provider(supplier)
with TRACER.start_as_current_span("most important") as span:
span.set_attribute(
"input_size", os.path.getsize(countwords_path)
)
filter_words = load_filter_words(filterwords_path)
span.set_attribute(
"filter_words_count", len(filter_words)
)
outcome = remove_filter_words(
filter_words, countwords_path
)
with TRACER.start_as_current_span("output_data"):
with open(output_path, "w") as f:
json.dump(outcome, f)
# ...
Now we will set a number of surroundings variables, and after we run the duty the hint information will get despatched to Honeycomb:
$ python v2-with-tracing.py short-filter.txt middlemarch.txt output.json
Right here’s an instance of the ensuing tree of spans for a single run, proven within the Honeycomb UI; we will see that on this instance processing the info took the majority of the time, adopted by loading the info:
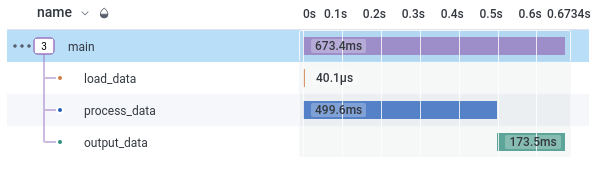
For every span, we now have a variety of attributes; these we explicitly recorded, but additionally some commonplace ones, together with how lengthy the span took to run: duration_ms.
By doing a question on HEATMAP(duration_ms) for spans whose title is "most important" (i.e. the top-level span), we will see that totally different duties took totally different quantities of time (the Y axis).
The X axis is when the duty began.
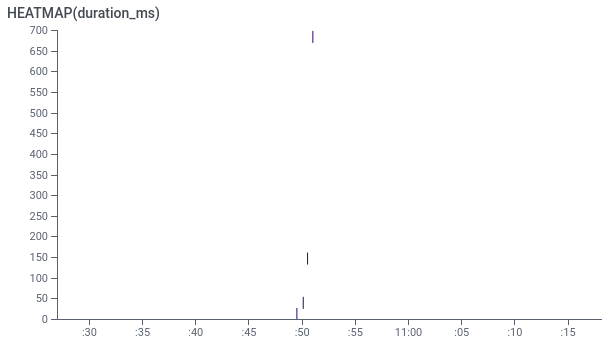
Since we need to discover gradual outliers, we need to concentrate on these duties which can be increased on the Y axis.
For instance, there’s a activity took 700ms, in comparison with the a lot quicker duties beneath which solely took as much as 150ms.
However is that this 700ms activity actually an outlier?
The issue is that the run time is partially decided by enter measurement.
In our instance, as is usually the case, the bigger enter measurement, the longer the run time.
You probably have a smaller enter, the duty will run quicker.
Right here’s AVG(duration_ms) for "most important" spans, grouped by enter measurement; you may see that the bigger the enter measurement, the longer the span’s length:

Generally you would possibly take into account that these slower duties nonetheless rely as outliers, through which case you may transfer on to step 4, fixing the issue.
However operating extra slowly on bigger output is usually anticipated, regular habits.
Meaning you desire a option to discover outliers that takes the enter measurement under consideration.
Step 2. Modeling anticipated run time primarily based on enter measurement
Since we’re logging enter measurement, we will give you a simplistic mannequin:
- The extra phrases in our textual content doc, the longer we anticipate it to run.
- We’re logging file measurement, which isn’t fairly the identical as variety of phrases, however is very correlated.
- It appears doubtless, each from our understanding of the code and from eyeballing the desk above, that run time shall be linear with variety of phrases or file measurement.
- Subsequently, we anticipate
duration_ms / input_sizeto be pretty fixed; something with a a lot increased ratio is an outlier.
Honeycomb permits you add “Derived Columns”, principally calculating a brand new attribute from current attributes.
On this case, we will add a column known as duration_to_input, outlined as DIV($duration_ms, $input_size).
Now if we construct a desk evaluating AVG(duration_to_input) towards input_size:

At this level enter measurement is just not the explanation duration_to_input varies, and the vary of values is way smaller: the largest worth is just one.5× the smallest worth, whereas beforehand we had been seeing two orders of magnitude of vary.
So this looks like an inexpensive mannequin of efficiency; not excellent, however that’s OK.
Since tiny numbers are tougher to learn, we will attempt to normalize them a bit, by dividing by the typical worth of 0.000075.
We’ll change the formulation to duration_ms / (input_size * 0.000075), or DIV($duration_ms, MUL($INPUT_SIZE, 0.000075)) in Honeycomb’s system.

Notice: If you wish to do that a bit extra systemically, you need to use SciPy to construct a extra mathematically correct mannequin.
To get the uncooked information, Honeycomb permits you to obtain question outcomes as CSV.
Step 3. Figuring out outliers
At this level we will say that if duration_to_input is round 0.7-1.3, we’re coping with a standard outcome.
If the values will get considerably increased, let’s say 1.5 or increased, we will take into account than an outlier.
Let’s have a look at an instance.
$ python v2-with-tracing.py long-filter.txt romanempire.txt output.json
If we have a look at Honeycomb, particularly at AVG(duration_to_input) grouped by hint.trace_id, so we will see particular person runs, we see that this run is way slower.
And critically, it’s a lot slower even after adjusting for enter measurement:
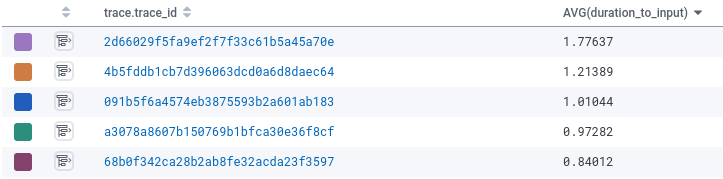
The brand new run had a ratio of 1.77, far above every other job.
We’ve discovered an outlier!
In fact, guide queries aren’t the easiest way to search out outliers.
When you’re comfy with the mannequin and have a way of what a standard vary is, you most likely need to be routinely notified each time outliers happen.
Honeycomb has a characteristic known as “Triggers” that can notify you when sure standards are met; different instruments ought to have comparable performance.
Step 4. Fixing bugs discovered through outliers and/or adjusting the mannequin
A bit extra investigation utilizing Honeycomb’s UI (utilizing the BubbleUp instrument to check outliers to baseline, or simply studying the hint attributes) reveals that this outlier has a unique variety of phrases to filter out.
Beforehand we had been utilizing 30 phrases (short-filter.txt), this time we used 174 phrases (long-filter.txt).
It appears that evidently efficiency is tied not simply to variety of phrases within the textual content doc being filtered, as we first assumed, but additionally to the variety of filter phrases.
Is that this a efficiency bug, or ought to we simply modify our mannequin to keep in mind the variety of filter phrases?
On this case, it’s most likely a bug.
Checking whether or not a string is contained in a set of different strings must be a quick, pretty fixed O(1) operation if we had been utilizing a dictionary or set.
And that implies the reason for the bug: we’re utilizing an inventory for filter_words, so each phrase lookup is O(N) as a substitute of O(1).
That’s straightforward to repair, and whereas I received’t present that right here, the result’s that every part begins operating quicker.
As soon as we implement the repair, all the roles will run quicker, so we might want to tweak the duration_to_input mannequin.
However moderately than making the mannequin extra advanced, we simply must tweak it with a unique fixed, to keep in mind the quicker baseline efficiency.
In different instances the repair could also be much less systemic, and the identical efficiency mannequin can proceed unchanged.
Diagnosing efficiency issues with profiling
On this case, the code is brief sufficient that the supply code plus tracing information is enough to determine the issue.
In actual world code, it’s typically far harder.
That is the place profiling turns out to be useful, as a complement to the data you get from logging: you actually need to have profiling on by default in manufacturing.
Given steady profiling in manufacturing, everytime you determine a gradual identifier you should have quick entry to profiling data.
For instance, the Sciagraph efficiency observability SaaS is designed particularly for Python information processing duties.
Right here’s what it reveals for this run:
It factors you instantly at if phrase not in filter_words: as the road the place more often than not is spent.
Figuring out reminiscence utilization outliers
To this point we’ve been modeling efficiency runtime.
However you may additionally need to determine jobs which can be utilizing an excessive amount of reminiscence, which may end up in swapping, or being killed by the Linux out-of-memory killer.
And which means buyer complaints, failed jobs, and doubtlessly excessive cloud prices.
To help discovering outliers with excessive reminiscence utilization, we principally comply with the very same course of, besides that as a substitute of utilizing duration_ms or another measure of elapsed time, we have to use a measure of reminiscence utilization.
There are two primary methods you may measure reminiscence, however both method we would like peak reminiscence, since that’s the bottleneck by way of {hardware} sources.
Peak resident reminiscence is obtainable use the Python useful resource module; you may then add it as an attribute to the top-level span:
from useful resource import getrusage, RUSAGE_SELF
with TRACER.start_as_current_span("most important"):
# ...
max_rss = getrusage(RUSAGE_SELF).ru_maxrss
span.add_attribute("max_rss", max_rss)
Nonetheless, as defined in additional element elsewhere, this measure is proscribed by out there RAM, and might’t get increased.
Should you solely have 8GB of RAM in your machine, you’ll by no means see greater than 8GB; a program attempting to allocate 8GB, 16GB or 32GB will report the identical max resident reminiscence, which might be deceptive.
Possibility 2: Peak allotted reminiscence
Alternatively, you may measure the height quantity of reminiscence requested by this system.
This additionally has points, for instance mmap() is barely allotted lazily and so it’s unclear whether or not it must be counted or not till its soiled.
Then again, this can inform you how a lot this system really requested for, no matter out there RAM.
Along with efficiency profiling, Sciagraph can even profile your job’s allotted reminiscence utilization, in manufacturing.
And it comes with an OpenTelemetry integration that ensures the the height allotted reminiscence measurement additionally will get recorded in your logging/tracing system.
Alternatively, when you’re doing offline profiling you need to use Fil or Memray for allotted reminiscence profiling, however they’re not designed to be on-by-default in manufacturing.
You want logging!
As we stated at the beginning of the article, you need blissful clients, and loads of cash left in your checking account.
This requires you to have sufficiently quick jobs.
Whenever you’re simply beginning out with some new code, you may merely:
- Profile the code, ideally in manufacturing.
No want to search out outliers, simply choose a job at random. - Determine the bottlenecks.
- Repair the slowness.
Ultimately, nonetheless, the traditional case shall be quick sufficient, and it would be best to determine gradual identifiers.
That is the place logging change into helpful; you most likely have already got some form of logging already, for debugging functions.
You can too use logging to report the run time efficiency of you jobs, and construct on that to determine gradual outliers.
You don’t want to make use of Honeycomb to take action, nor do it is advisable use OpenTelemetry.
I do hope sometime there shall be logging companies designed particularly for bigger scale batch jobs and information pipelines (and in the event that they do exist, please inform me!).
However even with Python’s built-in logging, logging a message on the finish of the run with the elapsed time and enter measurement is actually very straightforward.
The essential factor is that’s to have some option to question the ensuing logs and extract acceptable data.
You’ll additionally need some option to get automated notification of outliers.
Then, everytime you determine outliers, you may have a look at your logs, have a look at your profiling, and instantly begin fixing efficiency and reminiscence issues—optimistically, earlier than your clients discover.