


10 Factors about UTF-8 and UTF-16 Character Encoding
Listed below are some vital factors about Unicode, UTF-8, and UTF-16 character encoding to revise or construct your information about character encoding, how characters are saved, and how one can convert bytes to the character in your laptop program.
You need to keep in mind there are a lot of extra character encodings accessible however we now have solely targeted on UTF-8 and UTF-16 on this article as they’re probably the most elementary after ASCII, which a lot of you already know.
1. Character Set
Unicode is a personality set, which defines code factors to signify virtually each single character on the earth, together with characters from languages, foreign money symbols, and particular characters. Unicode makes use of numbers to signify these characters, often called code factors. Encoding is a solution to signify them in reminiscence or retailer it in a disk for switch and persistence.
UTF-8, UTF-16, and UTF-32 are three alternative ways to encode Unicode code factors. Right here 8, 16, and 32 signify what number of bits they use, however that is not the whole fact, which we’ll see within the subsequent level.
2. What number of Bytes it Takes
There’s a number of false impression about UTF-8 encoding amongst software program builders like UTF-8 at all times takes 1 byte to signify a personality. This isn’t true, UTF-8 is variable-length encoding and it may take wherever from 1 to 4 bytes.
In actual fact in UTF-8, each code level from 0-127 is saved in a single byte. Alternatively, UTF-16 could be both take 2 or 4 bytes, keep in mind not 3 bytes. UTF-32 encoding has a set size and at all times takes 4 bytes.

There’s one other false impression I’ve seen amongst programmers is that since UTF-8 can not signify each single Unicode character that is why we’d like larger encodings like UTF-16 and UTF-32, effectively, that is utterly improper. UTF-8 can signify each character within the Unicode character set.
The identical is true for UTF-16 and UTF-32, the distinction comes from the truth that how they signify just like the UTF-8 largely takes 1 byte however can take greater than 1, UTF-16 both takes 2 or 4 bytes, but it surely additionally suffers from endianness.
4. Backward Suitable
UTF-8 is probably the most backward-compatible character encoding, the unique purpose of it to generate the identical bytes for ASCII characters. It may be handed by many instruments meant for ASCII solely, after all with few exceptions e.g. together with avoiding composed Latin glyphs.
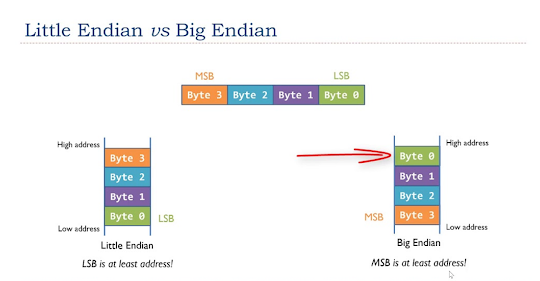
UTF-8 additionally avoids endianness issues. It doesn’t endure from endianness points like UTF-16 does, in reality, it was designed to keep away from the problems of endianness and byte order marks in UTF-16, which makes use of a few bytes at the beginning of the textual content, often called byte order marks (BOM) to signify endianness e.g. big-endian or little-endian. BOM is encoded at U+FEFF byte order mark (BOM). BOM use is elective, and, if used, ought to seem at the beginning of the textual content stream.
6. Normal
UTF-8 is the de-facto encoding for Most Mac and Linux C APIs, Java makes use of UTF-16, JavaScript additionally makes use of UTF-16. It is usually a favourite encoding of the Web, if you happen to do a right-click and view-source of an internet web page, you’ll probably see Content material-Sort: textual content/plain; charset=”UTF-8″ or.
The Web Mail Consortium (IMC) additionally recommends that every one e-mail applications be capable to show and create mail utilizing UTF-8. UTF-8 can be more and more getting used because the default character encoding in working techniques, programming languages, and numerous APIs.
Once you see a bunch of query marks in your String, assume twice, you is perhaps utilizing the improper encoding. There are many standard encoding which might solely retailer some code factors appropriately and alter all the opposite code factors into query marks. For instance, Home windows-1252 and ISO-8859-1 are two standard encodings for English textual content, however if you happen to attempt to retailer Russian or Hebrew letters in these encodings, you will note a bunch of query marks.
UTF-8 could be very space-efficient. It typically finally ends up utilizing fewer bytes to signify the identical string than UTF-16, until you are utilizing sure characters quite a bit (like for European languages), however, UTF-32 at all times makes use of 4 bytes, so it takes more room to signify the identical String.

UTF-8 encodes every of the 1,112,064 code factors from the Unicode character set utilizing one to 4 8-bit bytes (a gaggle of 8 bits is named an “octet” within the Unicode Normal). Code factors with decrease numerical values i.e. earlier code positions within the Unicode character set, which are inclined to happen extra incessantly are encoded utilizing fewer bytes.
That is all about issues each programmer ought to find out about UTF-8 and UTF-16 encoding. Character encoding is likely one of the elementary subjects which each and every programmer ought to examine and having a very good information of how characters are represented and the way they’re saved is important to create world functions which might work in a number of languages and might retailer information from around the globe.
Thanks for studying this text thus far. If you happen to like this text and my rationalization then please share it with your folks and colleagues. In case you have any questions or suggestions then please drop a be aware.